Cryptocurrency: Scaling Ethereum to 1.5 million TPS
Transactions Per Second, the thing we are all so focused on right now. In this article I am going to take a new installation of Ethereum and see just how high I can scale it.
The point here is to illustrate a few things, what are the boundaries of a system like Ethereum, how is scaling impacted by the enrivonment, and what are the different definitions of TPS.
So we boot up a new EC2 medium from AWS, we pull the latest go-ethereum repo (hereafter referred to as Geth) and we build.
Test 1: Single node, self mining, full mempool
So this is very much a centralized perfect condition test. We control the hardware, we control the mempool, and we control the mining. There is no network broadcasting, we are essentially using Geth as a centralized immutable concatenated list.
Test 1.1: 10 transactions

We do 10 transactions, and we see it took 2 seconds to mine. That’s horrible, 5 TPS.
Test 1.2: 1000 transactions - PoW difficulty

Interesting, 8 seconds, so 125 TPS. But this is base Geth, how is that possible when normal Ethereum doesn’t have that high of a throughput. So the thing to note here is difficulty, Ethereum core takes roughly 13-15 seconds to mine a block, so it’s TPS will always be block capacity (which is mutable) / 13-15 seconds. In our setup, we are using a difficulty of 1, which means blocks can be mined essentially as fast as they can be created.
Test 1.3 10k transactions - mempool

1 second, so that’s 10k TPS with an out of the box installation of Geth with all transactions already in the mempool. So often TPS is referred to as “How many transactions in a block, and how long did the block take to make, seal, and mine”, but this doesn’t take something like network traffic into consideration. I could get this number to 500k if the mempool and cpu allowed for it (which is where we will get to with controlled hardware later)
Test 1.4 100k transactions
So here we started facing our first problem, the problem wasn’t actually so much Ethereum as web3.js, for whatever reason I could not get native web3.js to scale to more than 500 TPS

Once the transactions where in mempool we had no issues, as you can see 1k TPS, and even 7k TPS, but I wanted to not have the streaming limit of 500 TPS



At this point the bottle neck is actually sending transactions, so let’s change from our for to a map.

Even with a map still pretty slow
Made the calls 100% asynchronous, much better, so now let’s up the game.
I still want this faster, so we can set up parallel processes, but for now let’s see how the mining is doing;

No issues, so let’s put no limit on this thing and see.

At this point we started overwhelming the actual underlying open file limitations, this was the default of 1024 (this is how many open sockets are connected via web3.js and Ethereum, curious that they don’t re-use an open socket, but I’ll address that later)


