B-tree에 대하여
B-트리(B-tree)에 대해 공부한 후 문서로 남깁니다.
B트리에 대해 자세히 알아본 계기는 인턴 과정 중이었습니다. 아마 데이터베이스와 파일 시스템에서 널리 사용되기 때문인 것 같습니다. 이진 트리를 확장한 트리인데, (그러나 B-트리는 이진 트리가 아닙니다!) 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조입니다.
B트리 쓰임새
디스크 I/O의 기본 단위는 블록입니다. 디스크로부터 데이터를 읽거나 기록할 때 이를 포함하는 디스크 블록 전체를 메모리로 읽어오고 다시 블록 전체를 디스크에 기록하는 방식으로 디스크 I/O가 일어납니다. 디스크에 접근하기 위한 시간은 다음과 같이 구할 수 있습니다.
Access time = seek time + latency + transfer time;
- seek time : 디스크 헤드를 정확한 트랙 위로 이동시키는 시간
- latency : 디스크를 회전시켜 해당 블록이 디스크 헤드 아래로 오게 하는 시간 (전체 접근 시간의 50%정도 차지)
- transfer time : 디스크 블록을 메모리로 전송하는 시간
디스크 접근 시간 단위는 milli-second 단위인데, CPU로의 접근 시간은 mirco-second나 nano-second 단위입니다. 즉 디스크보다 CPU가 적어도 약 1000배~1000000배 정도 빠릅니다. 이렇게 느린 디스크 I/O를 수행하기 위해서는 색인(index) 구조가 필요합니다. 색인에 주로 쓰이는 것이 바로 이 B-Tree 형제들(B*트리, B+트리, R트리...)이죠.
디스크에 접근하는 것은 메인 메모리의 접근에 비해 엄청난 시간이 듭니다. 이 블록을 보통 소프트웨어에서 페이지 라고하는데요, 검색트리가 방대하면 메모리에 모두 올려놓고 사용할 수 없습니다. 결국 검색트리가 디스크에 있는 상태에서 작업을 해야하는 상황이 발생합니다. cpu가 디스크에 접근을 해서 작업해야 한다는 소리입니다.
방대한 양의 저장된 자료를 검색해야 하는 경우 검색어와 자료를 일일이 비교하는 방식은 비효율적일 것입니다. B-트리는 자료를 정렬된 상태로 보관하고, 삽입 및 삭제를 대수 시간으로 할 수 있게 하는 방법입니다. 대부분의 이진 트리는 항목이 삽입될 때 하향식으로 구성되는 데 반해 B-트리는 일반적으로 상향식으로 구성됩니다. 이진 트리의 결정적인 단점은 하나의 부모가 두 개의 자녀밖에 가지지 못한다는 점입니다.이렇게 되면 트리의 높이가 높아지게 됩니다. 트리의 성능은 트리의 높이에 달려있기에 성능 저하를 불러올 수 있습니다. 따라서 대용량 데이터를 처리할 수 없게 됩니다. 즉 검색 효율이 트리의 균형에 의존적이라서 최악의 경우, 시간복잡도가 선형이 되어버릴 수 있습니다. 이런 경우는 아마 자식 노드들이 모두 오른쪽으로 쏠린 경우일 것입니다. 이를 피하기 위해선 이진트리의 균형을 자동적으로 맞춰줄 수 있는 로직이 필요합니다. 이렇게 어렵게 이진트리를 쓸 바에야, 그냥 B-tree 를 쓰는 것이 더 나을 것입니다.
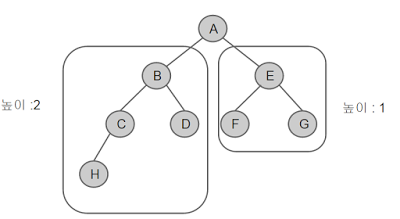
위 트리는 왼쪽보다는 오른쪽이 더 균형적이라고 할 수 있습니다. 양팔 저울을 생각하면 편합니다.
(참고로 이진트리에서 높이가 1차이 나는 것은 균형에 있어서 허용범위라고 할 수 있습니다.)
이진트리의 이러한 단점을 보완한 것이 바로 B-트리입니다.
B-트리는 이진 트리에서 확장되어 부모가 더 많은 수의 자식을 가질 수 있게 됩니다. M개의 자식을 가질 수 있도록 설계된 경우, M차 B-트리라고 합니다. 하나의 레벨에 많은 자료가 저장되기 때문에 전체적으로 트리의 높이가 줄어들게 됩니다. 트리의 높이가 줄어든다는 것은 곧 트리의 성능이 높아진다는 것을 의미합니다.(log단위로 성능의 단위가 붙습니다.) 또한 이런식으로 구성된 트리는 always 균형 잡힌 트리, always Balanced Tree 가 되어 검색에서든, 삽입에서든, 삭제에서든 항상 O(logN)의 성능을 보장합니다! B-tree에게 최악의 경우란 존재하지 않는다는군요..
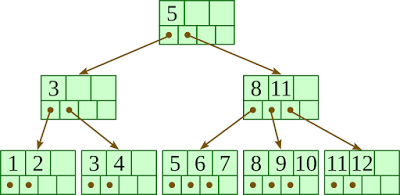
이 트리는 3차 B-트리입니다. 3차라고 해서 항상 3개의 자료가 들어가야만 하는 것은 아닌 것을 볼 수 있습니다. 그저 3개의 자리가 있을 뿐입니다. 현재 이 트리에선 4개의 자식 노드를 가질 수 있는 것으로 보이는군요.
