微博爬虫制作教程(小白版)#30分钟搞定微博爬虫系列
要获取微博数据,最简单是就是模仿浏览器或者客户端来调用API接口获取数据。而这些API往往是没有文档的,所以只有自己抓取分析。
- 首先,打开chrome
- 然后F12,打开开发人员面板
- 访问http://m.weibo.cn/u/1378236401
- 切换到network选项卡后点击过滤器中的xhr,并把网页向下滚动几页
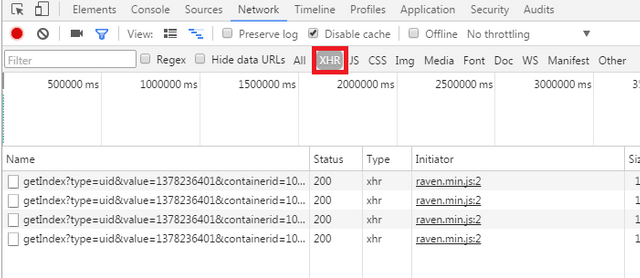
点击最底下的那条流量查看流量详情
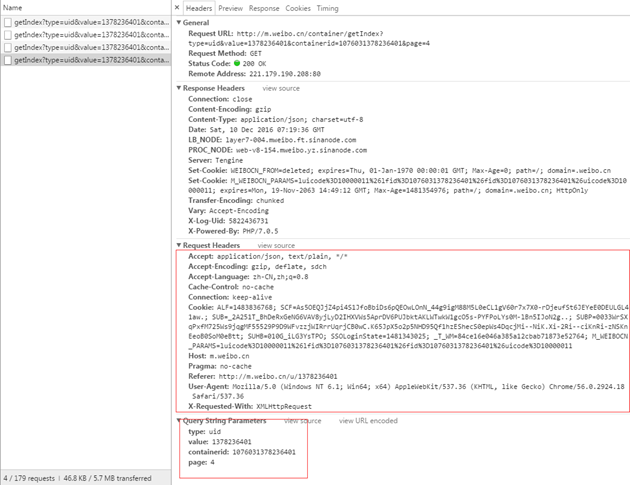
红色框内即为你提交的数据,切换到preview选项卡即可查看服务器返回的数据。
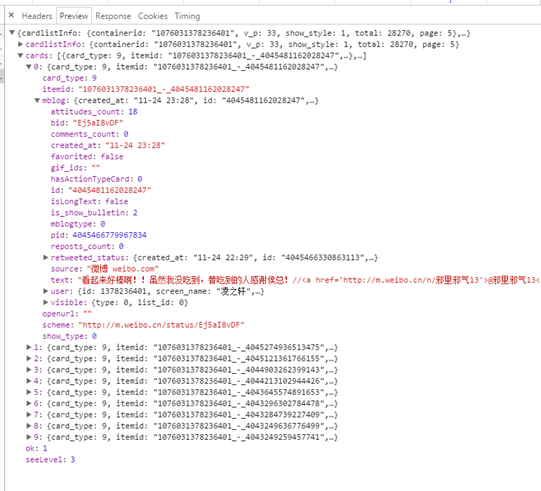
可以看到访问这个链接(API)得到的回馈为json数据,且为我们所需要的博客内容。
如图可见返回数据的['cards']字段内的list是我们想要的数据,再经过实验,确定card['card_type'] == 11时是删除的微博,因此无需显示。
然后就是构造请求模拟header开始爬取了,完整代码如下:
from requests import get
from time import sleep
import json
# header设置部分
headers = '''
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: xxx
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8
Cookie: xxxxx
'''
headers = headers.split('\n')
headers = [x.split(': ') for x in headers if x is not '']
headers = {x[0]: x[1] for x in headers}
# API调用参数设置部分
uid = int('1378236401')
containerid = int('1076031378236401')
pageStart = int('1')
pageInfo = {"sudaref": "m.weibo.com", "type": "uid", "value": uid,
"containerid": containerid, "page": pageStart}
# 从API获取失败重试次数
retry = 0
def get_json_data(pageNum):
global retry
global pageInfo
global headers
pageInfo['page'] = str(pageNum)
content = get('http://m.weibo.cn/container/getIndex', params=pageInfo,
headers=headers).content
json_data = json.loads(content.decode())
if json_data['ok']:
retry = 0
return json_data
elif retry < 3:
print(json.dumps(json_data))
retry += 1
return get_json_data(pageNum)
else:
return json_data
for page_num in range(pageStart, 999):
ret_data = get_json_data(page_num)
try:
for card in ret_data['cards']:
if card['card_type'] == 11:
continue
print(card['mblog']['text'])
except:
open('debug.log', 'ab+').write(str(json.dumps(ret_data)).encode())
print(ret_data)
print('\033[1;31;0m数据获取错误,请检测网络')
exit(1)
if ret_data['cardlistInfo']['page'] is None:
print('\033[1;32;0m好像已经爬完了,总共{0}页微博数据'.format(page_num))
exit()
sleep(1)
从自己浏览器请求headers里拷贝出来并自行设置一下上面的headers字段以及对应填好你要爬的用户id开始页数啥的就好。
大佬威武
dalao不敢当,虾米而已:)
不错。
多行代码用
```包起来会不会看起来更好点?蛤?。。抱歉,Python只支持用单引号或双引号来设置多行字符串,不支持```
哦,原来那个 headers 不是多行字串?
(以上理解错误,不知道怎么加删除线,姑且留着)
呼叫 @oflyhigh
其实我是说这个
vs
from requests import getfrom time import sleepimport json编辑器支持markdown吗?我试试:
加粗斜体
标题
诶,真的诶,我试试修改文章去
是呀。
貌似不管用。。。
.......然而。。。。。
...你把HTML和MarkDown混用就没效果了
要么纯 MarkDown 要么纯 HTML
好吧,我再修改一下
??????什么节奏,,,
内容全剪切出来,选 markdown 模式,再贴回去
选raw html模式,好了。。。话说raw html模式居然隐藏markdown功能???
果然有些行太长要横着拉,就不爽。
改了一下,好了
新发现。不错。
使用Markdown来让你的文章更易于阅读、更美观
https://steemit.com/cn/@oflyhigh/markdown
我猜你要的是这个?
话说我的浏览器firefox 收不到召唤啊
这个需要啥设置吗?
找你学 Python 。
不知道呀。等专家回答。
啊,说
'''啊你们之间的交流有歧义,不在一个频道上
你说的是Markdown
```包起来多行代码显示他理解成你说python用
'''包含多行文本然后告诉你多行文本只能用(三个)单引号或双引号不能用
```你说的是让我学这个吗?
还是我们也需要调频了;)
继续歧义。找你教我学 Python。
少年,我看你骨骼精奇,是万中无一的武学,哦不对,编程奇才,维护世界和平就靠你了,我这有本秘籍--->《如来神掌》,哦,不对《Python 编程宝典》 见与你有缘,就十块卖给你了!
內建召喚沒用的話,可以用steemwatch,但是你得上steemit.chat才會看到被mention的信息。
谢谢你
不过还是太麻烦了:)