Programming Diary #30: Towards tag-following
Summary
This post describes my progress after Programming Diary #29. During the fortnight between posts, I published an alpha release of the Steem Curation Extension and also worked with @cmp2020 to facilitate his collaboration on the tool.
Beyond that, I began work to let browser operators follow social media tags in the Steem Conversation Accelerator (SCA) and I also began some exploratory efforts towards measurement of paid vs. organic voting.
Read on for more about these activities and for some additional reflections about the interplay between the BTC halving cycle and Steem's upcoming double-halving phase.
Background
Here's what I anticipated for "next steps" in Programming Diary #29:
For this next interval, my main goal is to issue a first release in github using the semantic versioning label. I'll be testing today and tomorrow, and maybe I'll do that on Monday. The AIs said that I should also add the version in the extension's manifest.json file, but I'm not actually going to do that. I like having the release date in that file. Finally, I'll start with version 0.1.0, not 1.0.0 as Claude suggested. I don't feel like this should be considered a "stable" version yet (if ever).
Beyond that, I'm not sure. I'd like to integrate the network follower score into the browser extension to complement the "value per feed" metric, but I'm torn about how to move forward on that. I think that's also going to take longer than two weeks.
Maybe I'll let the first release "burn in" for a couple of weeks and shift my attention back to the Steem Conversation Accelerator (SCA) or the wordsearch for a while. I might also look at tag-following in one or both of those extensions. There's a lot that I want to accomplish, but after the unexpectedly quick progress of the last couple weeks, I also feel sort-of aimless at the moment.
Accordingly, I published release v0.3.0 alpha of the Steem Curation Extension. Moving forward, I'll try to establish some semblance of a release model for that tool. I guess it will stay in "alpha" or "beta" until such time as I eventually figure out how to get it into the Google Chrome store, at which time it will switch to "stable".
As to progress during this interval, to be honest, the aimlessness continues. To use a consulting cliché, it feels like the "low-hanging fruit" has been picked, and the next problems are somewhat daunting. However, I forced myself to pick a direction and start moving, so I will have some words to write about the Steem Curation Extension, the Steem Conversation Accelerator (SCA), and the general problem of measuring the difference between organic and paid voting.
Activity Descriptions
Steem Curation Extension
Personally, I actually made no progress on the Steem Curation Extension. However, @cmp2020 took an interest in it, and started working on his own branch. I'll take the risk of feeding my ego by paraphrasing a spontaneous statement of his, not for self-promotion, but as organic feedback for other developers.
Up until now, @cmp2020 knew that I was working on the curation extension, but with his school and work schedule, he hadn't paid much attention to what it does. However, when he decided to start contributing I showed him how to clone and branch the github repo and he learned a little more about what the extension does. When he did, he made a comment that was something like this,
Steem would have succeeded by now if we'd had development like this all along.
We talked some more about it, and I think what he meant is that this is a tool that's trying to enhance the ecosystem as a social experience, rather than as a cryptocurrency farm. Historically, many of our developers have come from the blockchain/cryptocurrency space, so those aspects of the ecosystem have received much more attention than the "attention economy" portion of the ecosystem - even before HF23.
Obviously, it's not that I'm any kind of great programmer, quite the opposite. What (I think) got his attention was that it's a focus on the end social-user as a stakeholder. I don't want to put words in his mouth, though, so maybe he'll find time to elaborate.
Anyway, I'll let him write about the changes that he's working on in the browser extension when he finds time, but I have stayed hands-off in order to avoid merge conflicts while he's working on his enhancements.
Steem Conversation Accelerator (SCA)
While he was digging into the Steem Curation Extension, I shifted my attention back to the SCA. During this interval, I've been working on adding a capability to follow tags. So far, I've accomplished the following:
- Added a couple simple fields to the popup form in order to add/delete tags that I want to follow. The updated form can be seen below.
- Implemented logic in the background processing to poll tags in top-level posts.
- Accessed the list of tags in the activity list HTML page processing.
- Created locks to prevent data loss between the activity list and the background processing.
Here's what the updated form looks like:
| Tag list down | Tag list up |
|---|---|
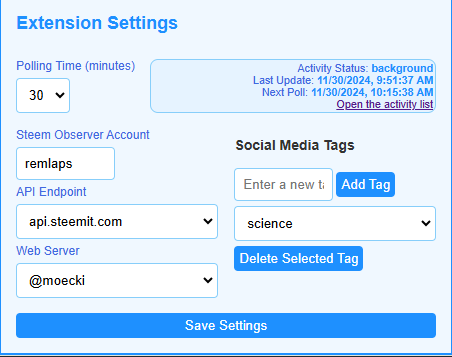 | 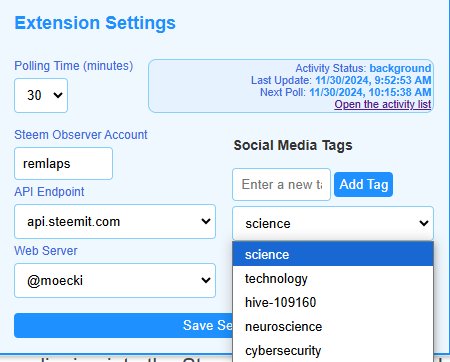 |
Here are some of the things that are still on the to-do list:
- Figure out what the HTML output should look like.
