Spark Connect 소개 - 어디에서나 Apache Spark의 힘
지난 주 Data and AI Summit에서 우리 는 오프닝 기조연설에서 Spark Connect라는 새로운 프로젝트 를 강조 했습니다. 이 블로그 게시물은 프로젝트의 동기, 높은 수준의 제안 및 다음 단계를 안내합니다.
Spark Connect는 DataFrame API 및 해결되지 않은 논리적 계획을 프로토콜로 사용하여 Spark 클러스터에 대한 원격 연결을 허용하는 Apache Spark용 분리된 클라이언트-서버 아키텍처를 도입합니다. 클라이언트와 서버가 분리되어 있어 Spark와 개방형 에코시스템을 어디에서나 활용할 수 있습니다. 최신 데이터 애플리케이션, IDE, 노트북 및 프로그래밍 언어에 내장될 수 있습니다.
동기 부여
지난 10년 동안 개발자, 연구원 및 대규모 커뮤니티는 Spark를 사용하여 수만 개의 데이터 애플리케이션을 성공적으로 구축했습니다. 이 기간 동안 최신 데이터 애플리케이션의 사용 사례와 요구 사항이 발전했습니다. 오늘날 응용 프로그램 서버에서 실행되는 웹 서비스, 노트북 및 IDE와 같은 대화형 환경에서 스마트 홈 장치와 같은 에지 장치에 이르기까지 모든 응용 프로그램은 데이터의 힘을 활용하기를 원합니다.
Spark의 드라이버 아키텍처는 스케줄러, 옵티마이저 및 분석기 위에서 클라이언트 애플리케이션을 실행하는 모놀리식입니다. 이 아키텍처는 이러한 새로운 요구 사항을 해결하기 어렵게 만듭니다. SQL 이외의 언어에서 Spark 클러스터에 원격으로 연결하는 기본 제공 기능이 없습니다. 현재 아키텍처 및 API는 응용 프로그램이 REPL에 가깝게(예: 드라이버에서) 실행되어야 하므로 일반적으로 노트북 에서 수행되는 대화형 데이터 탐색에 적합하지 않거나 최신 IDE에서 일반적으로 사용되는 풍부한 개발자 경험을 구축할 수 없습니다. . 마지막으로 JVM 상호 운용성이 없는 프로그래밍 언어는 오늘날 Spark를 활용할 수 없습니다.
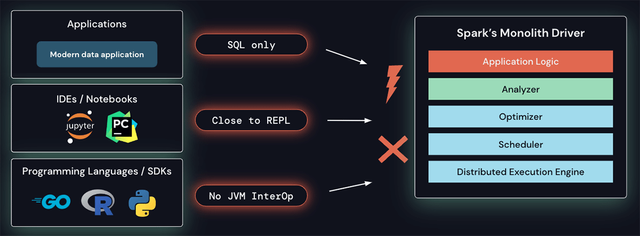
Spark의 모놀리식 드라이버에는 몇 가지 문제가 있습니다.
또한 Spark의 모놀리식 드라이버 아키텍처는 다음과 같은 운영상의 문제도 야기합니다.
- 안정성: 모든 애플리케이션이 드라이버에서 직접 실행되기 때문에 사용자는 모든 사용자의 클러스터를 중단시킬 수 있는 중요한 예외(예: 메모리 부족)를 유발할 수 있습니다.
- 업그레이드 가능성: 현재 플랫폼과 클라이언트 API의 얽힘(예: 클래스 경로의 자사 및 타사 종속성)은 Spark 버전 간의 원활한 업그레이드를 허용하지 않아 새로운 기능 채택을 방해합니다.
- 디버깅 가능성 및 관찰 가능성: 사용자는 기본 Spark 프로세스에 연결하기 위한 올바른 보안 권한이 없을 수 있으며 JVM 프로세스 자체를 디버깅하면 Spark에서 설정한 모든 보안 경계가 해제됩니다. 또한 자세한 로그 및 메트릭은 애플리케이션에서 직접 쉽게 액세스할 수 없습니다.
스파크 연결 작동 방식
이러한 모든 문제를 극복하기 위해 Spark용 분리형 클라이언트-서버 아키텍처인 Spark Connect를 도입했습니다.
클라이언트 API는 애플리케이션 서버, IDE, 노트북, 프로그래밍 언어 등 어디에나 내장할 수 있도록 얇게 설계되었습니다. Spark Connect API는 클라이언트와 Spark 드라이버 간의 언어 독립적 프로토콜로 해결되지 않은 논리적 계획을 사용하여 Spark의 유명하고 사랑받는 DataFrame API를 기반으로 합니다.
