Blowing off some steam in steem
Well, I described myself as a Software Developer. But who's a software developer? What does she do?
I really don't know. I mean, I do make software professionally, but I don't get very well all the “marketing” definitions, especially their modern meaning.
And now I know I can't stand the hierarchies. That's because until recently, I had a turf I was curating, and in this turf I had most of the decisional power. I was building software ground to top, and top to ground. Almost every bit was mine to determine: even if in a team with a person who played the roles of manager and designer, most of the design was done by me, or at least I had the chance to work on the design altogether with the official designer.
That means that I wasn't consulted as an after-thought, or just to gather valuable technical informations for the analysis and the design. Instead, I was an active part of the process and, as said above, indeed most of the design was done by me. Then there was no surprise on certain details: I knew them very well, having decided them myself or altogether with the analyst. I always felt engaged with the project which was, indeed, a creature of mine.
Now something's changed.
Different team, different, new, and big project. Especially different team. In this team, the ratio between administrative/manager/designer roles and actual developers is like 3:1. That is, there are three of them of one of us. And if you consider a specific “area”, those number are exact: I am one developer, and they are three. If we ignore the more administrative, manager-like role, we can say that there are two of them for one of us or, more accurately, I am one, they are two.
And those two are smart asses who work in a very traditional way — to be gentle with words. That means also that they “handle” me like a pure coder. I was not actively and interactively part of the analysis and designing process: I was just consulted when they felt the need to.
The result of this is that I was “demoted” to the role of a simple coder. I mean, they produced a certain amount of documentation — among the documents, a “technical” but too much wordy document which contained pretentiously detailed actions (discursively!) — and I had to study those documents and follow instructions to be trasformed into code.
First, if you are a designer and I am just a coder, you don't provide me with a discursive list of things the code should do, a long “detailed” enumerated list (and nested indented lists) which makes me lose the point of what I am doing and what it should be done. It goes like this:
4. Use the value “Abc” for the field “Def” 5. Do this thing by doing this other thing and that too 5a. if this thing fails, then 5a-i. create the object and initialize it with the following values: 5a-ii. for the field YYY use the value of the default taken from the configuration ZZZ…
If you have to do this crap because you think it's as things must be done by top-level designers and analysts to instruct low-level employees-coders, then write it in pseudocode: more terse and less distracting. Indeed, at that point you could also write the code yourself… But let me refrain from harsh arguments.
Something like this:
Def ← “Abc”
Thing: {
doA
if (doA is ok): doB
}
if (Thing failed):
new obj
obj.YYY ← Config.getValue(ZZZ)
and so on. Of course, this pseudocode isn't written in a formal pseudolanguage, but a programmer can understand it and get the bits at a glance, without the need to read accurately a prose full of unnecessary and distracting words.
If the target language is, say, Java, you could use pseudo Java:
def = "Abc"
try {
doA();
doB();
}
catch (...) {
obj = new obj();
obj.YYY = Config.getValue(ZZZ);
}
But then, why not to write almost the actual code and let the coder-drone just fill the blanks? Even if sad, it would be better than what was actually done.
Now… Once you are treated like a coder, you can't feel engaged in the project. It seems like you are just a robot who follows instructions… to produce instructions for another robot… Moreover, you expect that there's one master, and a platoon of drones. But here we have two masters for every drone. Which is insane.
And that's when things go bad: I've made more avoidable mistakes than ever in my life — and it's not finished: more are still to be found! And some of those mistakes were because I assumed things to avoid to have to follow all those words again and again; other errors were because it is hard to check the implementation against a discursive, although enumerated, list. Hence, when I did my tests, there must have been a sort of “confirmation bias” nurtured by the abundance of those words; maybe I skipped some of them in the third reading, or whatever.
Also, I don't feel like I really “understand” the project as a whole. I'm losing bits.
And there's another problem. When you, as the person who write the actual code, are also in the design process, you can change it interactively and continuously, as you get a different “perception” when you write the code. You see a wall while coding, and you understand if it's better to jump it, or to make a hole of a certain shape. If the design said it differently, you adapt the design and the technical documentation according to the code as built.
Now I understand some of the points of the agile buzz, too.
Do not overspeficy!
There's another mistake that makes the life of this newly found coder-drone harder: overspecification in a not agile environment. If you give this overspecified technical document to a quality assurance team, they will check all of the specified bits — and you've made and official commitment to respect whatever is written in that document.
Now, imagine this scenario.
I made the jump instead of the hole because the jump revealed to be better while writing the actual code.
First I had to inform my two masters and discuss the change with them. If they approve it, they change the document, and pass it back to me again, with a list of changes. I have to dig the list of changes, find the sections in the document, check the implementation over those changes to see if now document and implementation now match — yes, everything's upside down.
If everything's ok, the document will be passed to the client quality assurance team who's in charge of testing the software.