- Add the posts to the activity list page or create a wholly independent page to be launched for followed tags. (not sure how I want to handle that yet)
- Identify when replies are attached to posts in the followed tags and add them to the list.
- Syntax validation for the tags to be followed (string length, case, special characters, etc...)
Unless I've overlooked a relevant call from SDS or the Steem API, this actually seems to be a fairly challenging task. I didn't find an easy way to identify all recent posts and replies for a given tag, so it seems that I need to check tags on every comment. Worse: on the replies, I also need to go back to the root post in order to find the relevant tags.
So, there's some progress there, but there's a lot left to do. I think I'll be lucky if I can publish a working branch before the end of the year.
On the difference between paid and organic votes
To be clear, I am not against paid voting services, per se. I am simply opposed to the overvaluation of content (and undervaluation, too). So my activities in this arena are meant to inform, not to stigmatize. Further, the numbers presented here are preliminary and may be incorrect.
Measuring the scale of paid voting
One of the challenges that I've thought was important for a while is the need to distinguish between organic votes and paid votes, and to measure the usage of vote buying services within the ecosystem. Obviously, no number will ever be perfect, but I think we can come up with estimates that can be useful. Having established a first pass at a paid bot list in the Steem Curation Extension, I was able to start experimenting with measurement. A first try was here. At first blush, it looks like maybe the paid voting services own less than 5% of all SP, but they control more than 37% after factoring in delegations. (subject to the stated caveats... these numbers may not be reliable. This is just a first pass.)
Updating the autovoter
Some years ago, I started a daily download of users who delegated to paid voting services, but I never actually made use of that download. In the last two weeks, I updated that download so that it contains the same list as in the Steem Curation Extension and I also updated the autovoter so that it won't automatically vote for anyone who delegates to a paid voting service.
I also implemented a script to count daily posts and unique authors. I compared this information against the paid vote delegators, and found that roughly 600 of 2000 daily unique authors are posted by voting service delegators. In case you're interested, I'm not doing anything with this information yet, but here's a summary from yesterday:
Post count by depth:
Depth 12: 1
Depth 11: 1
Depth 10: 2
Depth 0: 2205
Depth 1: 3783
Depth 2: 1040
Depth 3: 99
Depth 4: 22
Depth 5: 9
Depth 6: 4
Depth 7: 3
Depth 8: 3
Depth 9: 2
Total: 7174
Total unique authors: 1971
The problem is hard
Of course, beyond delegation services, there are other ways that votes can be paid for. They can be paid with STEEM/SBD transfers, transfers of external currencies/cryptocurrencies, and I even found at least one service where Steem votes are being rewarded in exchange for burning an external cryptocurrency.
We can automatically identify a large portion of it by looking at SP delegations, but even if we managed to identify that perfectly, other forms of vote buying would be more challenging to identify.
I have thought before about the possibility of using something modeled after the fraud department in traditional finance that would maintain white lists and black lists. Another possible solution is modeled after quorum sensing in bacteria, but it would require a much higher number of minnows and dolphins than we see today or else backing from one or more top-tier stakeholders. And of course, funding is a perpetual challenge for either approach.
Artificial Intelligence
One last topic before I move on, as posted in The future of programming languages is English, I have begun playing with the free version of ChatGPT-EasyCode in my vscode IDE. This feels like a big improvement over using AI assistants by copy/paste between windows.
Previously, I also experimented with Replit, but that felt like a force-fit for browser extensions, so I abandoned it pretty quickly.
Looking Ahead / Next Steps
There are basically no changes in my long-term plans. Three browser extensions plus my collection of scripts, spreadsheets, PowerBI visualizations, and so on are all more than enough to keep this spare-time hobbyist busy for the foreseeable future.
Short term, I expect to continue working on the tag-following capability in the SCA for (at least) the next one or two intervals.
I can already see that time is tight, so progress during the coming interval may be slow.
Also, Developer Delegation Day is coming up on Thursday. I actually have a pretty full schedule that day, so I might enter my delegations on Wednesday. If you want to say "Thank you" to the developers who create the free Steem-related tools that you use, a 5 SP delegation on the 5th of each month is a simple way that you can do it.