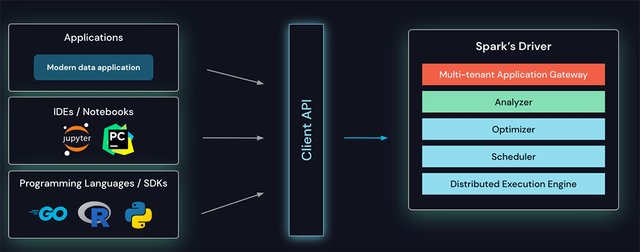
Spark Connect는 Spark용 클라이언트 API를 제공합니다.
Spark Connect 클라이언트는 DataFrame 작업을 프로토콜 버퍼를 사용하여 인코딩된 미해결 논리적 쿼리 계획으로 변환합니다. 이들은 gRPC 프레임워크를 사용하여 서버로 전송됩니다. 아래 예 에서 로그 테이블에 대한 일련의 데이터 프레임 작업( 프로젝트, 정렬, 제한 ) 은 논리적 계획으로 변환되어 서버로 전송됩니다.
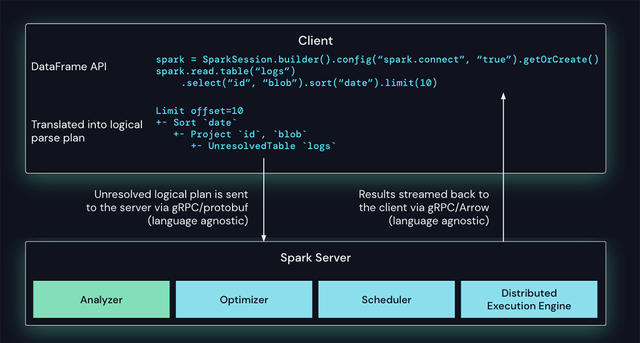
Spark에서 Spark Connect 작업 처리
Spark 서버에 내장된 Spark Connect 엔드포인트는 미해결 논리 계획을 수신하여 Spark의 논리 계획 연산자로 변환합니다. 이는 속성 및 관계가 구문 분석되고 초기 구문 분석 계획이 작성되는 SQL 쿼리 구문 분석과 유사합니다. 여기에서 표준 Spark 실행 프로세스가 시작되어 Spark Connect가 Spark의 모든 최적화 및 개선 사항을 활용하도록 합니다. 결과는 Apache Arrow로 인코딩된 행 배치로 gRPC를 통해 클라이언트로 다시 스트리밍됩니다.
다중 테넌트 운영 문제 극복
이 새로운 아키텍처를 통해 Spark Connect는 오늘날의 운영 문제를 완화합니다.
- 안정성: 너무 많은 메모리를 사용하는 응용 프로그램은 이제 자체 프로세스에서 실행할 수 있으므로 자체 환경에만 영향을 미칩니다. 사용자는 클라이언트에서 자신의 종속성을 정의할 수 있으며 Spark 드라이버와의 잠재적인 충돌에 대해 걱정할 필요가 없습니다.
- 업그레이드 가능성: 이제 Spark 드라이버를 애플리케이션과 독립적으로 원활하게 업그레이드할 수 있습니다(예: 성능 개선 및 보안 수정의 이점). 이는 서버 측 RPC 정의가 이전 버전과 호환되도록 설계된 한 응용 프로그램이 이전 버전과 호환될 수 있음을 의미합니다.
- 디버깅 가능성 및 관찰 가능성: Spark Connect를 사용하면 즐겨 사용하는 IDE에서 직접 개발하는 동안 대화형 디버깅이 가능합니다. 마찬가지로 애플리케이션의 프레임워크 기본 메트릭 및 로깅 라이브러리를 사용하여 애플리케이션을 모니터링할 수 있습니다.
다음 단계
Spark 개선 프로세스 제안 이 커뮤니티에서 투표 를 통해 승인되었습니다. 향후 Apache Spark 릴리스 중 하나에서 Spark Connect를 실험적 API로 사용할 수 있도록 커뮤니티와 협력할 계획입니다.
우리의 초기 초점은 이 새로운 API로 원활하게 전환할 수 있도록 PySpark에 DataFrame API 범위를 제공하는 것입니다. 그러나 Spark Connect는 Spark가 다른 프로그래밍 언어 커뮤니티에서 보다 유비쿼터스가 될 수 있는 좋은 기회이며 Spark Connect 클라이언트를 다른 언어로 가져오는 데 기여할 수 있기를 기대합니다.
나머지 Apache Spark 커뮤니티와 협력하여 이 프로젝트를 개발하기를 기대합니다. Apache Spark에서 Spark Connect의 개발을 팔로우하려면 [email protected] 메일링 리스트를 따르거나 이 양식 을 사용하여 관심을 제출하십시오 .
[광고] STEEM 개발자 커뮤니티에 참여 하시면, 다양한 혜택을 받을 수 있습니다.