So now we have a new max hardlimit of 65535, technically this is caused because the connection socket is not being re-used, the better implementation would be to actually simply rework web3 to not close the socket. I’ll look into this after these tests since I do want something stable I can use in the future.
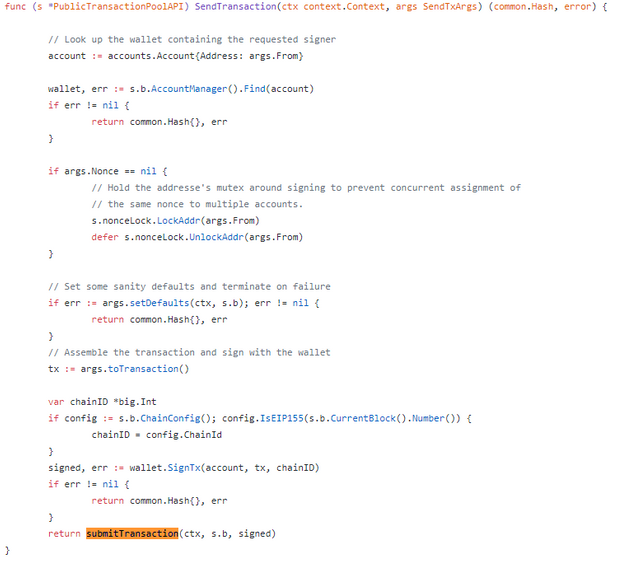
So what is important here from a TPS perspective? Most of our time is actually spent around doing a bunch of validation and transaction signing, so what if we can skip that part and instead do it client side or simply ignore it?
So we can’t just cleanly get away from SignTx, since each transaction is unique (thanks to the nonce that increments) so we have to get rid of nonce or at least the nonce check. So why do we check nonce? This is part of the replay attack protection on a very basic level. So let’s start modifying
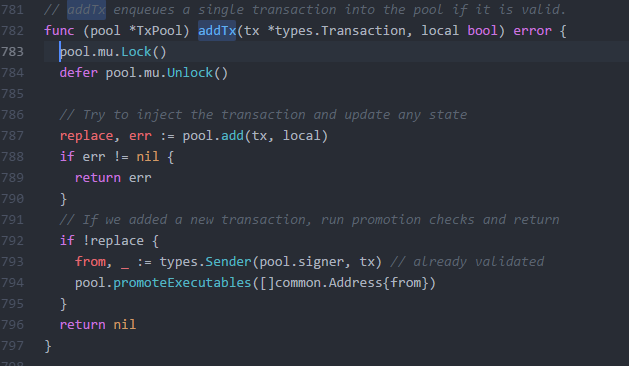
So these locks create a lot of satefy, they are the safety that when a transaction is received, we will actually add it. But we care about scale, so what if a few transactions are lost, so let’s get rid of it.
We also want to get rid of that add check, anything that compares state is notoriously slow (again, this is used to be able to overwrite transactions, but we only care about speed right?)
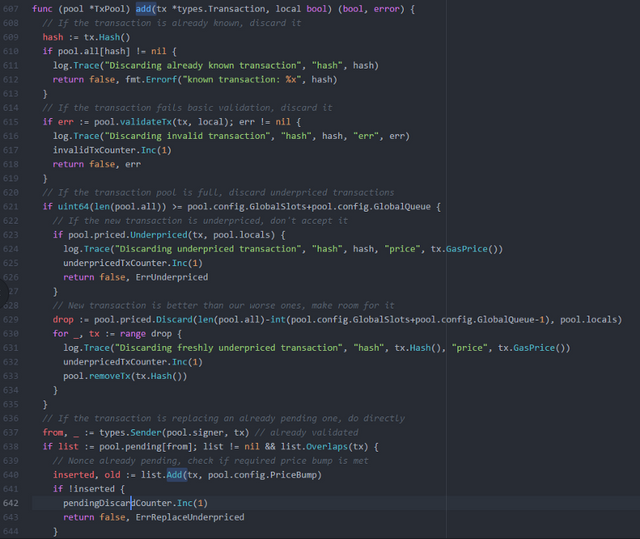
So here is the real meat, the validation of every transaction to ensure they are good and proper. Each check is vital to the safety and trust of a transaction, but we only care about TPS right? So gone they go.
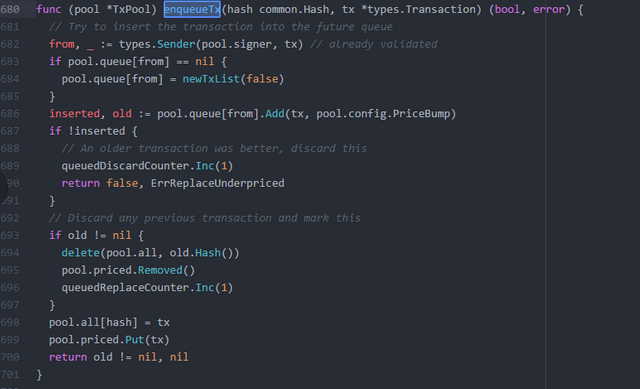
A lot of time is spent on the increasing funds mechanism to resend transactions, but we don’t care about any of that right? All gone.
Finally, turns out web3.js was actually the source of most of the slowness, ended up bypassing it completely and went directly to the internal API sendTransaction, much much faster throughput, still not where we want to be, but a comfortable 15K TPS so far, with 90k block sizes
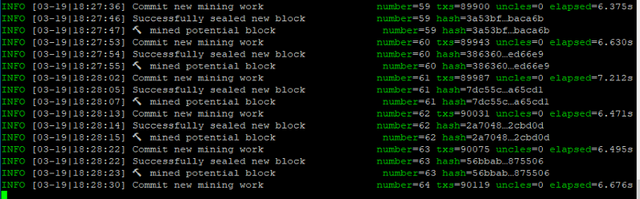
That 90k limit is interesting isn’t it? It exists to ensure fairness, let’s say a block had no limit and you can add as many transactions as you want, then every node would be trying to add all transactions (since they get all the fees), so the person or group with the strongest hardware would always make the most profit, not very decentralized now is that? A secondary side effect of this limit, is that it limits blocks size in MB indirectly, this is to stop 1 Cheating by adding all transactions and 2 to help systems with worse connections. Can you imagine if every block was 1 GB of data? How many of you could still mine?
But, we are a “trusted” node, we won’t cheat right? So let’s get rid of it.
Very valid checks, things like making sure we aren’t mining ahead (again to help fairness) and to make sure we don’t cheat, but again, we are a trusted node, so let’s get rid of it.

100k TPS from commit to mine (see how easy that was? It completely ignores the 11 seconds it took to actually create the block, and the network latency from sent to created, but nowadays we just measure TPS as how many transactions are in a block right?)
Test 1.5 1m TPS - Controlled hardware
So we start up a m5.24xlarge, this thing is a beast, m5.24xlarge 96 CPU 384 RAM, complete overkill, but we want that magic number of 1m TPS, so this is how we do it, we control the environment.

1,500,001 transactions in a block. Does that mean we win?

I hope I have started to illustrate my point, there is still so much I can change, we can drop the PoW and instead have our trusted nodes just mine without any computational power (so no time spent between sealing and mining), we can still remove all of the sorting and extra validation in block creation (just throwing them onto the stack), so truth be told, I can still get this number quite a bit higher and then I haven’t even touched sharding yet (That will be another article, let’s x16 that TPS number.)
Quick explanation on sharding, I am going to go for the easiest (and worst) implementation of sharding, and that is to use domain name spaces for accounts. So how does sharding work? Sharding is breaking up large chunks of work into smaller pieces, it’s like building a house, there are lots of small jobs that can all run in parallel, if you have 1 person doing all these jobs, that person becomes the bottleneck, if however you have 10 people they can each finish a specific job. So in this case, we are saying that a kind of account belongs to a certain worker. Worker 1 will deal with all 0x0 accounts, worker 2 with all 0x1 accounts and so forth. Why is this a bad sharding solution? Because it can’t scale infinitely, this at best can scale to 16 shards 0 - F, but for our purposes 16 is more than enough.
Conclusion: 1.5 million “TPS” achieved. TPS is less important than, how we measure TPS, and TPS as a theoretical excercise vs TPS in a production environment are two incredibly different things.
You want to get rid of PoW and only use trusted nodes? Sure, you can exponentially increase that TPS. You want to make sure those trusted nodes are high end? Sure, you control them afterall. There are so many factors you can control to create the perfect TPS environment, but none of this is true blockchain, it’s just another form of centralization, you trust those nodes, you trust their owners, true decentralization is about a complete lack of trust, you don’t trusts those nodes and you definitely don’t trust their owners. This is what makes blockchain so wonderful.
My mentor decades ago taught me, when you develop two systems, you develop them like system A does not trust system B. I architecture that way even today, because people, and especially systems are inherently evil. So why are we throwing away this wonderful solution of blockchain, and instead favoring the old centralized way, where the richest and most influential control all the power? Blockchain was about shifting that power from them to the masses, and instead we are rewarding these centralized solutions more and more with our money.
Anyway, there is your Ethereum with 1.5 million “TPS”, it took me less than 24 hours.
Thanks for posting your good work Andrew. Appreciate your in depth code reviews and your insight
Amazing work, Thank you very much from Orlando/Colombia..