用 Keras 搭建 Double DQN 模型
上一篇文章介绍了 DQN 以及如何用 Keras 一步一步搭建 DQN 模型,这篇文章我们来介绍一下 DQN 的改进算法:Double DQN。
1. DQN 的缺点
DQN 有两个神经网络: Prediction 网络 和 Target 网络。其中 Prediction 网络是用来训练的网络,参数一直在更新,Target 网络更新会相对滞后。我们在训练的时候使用 Target 网络 q(s') 的最大值来作为反向传递的“标签”。
然而,由于 Target 网络参数更新的滞后性,特别是训练的初始阶段,在这个神经网络所得到的 max q 是有误差的,如果按照 Target 网络所指导的方向更新参数,势必会加大误差。
为了克服 DQN 的这个缺点,我们可以采用 Double DQN 的方法。
2. Double DQN
Double DQN 并不是在结构上改变 DQN 的神经网络,而是在更新参数的方式上对 DQN 存在的缺点进行改进。方法也很简单,既然 Target 网络由于参数更新的滞后性,我们就更应该依赖 Prediction 这个网络来更新参数。当然也不能完全依靠 Prediction 网络,否则会造成不稳定的后果。
Double DQN 更新参数的步骤
- 在记忆库中提取 s a s' r.
- 将 s 带入 Prediction 网络中 得到 q(s)
- 将 s‘ 也带入 Prediction 网络中求最大q(s') 对应的a(max),即 argmax(q(s'))
- 将 s' 带入 Target 网络中 获取q‘(s')
- 将 a(max) 带入 第4步 求得的 q'(s') 得到 q'(s' a(max))
- 将 q(s , a) 对应的 q值 替换成 q'(s' a(max)) 送入 Prediction 网络中 反向传递更新神经网络
整个过程如下图所示
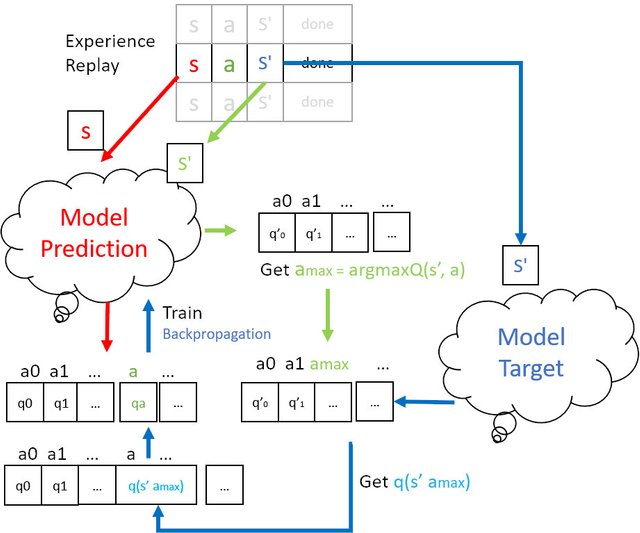
Image created by @hongtao
3. Double DQN 代码
Double DQN 看起来步骤繁琐,然而实际上在 DQN 代码的基础上进行简单修改即可实现。
首先,DQN 没有将 s' 带入 Prediction 网络,所以在训练过程中添加
next_qs_list = self.model_prediction.predict(next_states)
其次,需要在next_qs_list 通过 argmax 找到 a(max)
max_target_a = np.argmax(next_qs_list[index])
最后,将 max_target_a 带入到 target_qs_list 中 得到 max_target_q
max_target_q = target_qs_list[index][max_target_a]
该部分完整代码如下
class DQNAgent:
def __init__(self):
# Replay memory
self.replay_memory = deque(maxlen=REPLAY_MEMORY_SIZE)
# Prediction Network (the main Model)
self.model_prediction = create_model()
# Target Network
self.model_target = create_model()
self.model_target.set_weights(self.model_prediction.get_weights())
# Used to count when to update target network with prediction network's weights
self.target_update_counter = 0
# Adds step's data to a memory replay array
# (current_state, action, reward, next_state, done)
def update_replay_memory(self, transition):
self.replay_memory.append(transition)
# Queries prediction network for Q values given current observation space (environment state)
def get_qs(self, state):
return self.model_prediction.predict(np.array(state).reshape(-1, *state.shape))[0]
def train(self, terminal_state, step):
if len(self.replay_memory) < MIN_REPLAY_MEMORY_SIZE:
return
minibatch = random.sample(self.replay_memory, MINIBATCH_SIZE)
# Get current states from minibatch, then query NN model_prediction for current Q values
current_states = np.array([transition[0] for transition in minibatch])
current_qs_list = self.model_prediction.predict(current_states)
# Get next_states from minibatch, then query NN model_target for target Q values
# When using target network, query it, otherwise main network should be queried
next_states = np.array([transition[3] for transition in minibatch])
next_qs_list = self.model_prediction.predict(next_states) #Double DQN
target_qs_list = self.model_target.predict(next_states)
X = []
y = []
# Now we need to enumerate our batches
for index, (current_state, action, reward, next_state, done) in enumerate(minibatch):
# If not a terminal state, get new q from future states, otherwise set it to 0
# almost like with Q Learning, but we use just part of equation here
if not done:
max_target_a = np.argmax(next_qs_list[index])
# max_target_q = np.max(target_qs_list[index]) #DQN
max_target_q = target_qs_list[index][max_target_a] #Double DQN
new_q = reward + DISCOUNT * max_target_q
else:
new_q = reward
# Update Q value for given state
current_qs = current_qs_list[index]
current_qs[action] = new_q
# And append to our training data
X.append(current_state)
y.append(current_qs)
# Fit on all samples as one batch, log only on terminal state
self.model_prediction.fit(np.array(X), np.array(y), batch_size=MINIBATCH_SIZE, verbose=0, shuffle=False if terminal_state else None)
# Update target network counter every episode
if terminal_state:
self.target_update_counter +=1
# If counter reaches set value, update target network with weights of main network
if self.target_update_counter > UPDATE_TARGET_EVERY:
self.model_target.set_weights(self.model_prediction.get_weights())
self.target_update_counter = 0
Code from github repo with MIT license
4. 总结
Double DQN 是在 DQN 的基础上稍作改进,相对于 DQN 来说更加稳定,所以一般来情况下,都会优先选择 Double DQN 对智能体进行训练。
相关文章
DQN——深度Q-Learning轻松上手
强化学习——Q-Learning SARSA 玩CarPole经典游戏
强化学习——MC(蒙特卡洛)玩21点扑克游戏
强化学习实战——动态规划(DP)求最优MDP
强化学习——强化学习的算法分类
强化学习——重拾强化学习的核心概念
AI学习笔记——Sarsa算法
AI学习笔记——Q Learning
AI学习笔记——动态规划(Dynamic Programming)解决MDP(1)
AI学习笔记——动态规划(Dynamic Programming)解决MDP(2)
AI学习笔记——MDP(Markov Decision Processes马可夫决策过程)简介
AI学习笔记——求解最优MDP
吃了吗?来 @steemgg 玩游戏吧,决战到天亮倘若你想让我隐形,请回复“取消”。
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!