머신러닝] 머신러닝 간단 정리
한창 구글의 DeepMind 사의 알파고와 한국의 이세돌 선수가 대국을 치룬 시기가 2016년이니, 벌써 2년이나 지난 일이 되었습니다.
제 기억상으로 그 때가 가장 한국에서 인공지능이 언론에 많이 노출되고 사람들의 관심도 받았던 때인 것 같습니다.
저도 그때 쯤 수박 겉핥기 식으로만 인공지능에 대해 접하곤 했는데, 처음 접할 경우 정리가 필요한 부분이 많던 것 같습니다.
새로운 용어들이 많이 등장했으니까요. 특히 인공지능의 토대가 되는 머신러닝에 대해 그러했습니다.
그래서 이번 글에서는 머신러닝의 개념을 정리해보고자 합니다.
가끔 언론 뉴스나 포스팅을 보면, 인공지능/딥러닝/머신러닝 이를 섞어 쓰는 경우가 많습니다.
하지만 이 셋은 명백하게 다른 의미로 세 단어의 의미차이를 아는 것도 중요합니다. 이 셋은 부분집합의 관계를 갖습니다.
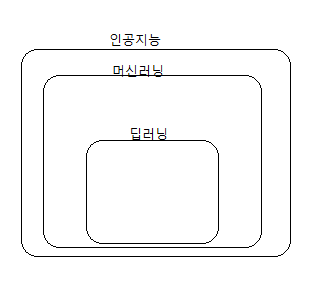
위와 같은 형태입니다. 즉, 딥러닝은 머신러닝의 종류 중 하나이며 머신러닝이 인공지능의 종류입니다.
인공지능의 의미는 가장 포괄적입니다. 인간의 지능을 컴퓨터에 구현하는 기술을 총칭합니다.
그리고 이러한 인공지능을 구현하기 위한 방법 중 하나가 머신 러닝입니다. 마지막으로 이러한 머신러닝 기법 중 하나가 딥러닝 입니다.
인공지능을 구현하는 머신러닝 분야에서는 많은 기법이 있고, 최근 몇년 들어 좋은 성과를 내는 기법이 되어 세간의 주목을 받은 것 입니다.
간단하게 세 단어의 의미에 대해 정리를 해보았습니다. 이제 머신러닝의 의미에 대해 정리해보겠습니다.
우선 머신러닝(Machine Learning)은 한국어로 기계학습입니다. 즉, 말그대로 기계(컴퓨터)가 학습을 하는 기법입니다.
조금 더 부연 설명하면 "데이터에서 모델을 찾아내는 기법"입니다. 여기서 모델이란 기계의 학습을 통해 얻어낸 최종 결과물을 의미합니다.
기계에게 이 데이터 가지고 알아서 공부해오라고 하면 혼자서 분석하여 적합한 모델을 갖는 결과물을 내놓는 것 입니다.
머신러닝에 대한 가장 친숙한 예시로는 이메일 스팸 필터링입니다. 이메일 스팸 필터링은 어떻게 진행하는 것 일까요?
가장 간단한 방법을 생각해보면, 글 내에 스팸이 될만한 단어들이 있으면 이를 스팸으로 분류하는 것 입니다.
하지만 여기에는 당연히 오점이 있습니다. 광고 문구를 조금 변형해버리면 이를 인지하지 못합니다.
예시로 광고 -> 광123고 라고 적으면 이해하지 못하는 것 처럼 말입니다.
하지만 사람은 이 메일이 스팸 메일이라는 것을 이해합니다. 스팸의 내용적인 특성을 이해할 수 있기 때문입니다.
그래서 사람처럼 이메일 내에서 스팸이라고 생각되는 특성들을 찾아내 이를 분류해내는 것이 머신 러닝입니다.
스팸의 예시가되는 글들과 아닌 글들을 컴퓨터에게 주고 이 특성을 학습시키면 이메일 내에서 스팸을 분류하는 모델을 만들게 되는 것 입니다.
이 예시 외에도 머신러닝 기법은 언어 번역/영화 추천/자율주행차량 등 다양한 분야에서 널리 사용되고 있습니다.
머신러닝은 세 가지 큰 틀로 나눌 수 있습니다.
학습 방식에 따라서 지도 학습 (Supervised Learning) - 비지도 학습(Unsupervised Learning) - 강화 학습(Reinforcement Learning)로 분류할 수 있습니다.
지도 학습은 [데이터-답] 쌍의 데이터를 구성하여 가르치는 기법입니다. ' "강아지 사진(데이터)"을 주며 "이 것은 강아지(답)"이다 ' 라고 알려주고 이를 통해 강아지를 분류하는 모델을 만드는 것 입니다.
비지도 학습은 데이터만 넣고 학습하는 기법입니다. 비지도 학습은 주로 데이터의 군집화를 생각하면 됩니다. 특정 유형의 집단을 분류하는 방법입니다. 지도 학습과 달리 정답 없이 맨 땅에 헤딩하며 배우는 것이지요.
강화 학습은 [입력,출력,평가] 세 가지의 데이터를 사용하는 기법입니다. 학습 과정에서 평가를 더 높이는 방향으로 학습합니다. 알파고와 같이 보통 게임에서 점수를 얻는 방식으로 진행하라고 명령하면 점수를 얻는 방향으로 학습을 진행합니다.