使用Kibana可视化Hive中文区的数据
在前面介绍了如何把Hive中的帖子保存到Elasticsearch中。有了数据,就有好多玩法了。下面介绍如何通过Kibana对Hive中文区的发帖数据进行可视化分析。

关于数据的说明
获取下面数据的代码,是根据上篇文章最后的代码稍作改编而得到的。作为演示,只读取了HIVE CN 中文社区的最新100篇文章。由于这篇文章的重点是介绍如何进行数据可视化,而不是可视化报告本身,后面有时间的话可以从链上把数据都抓取下来,放在ES中,那样生成的报告本身就更有意义了。
操作环境
Elasticsearch: 7.7.0
Kibana: 7.7.0
创建索引模式(Index Pattern)
ES中的索引模式(Index Pattern)可以针对多个索引,因此在创建时支持通配符。
在Kibana的页面中选择:Kibana -> Management -> Index Patterns -> Create index pattern
创建完毕后会看到如下界面:
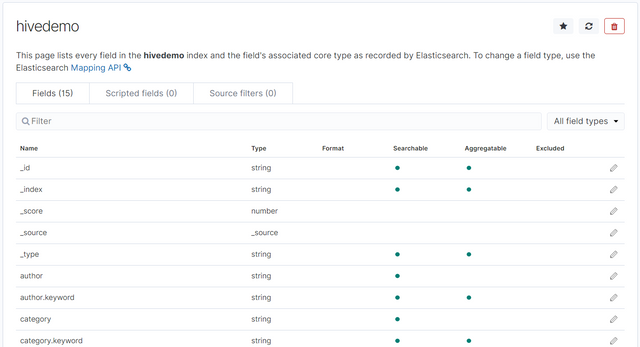
可以看到有的字段可以被搜索的(Searchable),有的字段是可以被聚合的(Aggregatable)。
在Kibana中查看数据
单击Discovery后,可以输入KQL来检索数据。
比如,输入:
author = aafeng
你会看到:
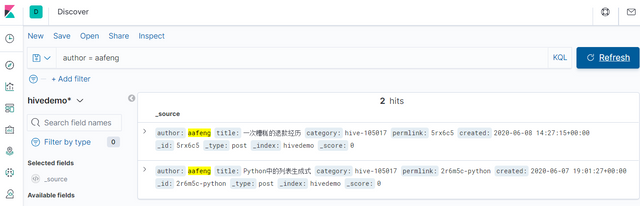
KQL的语法和SQL非常相似,简单好用,比如:
author = aafeng and created = 2020-06-08*
可以通过左侧菜单选择索引,以及字段。
Kibana可视化
下面把每个作者在所统计的区间(这100篇文章所覆盖的时间段)内的发文数做一个统计,并以饼图的形式呈现出来。
选择Visualize -> Create visualization -> Pie,由于目前没有对源数据进行定义,因此,初始饼图看起来这是这样的:
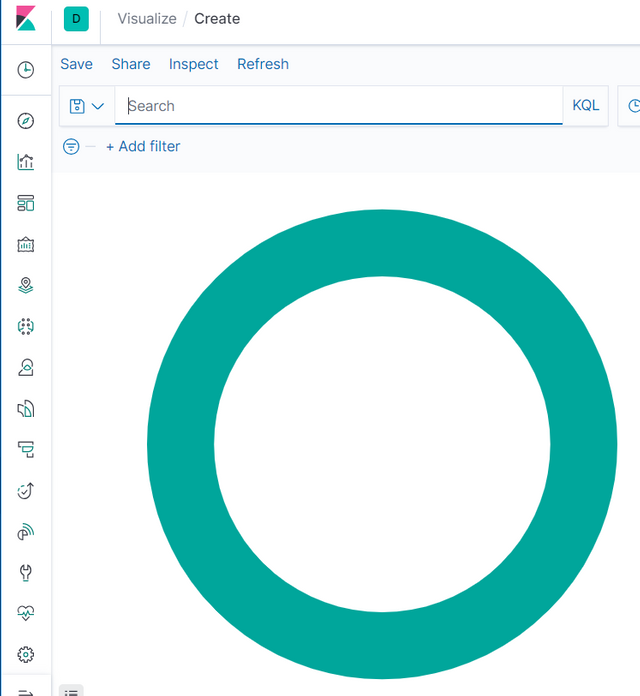
选择Buckets -> Add -> Split slices -> Terms,选取Author字段,并选择Metric: Count。
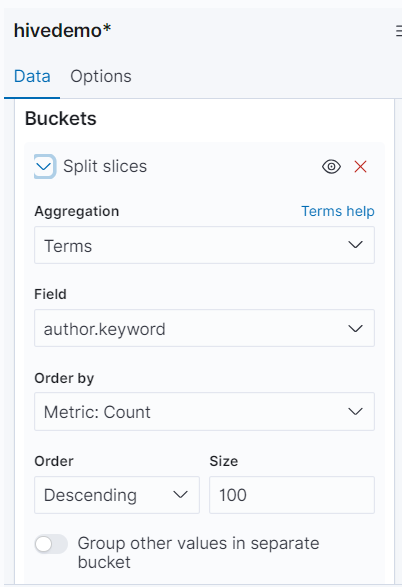
可以看到更新后的饼图:
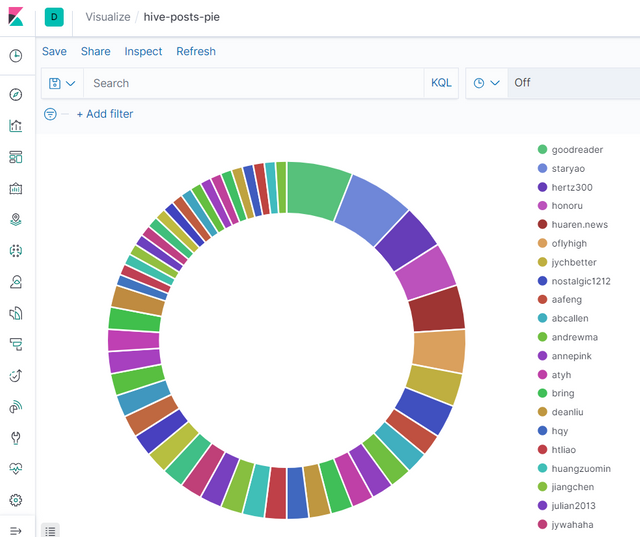
最后不要忘记保存你的Visualization。
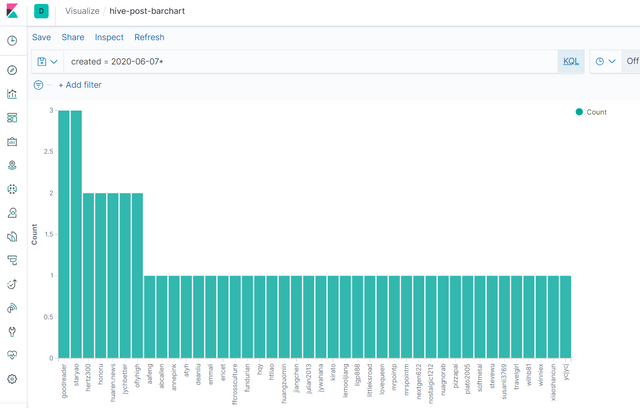
还可以把这些数据以不同的图形来展示,比如:柱形图。同时也可以通过KQL把数据做筛选后再绘制图形。例如:下面的柱形图展示了中文区6月7日的发帖统计: