Python学习笔记 - collections
在Python中,除了系统默认的容器:dict, list, set, tuple之外,还有一个非常强大的模块:collections。在这个模块中有很多非常好用的功能,能供简化我们的代码。下面举几个例子,欢迎大家指正。

namedtuple - 提高代码可读性
首先来看一个例子:假设我们有一组数据。想用Python对这组数据进行处理。最为直观的做法是:
people_list = [('Jim', 'male', 30), ('Julie', 'female', 25)]
for p in people_list:
print (f'{p[0]} is a {p[2]} year old {p[1]}')
但以上代码的最大缺点就是其可读性太差。上面的p[0], p[1], p[2]具体代表什么数据要检查前面的代码才能知道。设想如果处理的数据量更大,比如,共有十几,甚至几十列数据,如果在查看p[35], p[48]之类的代码时肯定会痛苦万分的。
这个时候就应该考虑使用collections中的namedtuple:
import collections
Person = collections.namedtuple('Person', 'name gender age')
people_list = [Person('Jim', 'male', 30), Person('Julie', 'female', 25)]
for p in people_list:
print (f'{p.name} is a {p.age} year old {p.gender}')
以上代码的可读性明显增强。不过使用namedtuple的一个缺点(有时也是优点)就是它的属性是只读的。
Counter - 优雅的统计代码
假设我们需要对一个列表进行统计:
['red','yellow','blue','red','yellow','red','black','white','red']
我们希望统计每种颜色出现的次数:
{'red': 4, 'yellow': 2, 'blue': 1, 'black': 1, 'white': 1}
如果使用一个循环,则代码显得非常臃肿:
color_list = ['red','yellow','blue','red','yellow','red','black','white','red']
stats = {}
for i in color_list:
if stats.get(i) is None:
stats[i] = 1
else:
stats[i] += 1
ordered_stats = dict(sorted(stats.items(), key=lambda count: count[1], reverse=True))
print(ordered_stats)
但如果使用collections中的Counter的话,代码就显得非常简洁了:
from collections import Counter
color_list = ['red','yellow','blue','red','yellow','red','black','white','red']
stats = Counter(color_list).most_common()
Counter也可以用来统计一段话中每个字符出现的次数。
from collections import Counter
s = 'The clever fox jumped over the lazy brown dog.'
print(Counter(s).most_common())
defaultdict
在使用字典时,一般可以使用 ‘dict = {}’对其进行初始化。在后续使用中,可以使用 ‘dict[element] = xx’,但有一个前提就是,element必须是已经存在的,否则就会出错。比如:
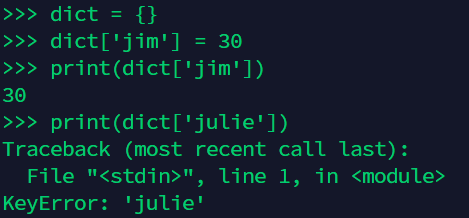
当然,我们可以在使用前检查某个元素是否存在:
'julie' in dict.keys()
但这会使代码显得很臃肿。
更为简洁的方法就是使用defaultdict,比如:
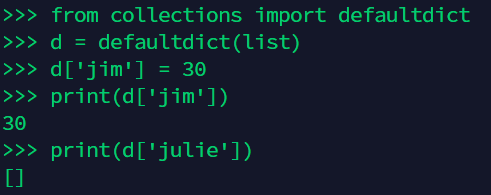
上面介绍了collections模块中的namedtuple, Counter, defaultdict,使用它们可以简化我们的代码,也能增强程序的可读性。
拍手