But wait, there's a problem. We are not agile. That means that the document given to the quality assurance team is the normative one. That is, if implementation and document don't match, I have to change the code, no matter if it is better as it is. We could also say: well, the document we gave was wrong or not up-to-date. We had an afterthought about how it should be done — after we gave you the document. This can be done, but it is more problematic than saying: well, you've discovered a defect our stupid coder injected into the software because she didn't follow the document we gave her (this statement is implied, of course).
Result: the code needs to be adapted to the documentation.
Now, you can point out: if it must be in the other way, what's the point in writing the documentation? (That kind of documentation? it's trash… but by now let's imagine it is better than it really is.)
In fact! To me, Code Is the Master. The lowlevel design documents must be derived from the code. And never be passed to the quality assurance team, who should have a less fine-grained overview of the software.
Moreover, giving the documentation to the quality assurance team shouldn't be seen as a “fixed point in time”, when every afterthought is a software defect, a bug, a mistake for which the client will pretend something back from the supplier.
Do not overspecify! (2)
So, what I meant by overspecifying? To put details which do not need to be specified. Details which does not change “facts” about the software.
Let me do an example — if you are still reading, I hope you'll learn something about corners of the software industry…
The software exposes an API. An API (Application Programming Interface) is defined via a sort of contract, so that the caller knows how to use it and knows what to expect by calling it in certain ways.
In particular, the caller can call it wrong.
And in the contract I say that when it happens, the response is “BAD REQUEST”.
This is the important bit.
But in the documentation I also say that if the request is wrong because it's missing a required information, I add a specific error code to the response. Say, -5. So, now the answer is:
BAD REQUEST: -5
That means: you request is bad because it is missing a required argument.
Ok, but which one? Ok, let's add this bit to allow troubleshooters to identify the problem:
BAD REQUEST: -5, field “YYY” missing.
But you can also pass a wrong value for a required argument. Then I have this answer:
BAD REQUEST: -3, field “YYY” cannot have the value “xxx”
Now we have overspecified a little bit, in my opinion. If the software, for whatever reason, says:
BAD REQUEST: -3, field “YYY” cannot have the value “”
We are basically saying that the field is missing: if I don't have the value as input, or if I have an empty value as input, it is just a missing value, and missing values are values, so to speak, that field can have.
But if the document says that -5 is the code we give back when the field is missing… Well, the code needs to handle the empty value as a missing value and change -3 in -5.
But here the important bit was just BAD REQUEST. All the rest is added for the troubleshooters and should not be considered by the QA (quality assurance) team.
That's why: at a certain point, the QA team will certify that the software is ok. The software will be released in production. In its natural and real environment, there could be other problems the QA team wasn't able to spot. Real problems will be pushed to troubleshooters, who need informations about the problem.
I will be asked to change one of the BAD REQUEST strings so that it contains a different information, e.g.:
BAD REQUEST: -3, the field “YYY” must be an integer
So, troubleshooters said: we don't need the input value in the answer, because we have it already. Instead, it can be helpful to have what it should be!
I will make the change. And now, what's the work of the QA team worth? (Ok, there are people working and having wages…)
The QA needed just to certify that if there is a bad request, we say in fact “BAD REQUEST”. Details about the description of what and how the software explains why it's a bad request are an overspecification — even not part of the client requirements. But, if you write down those details, of course the QA team must check them. And you've just made your life harder for nothing.
In this example it's important to remember that a machine can't do very much about a BAD REQUEST. So, specific error codes (and their descriptions) are just for human developers and troubleshooters.
That is why a non-overspecified document would have just this:
- in case the request contains syntax errors, or required fields are missing, or fields contain values that can't be accepted, the system will respond with BAD REQUEST, plus an optional string describing the problem for human consumption.
When a tester or a QA guy must check this, she calls the API with intentional wrong values and whe she sees
BAD REQUEST: field “XXX” cannot accept value “”
rather than
BAD REQUEST: required field missing
she can't signal a problem in the software: all she has to check is if the response is BAD REQUEST.
Internal documents will have all the strings we — er, they — decided to have. We can expand or rescrict descriptions as we see fit, or as troubleshooters ask, in any moment.
Conclusion
This is just to blow off some steam, because I am in a mixed state of sadness and rage. I didn't speak out when maybe I could, and now the things are set and done. I didn't speak out because I'm the guy who tries not to step on other people's toes: with two master-designers, I accepted the fact that I wasn't needed in that process. Then, when I was presented with documents that were some kind of nightmare — especially the “actions” part, like if I were just a coder —, I decided again not to speak out, because there wasn't really anything to say, except “this is utter crap. Now I show you how I would have done it.”
There are other awry things I didn't mention because then I'd have to give too much details to make them comprehensible.
On the bright side, as “just a coder” — because I was treated like this — I am overpaid… On the dark side, as “just a coder”, I'm bored, not committed, not focused, disenchanted, and so I'll slip a lot more than usual, with the risk of gaining a bad reputation — maybe “the coder who can't code as the LLDD says!” or alike.
Now, a couple of pictures that tries to show graphically some of the problems.
The inverted ziggurat
Usually you have just one project manager and few architects and designers. The developers should be more, or at least the same number especially when the roles overlap.
A regular ziggurat looks like:
In my case we have this ratio of 2:1 (two designers against one developer), that is, we have in the inverted ziggurat case.
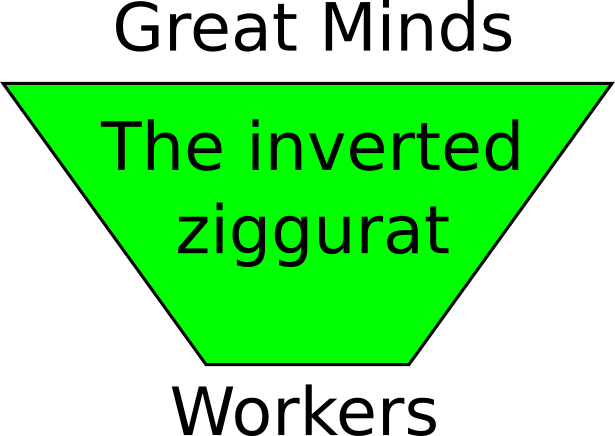
This means the project will suffer: likely it will be overspecified, and there's also a risk to fail deadlines — to avoid this, likely the general quality of the software will be lowered. When you are in hurry, you leave a lot of checks for later; but when later comes, it's too late: you had to release a version for testers and QA team. Hopefully something will stay under the rug for a while.
The tainted overall process
The client provided the software supplier with a bunch of requirements for the first drop. We talk in drops, that is, likely the overall process is seen as agile.
The software supplier produced proposals about the systems. When the client approved them, the supplier made the analysis and the full correct design, from top to bottom. In a not-so-agile way.
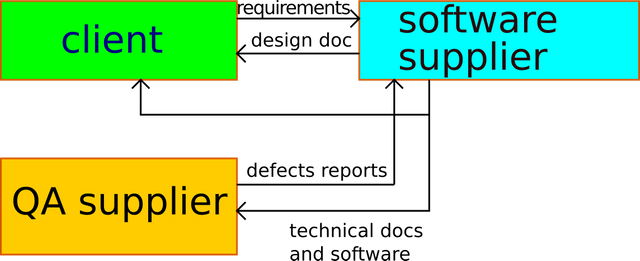
When the first version of software was ready, a technical documentation was given to the QA supplier. This is the one which is overspecified in my opinion. The software was also given to the QA supplier (well, more accurately, the software was installed in the client's system, so that it was usable by the QA supplier).
The QA supplier started to dig into the software problems, where among problems there are also mismatches between the software as-built and the documentation as given to the QA supplier.
The QA supplier produced defects' reports which were filed to the software supplier, which has to address them.
The picture failed to mention that the QA supplier is paid by the client, it is not hired by the software supplier. The software supplier should have its quality team, or at least a test team. But it hasn't.
To make things less clean, the software interacts with other systems: integration tests were needed, but the software supplier wasn't provided with this possibility, not until the QA team's tests began. Therefore, few defects reported by the QA supplier could have been avoided if the client had given the software supplier possibility to make integration tests before the start of the acceptance tests.
Inside the software supplier block there's the internal process which I mentioned elsewhere in this article, and that it's tainted.
Different gears interacting
Another problem is the internal process, which is mostly waterfally in a context where other teams play agile, with different technologies, and the client expect a more reactive attitude towards changes (in requirements, for starter). It's a recipe for a disaster.
Just an example, hoping to do not give away too much details: the system A needs to call the system B. The system B didn't make the mistake to overspecify, nor to commit to a detailed specification document. They just documented the bare minimum to use their API.
For instance, there's a property, let's call it identifier, which is an input for the system B. System B wasn't worried the less for the domain of the identifier. What's an identifier? We don't care, they say: it's a string. E.g., “abc”.
But System A uses a classical RDBS, so the A-team need to know at least the maximum length of identifier, so that it can store the value in, say, a varchar2. Clearly B-team doesn't know / doesn't care the less for these wasteful details. So they added 256 as limit for all the string values. And the A-team happily created varchar2(256) columns.
For the B-team was easier to avoid wasting time in such a detail, because they use a so called NoSQL database, maybe a document-oriented database. This means that they really don't care if identifier is 100, 50, 256, or 1000.
Now, if tomorrow we see that 256 isn't enough, B works properly, A doesn't. A change is necessary. In an agile context, it would be swift. In an waterfally approach, “we” get upset because they don't gave us the correct information. We complain with the client, pretending this is a huge deal.
Now, the partially made-up example doesn't explain much. But I can assure you that changes which should be done in an eye-blink without questioning, become a big deal which triggers another waterfally round, with time wasted, too long calls to talk about … smoke.