Reflections
Yesterday, I posted about Steem's Two Halvings that will happen between 2026 and 2037. Beyond what I wrote yesterday, it's interesting to think about how this fits into the current BTC halving cycle.
In the past, the 4-year BTC cycle has led to increases in the price of STEEM during the following year - in the current case, 2025. So, if history repeats, then Steem will be entering its own 11 year double-halving phase in the year following the BTC bull-run boost. I'm definitely interested to see how the interplay between these two macro-events (along with potential BTC bull-boosts in 2029, 2033, and 2037, all within Steem's double-halving phase).
And of course, if the price of STEEM rises far enough above the haircut threshold, it's conceivable that there might even be close to 3 halvings. Two is a minimum. I don't know what the future brings, but my guess is that it will be somewhat different from what we've seen in the past.
Also, with the current price of STEEM at $0.268, if it doesn't fall back below $0.261 then we should see SBDs start paying out with posts within the next half-day or so. With the 2025 and 2026 dynamics in play, could this be STEEM's last time below the haircut threshold? Probably not, I guess, but maybe not impossible?
Conclusion
This post reviewed recent activity in the Open Source Steem browser extensions that I have launched as well as some efforts towards measuring the levels of organic vs. paid voting. Long and short term plans are simply to continue efforts on these tools. And, of course, as with any Open Source initiative - I invite participation from others.
In addition to those topics, this entry also followed up on yesterday's post with some additional thoughts about the future interplay of BTC and STEEM halvings.
Finally, I invite everyone to join participation in the Developer Delegation Day for December. The idea is to give a 5 SP delegation on the 5th of each month as a way of saying thank you to the developers who create free tools for use in the Steem ecosystem.
Thank you for your time and attention.
As a general rule, I up-vote comments that demonstrate "proof of reading".

Steve Palmer is an IT professional with three decades of professional experience in data communications and information systems. He holds a bachelor's degree in mathematics, a master's degree in computer science, and a master's degree in information systems and technology management. He has been awarded 3 US patents.


Pixabay license, source
Reminder
Visit the /promoted page and #burnsteem25 to support the inflation-fighters who are helping to enable decentralized regulation of Steem token supply growth.
Maybe I'm misunderstanding what you mean, but it seems like there would have to be an API call to get posts with a tag ordered by "created" since that's something we can do via the condenser UI. (Unless the complicating factor is the "and replies" part, but are there guaranteed to be meaningful tags on replies?).
Yes. That (and the perception that those type of people know how to do "real" crypto dev work) has also led to a lot of the development activity being focused on trying to re-implement fads from other chains (NFTs, etc.) rather than working to develop the unique properties of this one. I think it also creates an expectation that the solution to the lack of dev work here is to wait for an outsider to swoop in rather than trying to cultivate the social environment here to be supportive. (For example, I would be willing to do more dev work here if 1. it didn't feel like I was mostly shouting into the void and 2. I could make enough money off of it that I could justify the time and energy it would take).
0.00 SBD,
0.00 STEEM,
13.85 SP
That is really difficult. I can only justify it by defining it as an "expensive hobby". :-)
0.05 SBD,
0.10 STEEM,
0.26 SP
Yeah, it's the "and replies" part that complicates it. Most replies don't have meaningful (or any) tags. So, I'm going to look at the root post of all comments during the interval and get tags from that. Unfortunately, it's not enough to just look for replies on all posts that were submitted during the interval because replies can be attached to posts that were submitted earlier. If I just wanted posts, it would be simple, but I want the browser extension to find everything under a tag at all depths during the interval.
I suspect that the regulatory environment has been a big obstacle to development investment during the last 4 years, too. I'm hoping (🤞) that maybe we'll see more activity after January 20. We'll see.
0.04 SBD,
0.09 STEEM,
0.21 SP
Have you seen the request getCommentsByTagCreated for comments with certain tags? But I think only the tags explicitly set in the comment are taken into account there too.
Did I understand you (and @danmaruschak) correctly that you want the comments on the posts with a specific tag returned?
0.23 SBD,
0.49 STEEM,
1.24 SP
Thanks! I didn't look at it carefully yet, but I think I experimented with that a few days ago. Maybe the challenge was that it only looks at the first tag(?). Not sure, I will look at it more carefully.
Exactly, if I'm following the "science" tag, and someone uses that tag in a top-level post then I want to get notified of the post and all replies below the post - regardless of whether or not the reply also used the "science" tag. Ideally, I'd repeat that process with tags in lower level posts, but I think that might require too much computation.
0.00 SBD,
0.01 STEEM,
0.02 SP