게다가 B-트리는 트리의 균형을 자동으로 맞추는 로직도 갖추었습니다. 이 로직은 단순하고 효율적입니다.
하나의 노드에 이렇게 많은 데이터를 가질 수 있다는 것은 대량의 데이터 처리가 필요한 검색 구조에 큰 장점이 됩니다. 대량의 데이터는 주로 외부 기억 장치에 저장되는데, 외부 기억 장치들은 블럭 단위로 입출력이 일어납니다. 즉 한 블럭이 1024바이트라면 2바이트를 읽어오기 위해서도 1024바이트를, 1000바이트를 읽어오기 위해서도 동일하게 1024바이트를 입출력 비용으로 지불합니다. B-트리는 하나의 노드를 한 블럭 크기 정도로 조절함과 동시에 트리의 균형도 맞춘 로직을 이미 갖추었기에 데이터베이스 시스템의 인덱스 저장 방식으로 유용하게 쓰입니다. 로직에 대해서는 아래에서 다룹니다.
이렇게 각 내부 노드에 있는 자식 노드의 수를 최대화함으로써, 트리의 높이는 감소시키고, 트리의 불균형은 덜 일어나게 되며고, 데이터베이스 내에서의 검색효율은 증가하게 됩니다.
B-트리의 규칙
- 한 노드의 자료수가 N이라면, 그 노드의 자식의 갯수는 반드시 N+1이어야 합니다. 위의 그래프에서 3개의 자료수를 갖는 트리가 4개의 자식노드를 갖는 이유를 이제 아시겠죠? 이것이 B트리의 정의입니다. 이래야 B-트리입니다. 이를 만족하지 않으면 B-tree가 아닙니다.
- 모든 노드들은 부모 노드의 자료의 크기에 의존적으로 정렬됩니다. 즉 모든 자료엔 크기와 순서가 부여됩니다.
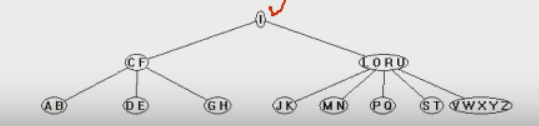
자료수값이 2인 CF를 '자료'로 가지는 노드의 자식 노드들은 '자료수N+1'인 3개의 노드입니다. C보다 작은 AB, C와 F사이인 DE, F보다 큰 GH로 나누어져 있습니다. 이는 부모노드인 CF에 의존적으로 자식노드들의 자료값이 결정된다는 것을 의미합니다.
- 루트노드를 제외한 모든 노드는 적어도 (차수(M)/2)(소수점이 발생 시엔 내림을 적용.)개의 자료를 가지고 있어야 합니다.
- 입력 자료는 중복될 수 없습니다.
모든 자료엔 크기와 순서가 부여되기 때문에 중복될 경우엔 결국 트리의 균형을 유지할 수 없게 됩니다.
이렇게 함으로써 자료수는 틀릴 순 있어도 B-트리는 완전 균형 트리의 상태를 항상 유지합니다. 성능 보장이 O(logN)으로 보장된다는 것이죠. 그러므로 외부노드(leaf node)로 가는 경로의 길이는 모두 같습니다. 다시 말해, 모든 외부노드까지의 레벨은 동일 합니다.
참고로 B-tree 알고리즘을 구현하는 것은 차수에 따라 난이도가 달라집니다. 홀수차인 경우를 가정한 아래의 강의가 도움이 될 것입니다. (참고로 짝수차는 구현이 어렵다고 하네요.)
B-트리의 골격과 구현 동영상 강의
검색 알고리즘
삽입 알고리즘
삭제 알고리즘
B-트리의 창시자인 루돌프 바이어는 'B'가 무엇을 의미하는지 따로 언급하지는 않았습니다. 가장 가능성 있는 대답은 리프 노드를 같은 높이에서 유지시켜주므로 균형잡혀있다(balanced)는 뜻에서의 'B'라고 하네요.
보면 알겠지만, 10차 B-tree일 경우 10개의 자료가 모두 들어갈 필요는 없습니다. 이 소리는 곧 어느 정도의 공간낭비를 감수한다는 걸로 보입니다.
일반적으로 보조 기억 장치에서의 탐색은 시간적인 부하가 많이 걸리기 때문에 탐색을 쉽게 하기 위해 file과는 별도로 index를 만들어 사용합니다. Index가 커질 경우, index 역시 보조 기억 장치에 저장하게 되는데 보조 기억 장치는 상대적으로 느리죠. 따라서 보조 기억 장치의 access 횟수를 최대한 억제시키는 게 성능 향상에 좋습니다. Index로의 access 횟수를 줄이기 위해서는 최대 탐색 길이 즉, 트리의 높이를 줄여야 합니다. 높이를 낮추기 위해서는 하나의 노드에서 나가는 branch의 개수를 증가시키면 됩니다.
각 node는 최대 m개, 최소 (m/2)개의 서브트리를 가져야 합니다. 이 조건에 의해 트리의 각 노드가 적어도 반 이상은 key값으로 채워져 있도록 해야합니다. 이로써 서브트리가 없는 노드가 발생하지 않습니다.
B tree example
Hi! I am a robot. I just upvoted you! I found similar content that readers might be interested in:
https://tfedohk.github.io/algorithms/2016/01/05/b-tree.html
Congratulations @soladola! You received a personal award!
Click here to view your Board
Congratulations @soladola! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!