Apply Data Deduplication
At one of my clients, we recently encountered the problem that our users could not write data on the files of the FileServer. After a small inspection, this also turned out to be the case, there was hardly anything left to save. Because the client's data center has been hosted by a hosting party, we were unable to switch so quickly that we immediately chose a physical disk extension.
A quick cleanup action proved to be the only action we could apply. Unfortunately, this gave only a few Gb's free space. You understand that for a few hours there is a solution. But in order to apply a suitable solution, we decided to use a Windows Server 2012 build-in functionality, File Deduplication.
What is Deduplication
Data deplication has only been introduced in Windos Server 2012. Deduplication is a technique whereby the OS will search and delete duplicate data without adjusting its reliability or integrity. This technique can be applied to many parts / functionality, including Fileservers, Deployment Shares, VDI, Backup etc.
The purpose of this application is to save more data on less space, searching for duplicate data blocks, and maintaining 1 copy, removing duplicate blocks and replacing them for a reference to an earlier (original) copy.
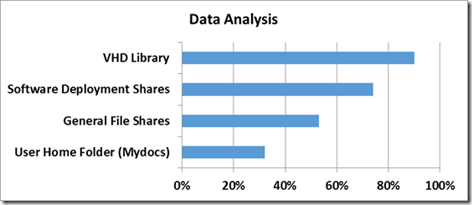
Possible savings on different types of data
In this blog, I will show you how to install and configure this application.
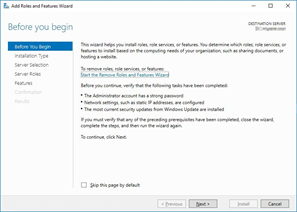
Open the "Add Rolls and Features" from the Server Manager
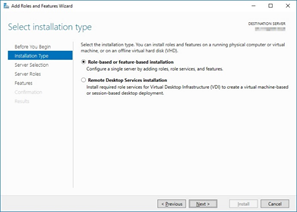
Leave the default on "Role Based ..." and click next
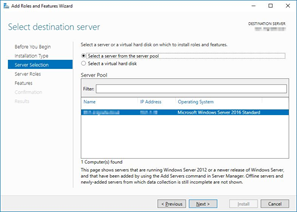
Select the server you want to install
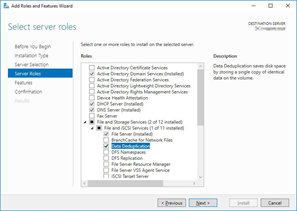
Click File and Storage Services, click File and iSCSI Services, then check the Data Deduplication check box.
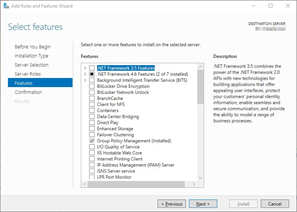
At Features, you do not have to install anything, then click on next.
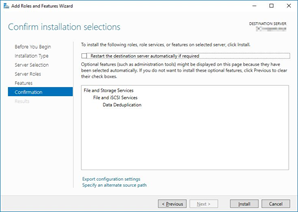
Then click Install
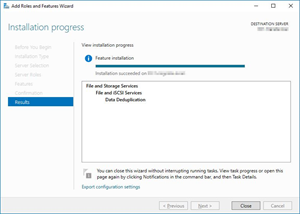
After the installation is completed click close to complete the installation.
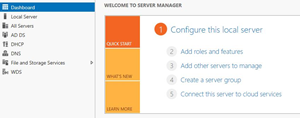
Open the Server Manager and go to File and Storage Services

Then click on the volume where you want to find the deduplication in place. (However, the OS volume is not available for deduplication)
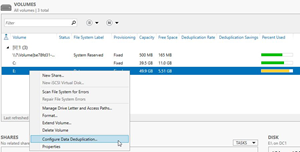
Right mouse click on the volume where you want to take the deduplication and select "Configure Data Deduplication".
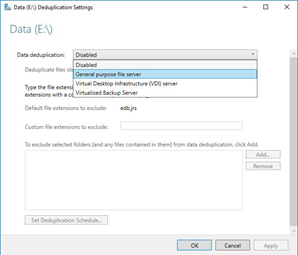
In this next venster you can specify which type of dedupliction you want to apply. You can then indicate when the deduplication will start (files over x days). There is also the possibility of unlocking some externals and folders of deplicaction.
And as a last option, the deduplication can also be planned in an expanded schedule.
In this example, I show you the effect of deduplication on a volume of 50 Gb. The content of the data varied largely. In a larger production environment, the supply of files is bigger, but I'll show you this purely for demonstration.
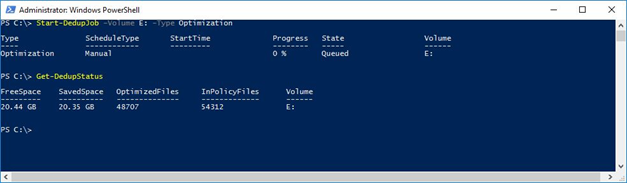
After configuring the deduplication this will not start immediately. To start this haphazardly, you can start the following commands in the powerhouse.
Start deduplication;
Start-DedupJob –Volume E: –Type Optimization

Get Status;
Get-Dedupstatus
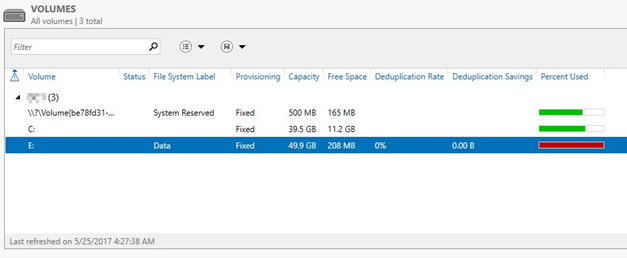
The final result is also available in the Server Manager

As you can see, a substantial profit has been booked. In this example, 79% of space has been recovered. Not only in the case of direct storage, space has been won but this will also work through backup.
What has been observed in this application is that much space can be gained in the short term. Also, the option to unlock several leaflets is a plus. In this way, another solution can be explored, for example, to expand the hardware in a moderate amount of disk capacity.
See you at the post!