Stealth Development Blog 001: 12/7/2018

Starting Development: Data Structures
I’ll start off by explaining my development process for big projects. First, let me explain that I am not a computer scientist and have no formal training in software engineering. But I do have a process for development that comes from a couple of decades of work in computationally intensive fields of biological science.
Before I start programming, I make a specification of the software I want to create. For qPoS, this Whitepaper represents this specification. When actually I start programming, like I did for qPoS this week, the first thing I do is create the data structures. My philosophy from my scientific years is that the data structures are the infrastructure of the program. If they are well designed, coding the logic is very straightforward.
-------
Main qPoS Data Structures: Registry, Staker, Queue, Balances
This week, I began the following data structures:
- Registry (QPRegistry class)
- Staker (QPStaker class)
- Queue (QPQueue class)
- Balances (QPBalances class)
This list contains only four data structures, but they are going to contain the bulk of the logic for qPoS. The Registry itself holds a map of Stakers, indexed by Staker ID. The Queue is the set of randomly shuffled active Stakers, re-generated each round, and also held by the Registry. The Registry also holds and manages the Balances.
-------
Registry: The Master qPoS Data Structure
The Registry lies at the top of the compositional hierarchy. A single Registry object (or actually a pointer thereto, called pstakerRegistry) will effectively be in the global namespace. The Registry will be queried for all types of qPoS related block validation. For example, it will be queried to see whether a block’s timestamp is consistent with the Queue.
The Queue is also managed by the Registry. So when a round finishes, the Registry will create a new shuffled Queue, after the Registry does housekeeping like removing terminated Stakers, adjusting balances, and applying any public key changes, just to name a few housekeeping tasks.
-------
Data Structure Changes
Staker Balances: A Separate Data Structure.
While coding, I have realized it will be much better to make a couple of changes to the data structures described in the Whitepaper. So far the most significant change is that the staker balances will be a separate data structure, which I’ll call Balances, and which will have the class name QPBalances. (Incidentally, the “QP” stands for qPoS, and is just the first two letters, capitalized. Using an unusual two-letter prefix like this is easy protection against namespace conflicts.)
The Balances data structure is really the second part of qPoS’s “fused ledger” technology, in that the blockchain represents one part of the fused ledger, and Balances is the second part. The Balances data structure resides 100% in RAM, as described in the Whitepaper. Separation of Balances to its own data structure allows easier management of Stakers by the Registry. Namely, instead of iterating over Stakers, checking whether they are active, then adding active Stakers to the Queue, the staker is simply deleted from the Registry when it is inactive, and all Stakers left in the Registry are shuffled into the new Queue. The only persistent part of inactive Stakers is their Balances. These Balances decay slowly over time so that eventually the Balances of inactive Stakers can be purged from RAM.
-------
Improvements to qPoS
I have also made a couple of major improvements to the qPoS design, and am already putting these changes into the code.
Introducing Staker Delegation
Staker ownership and block signing rights will be independent, allowing staker owners to delegate staking to third parties, without the risk of losing ownership or any earnings. This means you do not have to be a Unix guru to have earnings from a staker. You can buy it, find a service that will operate it, and both you and the service can be rewarded directly from the block chain.
To do this, I have made a couple of design changes to the Staker data structure. Most notably, Stakers will have two public keys (pubkeys). In the Whitepaper, I mention a single pubkey registered to the Staker. This pubkey would allow Stakers to sign blocks and transfer ownership. However, I realized that a single key design like this precludes outsourcing staking to third parties. By splitting the rights into ownership and signing, staker owners can outsource staking without worrying about the staker being stolen. Another addition I made was the ability for a staker to assign a payout percentage to delegates, which the protocol manages. This is a trustless way to compensate delegates.
These additions inspired a separate Balances data structure, described above, because the protocol needs a way to store delegate balances. The previous design stored a staker’s balance in the Staker data structure, meaning there would be no place to store the delegate balances without a separate data structure.
Discouraging Timestamp Attacks
I have identified a potential Staker attack, and am implementing protection against it. I believe this attack would be one of the most problematic attacks on Stakers if not addressed by the protocol.
The heart of the potential attack is that Stakers will be disabled if they miss too many blocks. This seems reasonable, but it does expose a Staker to vulnerabilities. Staker vulnerabilities can come in two types. The first is a denial of service attack directed at an individual staker. Network denial of service attacks are greatly mitigated because of Tor routing, which is enabled in the client by default. The only packets a client should accept at its public Tor address should be Stealth network packets, identified by a leader sequence and having a well defined structure. If these packets are malformed in any way, or are designed to be a burden, Stealth already has rules that quickly ban peers that send these malicious packets.
The second type of vulnerability is that another staker will intentionally create a situation where its peers miss blocks. There is some economic incentive to do this, mostly because it reduces competition for the block reward pool. I believe that the easiest way to attempt to make other stakers miss blocks is for a malicious staker to create a block in the future, then try to append it to a block that skips the staker prior to itself in the queue. This attack probably requires an illustration to understand.
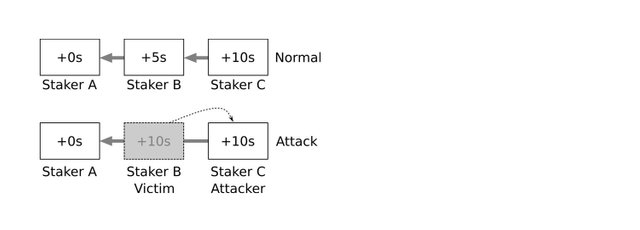
Under normal circumstances (top) each staker in the queue signs a block and links it to the previous block (grey arrows). In the top of the illustration, the block by Staker C links to the block by Staker B, and the block by Staker B links to the block by Staker A. The attack (bottom) is when an attacker (Staker C) mints a block that links in a way that skips a victim (Staker B). In this case, the block by Staker C links to the block by Staker A, skipping B. This attack requires forging a timestamp that is ahead of the current clock, hoping that network latency will allow for this block to be linked to the exclusion of the victim’s block, causing the victim to miss a block. A node’s system clock has granularity down to the microsecond, meaning a forged block timestamp only needs to be in the future by a few microseconds for a successful attack, which is generally much smaller than even the best network latencies.
To understand this attack from the illustration, the grey block is created in the victim’s time slot but has a forged timestamp, making it appear to be created in the attacker’s time slot. The time differential between the actual creation and forged timestamp is represented by the dashed arrow.
In my design to discourage this type of attack, each staker in the registry will be accountable for the blocks of stakers immediately previous in the queue. If the previous staker misses a block, then the block reward for the staker who comes after is reduced by half. Additionally, stakers that have a very high number of missed blocks by those immediately previous to them will become permanently deactivated. Since the queue is random, a staker that has gone down and is missing blocks will affect all other stakers equally. In this case, no additional Staker will be penalized. If a staker systematically excludes their previous stakers’ blocks, they risk getting deactivated. This protection makes it completely impractical to eliminate competing stakers using this timestamp attack.
–––––
Hondo