You are viewing a single comment's thread from:
RE: In the Beginning, There Was DPoS
- There is now way to make a 51% attack impossible. Actually it's even proven that you need 2f+1 honest nodes (roughly 2/3) to guarantee progress. Dan avoids this by making synchronous assumptions.
However, the best way would be infinite witness votes to guarantee the highest overlap.
How many consensus nodes there are. It depends on the performance, less nodes > performance, more nodes < performance but potentially more security.
However, in DPOS the more nodes you have the more witnesses have to come to an agreement which gets more complicated the more there are (people are difficult).
So I honestly think 20 is a good number.
*You mean
3f +1total nodes to toleratef = [(n/3)-1]faulty nodes?I have looked a bit into the things you pointed out a few days ago. The dPOS in Steem (other than in Bitshares) is not a pure dPOS but a dPOS+BFT or dPOS-BFT or "pipelined dPOS" how it is called in Eos, which makes it actually a quorum. Even though there is no obvious direct each-to-each communication, there is still each-to-each communication.
In dPOS-BFT there is a leap of faith (Vertrauensvorsprung) like in Bitcoin, which makes it a retrospective protocol. After blocks are added (Now comes the quorum) --> the other witnesses have to verify the last irreversible Block (LIB) with at least
2/3. The consensus rule is: that no honest node will join a chain which is not build on the last LIB. Aka. the longest chain rule.People confuse the consensus mechanism (dPOS) with the oracle (PoS). Consensus is never made by the Oracle. Hash-Cash aka. Proof-of-Work is just an oracle - in fact a special form of proof-of-stake. The consensus is done by the set of consensus rules (fork-choice/longest chain/longest and heaviest chain)
This means it is a quorum by the longest chain rule! Now I understand why Vitalik pointed óut that dPOS-BFT other than dPOS (and I guess dBFT like in Neo) is subject to message complexity!
The
BFT 2/3+1 safety assumptioncomes with the use of the round-robin scheduling. When all active nodes add one block per round -> every 3 seconds (the quorum is synchronized by the fixed consortium), THEN a round is k times 3 seconds and the chain grows with --> 3 seconds per block.Any malicious set of nodes up to 1/3 can create a minority-fork but this malicious fork will only grow as fast as 9 seconds per block (note that the consortium is still one and of size k), ergo the honest chain will still grow with 6 seconds per block. Hence --> 6 seconds is the minimum honesty-decidebility-criterion.
When a malicious minority is bigger than 1/3, we have the equivalent of a 51%-attack vector (not exact the same since bitcoin is binary and this state is a undecidable "pending" state). Because
f=1/3 +1 means that there is no honest 2/3 and hence no 6 seconds. So the correctness is violated (even though the system still makes progress in this pending state)Yes, exactly. 3f+1 total nodes where f nodes are faulty means that we need 2f+1 honest nodes to guarantee progress in a classical BFT protocol.
I don't see where in DPOS the message complexity comes in though. It schedules round robin and after 2f+1 nodes added their block, the last block is "finalized" since every other node once agreed on a block that built on top of the block that is being finalized. This creates an implicit quorum. However, this doesn't create any messaging overhead.
Also, I'm not 100% sure if the chain would continue working if 49% of the top 20 witnesses would stop producing valid blocks or if that would cause a chain halt because 2/3 are necessary. I read a few things about synchrony assumptions and under those assumptions you can guarantee progress with f+1 out of 2f+1 (simple majority)
OK I try to order it, I was on the same track. Maybe you can validate.
What is Synchroinizity assumption?:
ALL distributed BFT-consensus systems are based on synchronicity assumption. All networks are theoretically asynchronous.
The problem: the
Ficher-Lynch-Peterson Impossibility Theoremproves-->Now what does it mean to be "synchronized"? Computers don´t have a concept of time, they only know order. In a closed distributed consensus system like in a spaceship e.g. the Falcon9 --> tightly coupled nodes have a central time oracle (an atomic clock or what ever). In global distributed systems, having a time oracle means >>who ever controls the service, controls the order of events<<...and even if honest, network delay and relativity lead to clock-drift.
