RE: C.A.I.M.E.O. 2048 : The Movie #CICADA3301 #QANON #ARM$ #LEGG$ #ALIENS #SPACE #HACKERS #CHRISTMAS #SPECIAL
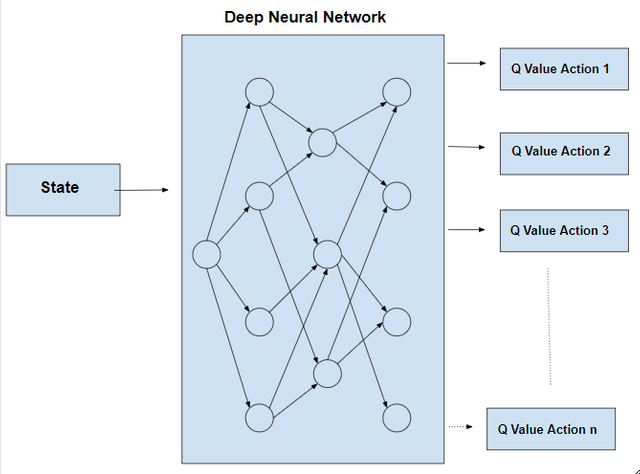
Q-Learning creates an exact matrix for the working agent which it can “refer to” to maximize its reward in the long run. Although this approach is not wrong in itself, this is only practical for very small environments and quickly loses it’s feasibility when the number of states and actions in the environment increases. The solution for the above problem comes from the realization that the values in the matrix only have relative importance like the values only have importance with respect to the other values. Thus, this thinking leads us to Deep Q-Learning which uses a deep neural network to approximate the values. This approximation of values does not hurt as long as the relative importance is preserved.

GPT-2 was trained simply to predict the next word in 40GB of Internet text. Due to our concerns about malicious applications of the technology, we are not releasing the trained model. As an experiment in responsible disclosure, we are instead releasing a much smaller model for researchers to experiment with, as well as a technical paper. GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset. We created a new dataset which emphasizes diversity of content, by scraping content from the Internet. In order to preserve document quality, we used only pages which have been curated and filtered by humans specifically, we used outbound links from Reddit which received at least 3 karma. This can be thought of as a heuristic indicator for whether other users found the link interesting, leading to higher data quality than other similar datasets, such as CommonCrawl of 8 million web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than 10X the amount of data.