POD evicted and unable to be launched again!
Briefing
When we did the regular check on our official EOS node on the main-net, we found that one full node was evicted and can't be launched again. Obviously, the node was shut down and not working.
Symptom
Status of the Pod
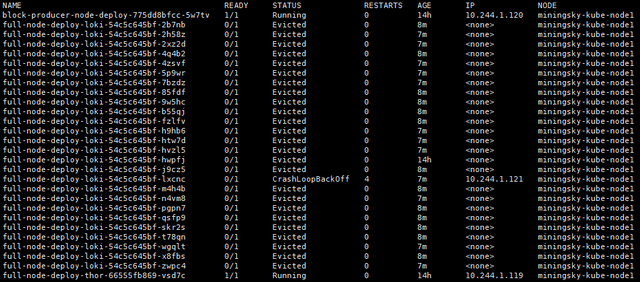
kubectl get po -owide
kubectl describe pod <pod-name>

We found one funny factor that -
0/2 nodes are available: 1 node(s) had disk pressure, 1 node(s) had taints that the pod didn't tolerate.
Note: EOS9CAT currently has 1 x master node (pod not tolerated) + 1 x worker node.
Reason
The
kubeletneeds to preserve node stability when available compute resources are low. This is especially important when dealing with incompressible compute resources, such as memory or disk space. If such resources are exhausted, nodes become unstable.
Running 2 x full nodes + 1 bp node on one server seems that exhausted the disk I/O (SSD already).
In terms of EOS9CAT monitoring, after the EOS main-net was officially launched for more than 1 month, more and more transactions are being made into the blocks.
Currently, the nodes require very high network bandwidth and disk I/O than we expected before the EOS launching day.
Workaround
Enable the master node to hold the pods
Reference: Creating a single master cluster with kubeadm - Master Isolation
kubectl taint nodes --all node-role.kubernetes.io/master-Re-configure the Persistent Volume for the master node
Change the nfs server address to be same with the master node
nfs: # FIXME: use the right IP server: <nfs server ip address> path: "path/to/folder"kubectl create -f <pv.yaml>
Transfer the snapshot to the master node
- stop the running node
- copy all the
blocks/andstate/to the node's folder which is located in the master node
Label each nodes and add the
nodeSelectorinto the pod yaml fileReference: Assign Pods to Nodes
kubectl label nodes <your-master-name> role=masterkubectl label nodes <your-node1-name> role=node1Add the
{.spec.nodeSelector}into the deployment yaml filenodeSelector: role: master
Deploy the
deploymentin the Kubernetes

6.Now the I/O chart from each node after the change.
- master node

- node1 node

Conclusion
- Fully utilize the resource of the bare metal could give us more stabilities.
- A good PV (PersistentVolume) design could promote the whole performance of the pod fail-over.
- EOS synchronization requires robust network bandwidth and the disk I/O, especially several nodes are sharing the resource of one bare metal server.
Contact/About us
If you are an advanced blockchain user, feel free to use any of those tools that you are comfortable with.
If you like what we do and believe in EOS9CAT, vote for eosninecatbp! Waiting for your support. Have a question, send an email to us or visit our website.
FOLLOW US on Facebook, Telegram, Medium, SteemIt, Github, Meetup E0S9CAT, Reddit, Twitter, and LinkedIn.