Decentralized Clocks
So, for EVERY decentralized distributed consensus system you need a decentralized clock. In a closed or permitted system you can use network-latency as a clock. This is what we typically call synchronicity assumption. This is what made classical distributed BFT-consensus in global networks possible. But it only works when the number of validators is fixed and known (otherwise you cant calibrate). Research here was done by Lamport et al. (Lamport Clock, Logische Uhr and so on)
Bitcoin has simple majority because it uses a different clock
Bitcoin is an open ergo --> loosely coupled system, where nodes can join at any time. Calibration is not possible, you cant use network-latency as a distributed clock.
What nearly nobody knows: The Hashcash algorithm in Bitcoin is not only an oracle but also a distributed clock. As we know, having more hash-power does not mean that you are faster than other participants you only have a higher probability. Difficulty adjusted it always takes ~10 minutes. The SHA is a so called memoryless function. For every computational-cycle/iteration and for every participant the probability per worker is exactly the same. The entropy is universal. Even when your giant pool tries 1000 Trillion possibilities per second you are not faster...1000000 Trillion is practically zero compared to 2^128 or 2^256. Every human number is zero compared to a number space that big. With every cycle, every miner of your pool starts from zero. This is memoryless. This is how Nakamoto synchronized all the anonymous nodes. The clock here is information theoretical entropy aka unkown states/bits. Most people think he simply "assumed" synchronicity :D
the criterion is binary because work allows for a node-agnostic consensus system aka longest-and-heaviest-chain-rule. This is why there is >1/2 Safety assumption and a 51%-attack vector. So yes, synchronicity assumption are the very fundamental-physical reason for all those numbers. It is not simply "math" it is determined by physics.
now back to advanced dPOS of steem
The blockchain is just a data-structure it only exists in the epistemic domain, ontologically there is no blockchain. What physically is there is a replicated state machine. When you add a block to the "chain" you propagate through the network until it reaches all other nodes. Adding a block needs 3 seconds but really adding to the state machine needs 2N². Lets assume that N is 14 (2/3) those 14 add their block to the chain...since the chain does not exist as a central server, somebody needs to verify that 14 nodes have added their valid block and this SOMEBODY are those 14 Nodes. This is why it is N² and since it is bilateral communication it is 2N². Otherwise you need a central coordinator...
That's wrong, there are BFT algorithms without synchronicity assumptions:
Those are two recent ones, in the literature you'll find more.
Synchronization in the context I was talking about is making timing assumptions.
Making timing assumptions means that we can assume that a message from one server to another will have a "maximum" roundtrip.
Asynchronous protocols don't make any timing assumptions in this regard.
Now, if we know there is a maximum time, then we can ALWAYS detect if a faulty and thus, we can avoid a lot of the problems and can achieve safety and liveness with a lower percentage (51%).
Going back to DPoS. Yes, every block needs N^2 to be finalized. But if we add more witnesses this will spread out over a longer period of time as well so that will only increase the latency and not be a problem for throughput at all.
yes, thank you I completely forgot about the new "3.0 paradigm" (have not read into any of them yet (except for avalanche) but afaik the critique of Sirer on Hedera was that they are (maybe not timed) but calibrated. I will look into it.
Ok I get what you mean. Then one has clearly to differentiate timing (which involves clock time) and synchronicity without time. But I realy dont think that any of the protocols works with actual clock time, Because the 3 seconds are not a protocol parameter but a constant? When you use a BEOS node in the orbit it changes.
yeah but there is no known maximum time I would say. Whoms clock you take to measure time?
good point, now I guess I understand Dans Triangle
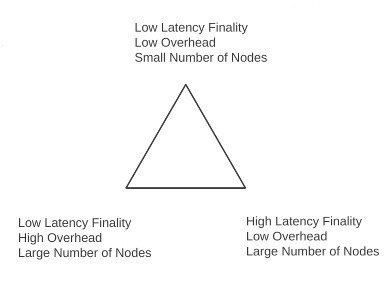
this scenario comes to the cost of finality-latency
Most of the truly asynchronous protocols are only probabilistic. (Similar to avalanche). However this concept is very old already(many papers from the 90s discuss it.
If we have some known max delays we can do this: