Building a 50 Teraflops AMD Vega Deep Learning Box for Under $3K

In 2002, the fastest supercomputer in the world (i.e. “NEC Earth Simulator) was capable of 35.86 teraflops.
What 35.86 teraflops looked like in 2002. Wikipedia
You can now get that kind of computational power (that can fit under your desk) for the price of a first class airline ticket to Europe.
Now that AMD has released a new breed of CPU (i.e. Ryzen) and GPU (i.e. Vega) it is high-time that somebody conjure up with an article that shows how to build an Deep Learning box using mostly AMD components. The box that we are assembling will be capable of 50 teraflops (fp16 or half precision).
Here are the parts we gathered together to put together this little monster. I purchased them through Newegg and you can click on the links for the specific parts.
Part List:
2 — AMD Radeon Vega Frontier Edition 16GB GPU $2,000
1 — G.SKILL 32GB (2 x 16GB) DDR4 Memory $200.99
1 — Crucial 525GB SATA III 3-D SSD $159.99
1 — EVGA Plus 1000W Gold Power Supply $119.99
1 —MSI X370 AM4 AMD Motherboard $129.99
1 —AMD RYZEN 7 1700 8-Core 3.0 GHz (3.7 GHz Turbo)Processor $314.99
1 — TOSHIBA 5TB 7200 RPM SATA Hard Drive $146.99
1 — Rosewill ATX Mid Tower Case $49
Total: $3,122 or $62/teraflop.
My mistake, I went over budget! It would have been under $3,000 if I didn’t need either the SSD or the HDD. But if you want to pay a little more for additional hardware then I would add more CPU memory (up to 64GB) and to use an NVMe based SSD card. That would add an additional $600 to the total. For comparison with a desktop solution, Nvidia’s pre-assembled “DIGITS Devbox” with 4 Titan X GPUs and 64GB ram goes for $15,000.
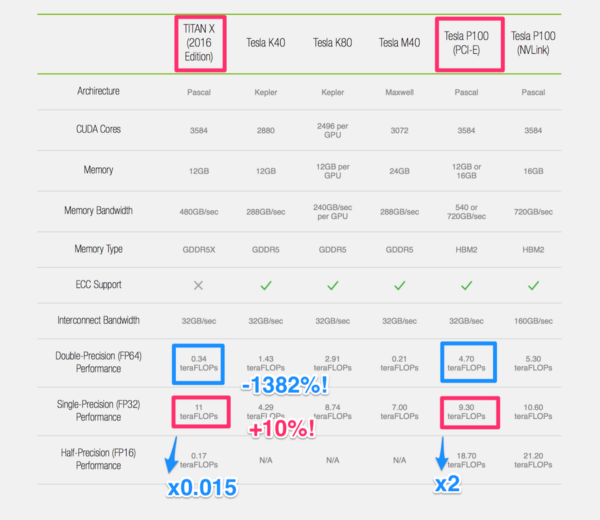
One other perspective is to compare it with a single Nvidia Tesla P100 (just the GPU card) with 16GB and capable of 18.7 teraflops (fp16) but costs $12,599 from Dell. If you are thinking of side-stepping ‘professional grade’ to a consumer grade Nvidia Titan X or GTX 1080 ti (like the DIGITS Devbox) then it is worth knowing that half-precision (fp16) is only at 0.17 teraflops for a Titan X and comparable for a GTX 1080 ti. That’s because fp16 as well as fp64 (double precision) is crippled for Nvidia consumer cards ( is it crippled or simply not capable?):
Source: Quora
Clearly you are getting a ridiculous amount of fp16 compute for the buck with a Vega solution! Deep Learning does not require high precision unlike conventional scientific computation. So we can ignore double-precision floating point performance numbers when we select Deep Learning hardware. In the old days, Nvdia charged premium for their Tesla double precision capability. Scientific computing absolutely required double precision and thus paid premium for this capability. However with the discovery that Deep Learning workloads don’t need high precision and favor a lot more computation, Nvidia is now also charging premium for half-precision! Kind of like giving you half the cake for twice the price. That’s the benefits of being in the driver’s seat!
Perhaps AMD Vega can take a piece of the action with better fp16 performance:
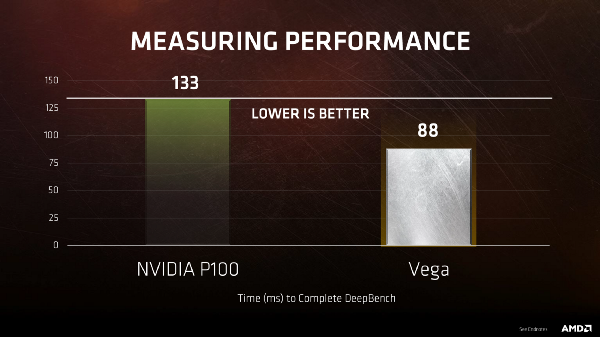
Nvidia P100 vs Vega
We can also make comparisons with respect to cloud based GPUs. A p2.xlarge is priced today at $0.9 per Hour using K80 GPUs. A p2.xlarge specifications is at 2,496 CUDA cores with 12GB of memory. If we do the math this appears to be at 4.3 teraflops per GPU instance (single precision). That is 5.8 times less than this AMD box we are assembling. In terms of money, you will spend at a maximum 24 days of AWS GPU time to cover the cost of this AMD box! (To be fair, we are comparing oranges with oranges, that is numbers are on single precision compute).
There are of course a lot of other considerations that need to be taken into account here. The cost of assembly, installing, networking, power and maintenance that we did not add. Also, there are considerations to be made if the need arises in distributing work across more than one machine (which its always best to avoid). Finally there is the issue of Deep Learning frameworks that are compatible with the AMD box. Still, it is hard to ignore the massive potential cost savings of this approach.
The AMD Ryzen CPU has an interesting feature in that it can handle 24 PCIe lanes, in comparison an Intel desktop CPU has only 16 lanes. This is an important consideration in that you need to be able to adequately feed the attached GPUs with data fast enough while it is training. Each GPU can occupy 16 lanes, so perhaps a more optimal solution is to wait for AMD’s Threadripper ( i.e. on store shelves in early August ) that supports 64 lanes! Threadripper is definitely something to check out with a box with four Vega GPUs (meaning 100 teraflops). I likely will like explore this new CPU to see how it performs with multiple GPU and NVMe devices. In addition, Vega is uniquely designed memory architecture that lets it access 512TB of memory. Coupling Vega to NVMe devices may lead to unprecedented performance improvements.
Okay, let’s get assembling! Here are the unboxed parts:

