Closures in programming: What are they and how do they work?
Any avid programmer would likely have heard the term “closure” a handful of times, though many newcomers may struggle trying to understand how they work, or even what they are. Let's take a look at a definition taken from Wikipedia:
In programming languages, closures (also lexical closures or function closures) are techniques for implementing lexically scoped name binding in languages with first-class functions.
That’s, well, not very intuitive. To be fair, closures aren’t an incredibly intuitive thing when you define them like that. I’m certain, however, that though breaking this definition down things will become much clearer. Let’s take a look:
Lexical scoping
This can actually be broken down even further. First of all, “scoping”. Most programmers should be familiar with scoping. A block of code, usually wrapped in curly braces, is “scoped” in some sense.
# pseudocode
variable num = 1 # x is in the global scope
function add_one(x) {
variable sum = x + num # sum is local to the "add_one" function
return sum
}
print(num) # Prints the number 1
print(sum) # Prints a reference error
In that pseudocode example, we declare two variables: num and sum. The variable num is in the global scope, meaning that it can be retrieved anywhere, including from within the function add_one. The sum variable, however, is not global and can only be accessed from within the function.
In this case, of course, the sum is being returned from the function so if we were to later assign the value returned by the function to a new variable binding we technically could access its contents.
# pseudocode
print(sum) // ReferenceError: sum is not define
print(add_one(3)); // 4
That's enough about scoping. How about a lexical scoping? On its own, the word lexicon really has no significance to computer science. A lexicon is like a dictionary or a list of vocabulary. That's where you start to see the analogy.
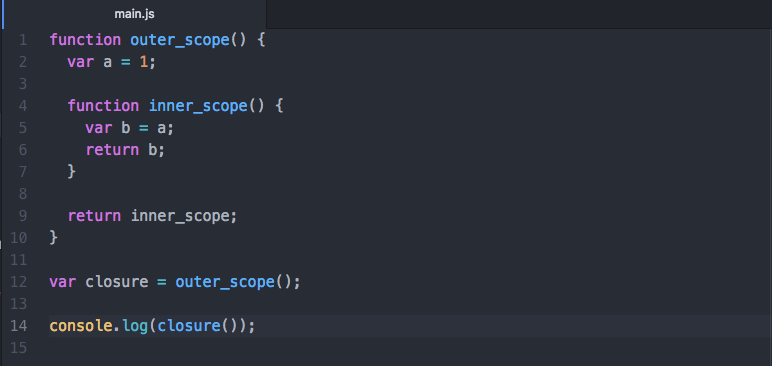
Now, the idea behind lexical scoping is that every inner scope has access to the values that exist in the outer scope. For an example,
# pseudocode
function outer() {
# Outer block of code
variable a = "Hello, World!"
function inner() {
# Inner block of code
variable b = a
}
}
Here, we have one function wrapped in another. In the outer block, we define a variable called a and assign it the value "Hello, World!". Thanks to lexical scoping, the interpreter or compiler allows us to assign the value of the variable a to our new variable b.
To put it in the most simple form possible, with lexical scoping, the inner function contains the scope of the outer function. So, when you're nesting functions, the function on the inside has access to all the values defined on the outside.
What must be the most common use case for nesting functions is returning them. We refer to functions that are treated like values as they are in functional languages as first-class functions.
First-class functions
Functional programmers will definitely know about the concept of first-class functions. To put it simply, a first-class function is one that is treated as a first-class citizen. If a language supports first-class functions, then they can be assigned to variables and passed to other functions.
A function that accepts other functions as arguments is referred to as a high-order function. For a function to be considered high-order, it should meet at least one of these two requirements:
- The function takes at least one other function as an argument.
- The function returns another function defined from within the function.
Here's an example:
#pseudocode
function create_increaser(by) {
function increaser(inc) {
return inc + by
}
return increaser
}
variable increment_by_one = create_increaser(1)
variable increment_by_two = create_increaser(2)
increment_by_one(5) // 6
increment_by_two(5) // 7
Here, a function called create_increaser takes one argument and returns another function. We can assign the returned function to a variable as demonstrated in the example. We can then pass a number to that function and have it incremented by however much we decided earlier.
This is a pretty simple example, but it gets the point across.
So now that we know what lexical scoping is and we understand first class functions, how does any of this relate to closures?
Finally, closures.
Let's revisit our last example. This time, using Javascript:
// javascript
function create_increaser(by) {
function increaser(inc) {
return inc + by;
}
return increaser;
}
By our understanding of memory management, once the interpreter reaches the end of the scope, in theory, all of the variable bindings should be picked up by the garbage collector. Try looking a little bit closer. At the start of this function, we get a number bound to this binding called by representing by how much the "increaser" should increment each number.
As we understand scoping, this binding should be eliminated after the function has run. Yet lo and behold:
// javascript
// The binding 'by' comes into scope and then falls out
var increment_by_one = create_increaser(1);
// We increment the number 2 by the value that shouldn't exist anymore
console.log(increment_by_one(2));
We can still use it. How do we still have access to this value if it shouldn't exist?
This is because in Javascript, all function are closures: a sort of function that "captures" it's lexical scope. If you're using a language that supports closures, you have the power to hang on to scopes after the block has finished executing. In other words, using this pattern, we can still access values created in functions even after they've been run.
A practical use case
Alright, so that's all great, but are there any practical use cases for this concept?
Here's an example I find particularly useful in Python
# python
import os
dir1 = "Document"
sub_dir = "work"
project_folder_one = "project1"
project_folder_two = "project2"
with open(os.path.join(dir1, sub_dir, project_folder_one, "file.txt"), "w") as f:
f.write("Hello, World!")
with open(os.path.join(dir1, sub_dir, project_folder_two, "file.txt"), "w") as f:
f.write("Hello, World!")
So here, I have the path Documents/work broken down into variables before using it multiple times with os.path.join, a function used to join path components in an OS-independent way.
When my project starts getting more complex and I need to use that path more often, things get out of hand. Of course, thanks to closures, I can do something like this:
# python
def relative(origin):
def joined (*to):
path = origin
for t in to:
path = os.path.join(path, t)
return path
return joined
from_work = relative(os.path.join("Documents", "work"))
with open(from_work("project1", "file.txt"), "w") as f:
f.write("Hello, World!")
with open(from_work("project1", "build", "file.txt"), "w") as f:
f.write("Hello, World!")
See? Much more efficient. Maybe this specific use case isn't extremely useful to everyone but I think it demonstrates how much of an impact closures can have on one's project.
Further reading
- Closures - JavaScript | MDN
- functional programming - What is a 'Closure'? - Stack Overflow
- Lexical scoping on Wikipedia
Agree or disagree? Think I missed or poorly explained something important? Questions, comments or concerns? Leave a comment down below!
I think this is the clearest explanation of closures I've ever read. Thanks.
I'm happy you found it useful!
cool tut
Oh! That's what a closure is!
I've been using them without knowing what they were called.