Unboxed and ready for assembly. Just need to find some screws.
All one needs is a screwdriver and mounting screws. With about the same amount of brain power and time to assemble Ikea furniture and you have a final assembly that’ll look like this:

Hard to believe that this is 50 Teraflops!
It isn’t one of those gorgeous water cooled and color coded assemblies, but this should be more than adequate. (Note: AMD sells a water-cooled version of Vega). To my surprise, the LEDs were horribly color uncoordinated. I have white, red, blue and yellow. I guess you will have to pay premium for style (strike last sentence, apparently you can change the colors!!).
We’ll install Ubuntu 16.04 and install the AMD ROCm software.
To do this, go to www.ubuntu.com and download an iso image that you will ‘flash’ into a flash drive. You can do this all using Unetbootin. Once done downloading and flashing, insert the flash drive into the USB port of the new desktop and it’ll boot up Ubuntu and guides you towards installing the operating system on to the attached HDD or SSD.
Once Ubuntu is installed, you now need to install drivers and software for the Vega cards. You can find instructions to that here: installing ROCm.
You will only need to install the AMD ROCk drivers. Everything else sits in userspace and what we’ve done is set up a Docker image so that you can easily run some AMD Deep Learning experiments.
You therefore need to install Docker. To do this, just follow the instructions found here: (How to install Docker in Ubuntu 16.04).
Once you have set up Docker, you can now start exploring Deep Learning on AMD hardware. Just a quick summary, install the Ubuntu operating system, install the AMD kernel drivers and then install Docker. It isn’t very complicated at all!
The Docker image we have, we have made public at Docker Hub: https://hub.docker.com/r/intuitionmachine/hip-caffe-amd/. This we hope will allow you to start experimenting quickly.
So by typing the following command line:
sudo docker run -it --device=/dev/kfd — rm intuitionmachine/hip-caffe-amd:latest
you will be in business. We plan on having more feature rich docker images in the future.
So let’s get some numbers to see how well this box performs!
Baidu has a suite of Deep Learning benchmarks ( see: https://github.com/baidu-research/DeepBench ) that AMD has ported.
In conclusion, AMD still needs a lot of catching up to do in the Deep Learning software front, however it is indeed clear that for folks with a budget that there are opportunities here that can be exploited. If AMD can get more frameworks ported and working with fp16, then that will be a major win for the competitiveness of this alternative platform.
For researchers who perform experiments on low precision arithmetic or compressed networks, this is an opportunity to get a fp16 enabled system at an extremely low cost. AMD’s Vega solution appeals to the idea that emergent intelligence arises from having more simple computations performed at a massive scale. The fp16 capability and the large 16GB of HBM2 memory can be an advantage for certain kinds of innovative architectures. Consider also that Vega can directly access NVMe devices and can address a 512TB of memory. This can be huge in the context of the newer 3D XPoint technology that Micron and Intel have created. Vega GPUs that can access terabytes of memory have the potential to change the entire dynamics of Deep Learning architectures.
Looking forward in the future, Nvidia’s Volta architecture has specialized Deep Learning GPUS (see: Google’s AI Processor’s (TPU) Heart Throbbing Inspiration) that are not yet in AMD’s roadmap. It is unclear though whether these capabilities will also be available to Nvidia consumer graphics cards. So it may be safe to assume that, at a hobbyist level, AMD GPUs can become an extremely promising Deep Learning platform in the next couple of years. One thing to always remember, Deep Learning is an experimental science and the more folks that have 50 teraflops of computing power underneath their desks, the higher the likelihood that we make some accidental impressive discoveries!
Originally posted here: https://medium.com/intuitionmachine/building-a-50-teraflops-amd-vega-deep-learning-box-for-under-3k-ebdd60d4a93c
@intuitionfabric
Great effort put up here!
Keep sharing.