머신러닝] AdaBoost 란
기계학습 中 분류 알고리즘 종류
- Kernel discriminate , Neural Network , Support Vector Machine(SVM) , Random Forest , Boosting ...etc
이 중 Adaboost는 Boosting 알고리즘의 한 종류로서, Adaptive Boosting 의 약자이다.
한 줄 설명으로 Adaboost는 가중치를 부여한 약 분류기(Weak Classifier)를 모아서 최종적인 강 분류기(Strong Classifier)를 생성하는 기법이다.
즉, 1명의 뛰어난 인재보다 10명의 평범한 사람이 모여 문제를 푸는데 더 효과적이라는 것이다.
훈련 과정에서 모델 능력을 향상시키는 특성들을 골라 선택하며, 이를 통해 실시간 처리에서 속도 개선을 돕는다.
Adaboost의 경우, 다음 학습 과정에서 각각의 샘플들에 대해 가중치를 두고 모델링을 하여 다음 학습시 이전에 처리하지 못한 샘플들을 adaptive하게 더 잘 풀도록 개선하는 특성이 있다. 그래서 Adaptive Boosting 인 것
약분류기의 예시로는 Haar-like Feature , HOG 등 여러 특성이 있다.

[Adaboost 알고리즘]
1. 모든 입력 샘플들에 대해서 학습 대상인지 or 아닌지 라벨링을 한다. (1 == positive / -1 == negative)
2.모든 샘플들에 대해서 각각 negative / positive 샘플의 수는 m/ l 일때 가중치를 1/2m , 1/2l로 초기화 한다.
3. T번만큼 아래 알고리즘을 반복한다. 이때 T는 최종 Weak Classifier의 수이다.
-가중치의 합이 1이 되도록 모든 w에 대해 정규화한다.
-모든 샘플에 대해 약분류기들의 에러값을 계산한다.
-에러값이 가장 작은 Feature를 약분류기(g(x))로 정의한다.
-B= E / (1-E) 값을 구한 후, W=W*B^(1-e) 로 가중치를 갱신해준다. * e= 1 or 0 , E=오분류율
4.위 학습과정을 거쳐 최종적으로 선택된 약분류기들의 합인 강분류기를 구한다.
만약 G(x) = 1일때, G(x) = (a1*g1) +(a2*g2) + ... + (at*gt) 이다. *a = log(1/B)
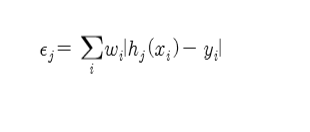
*오분류율 E는 위와 같다.
이러한 강분류기 학습을 위해 약분류기 학습 과정이 필요하다. 약분류기의 생성 방법은 아래와 같다.
T+:모든 positive 학습 데이터들의 가중치 합
T-:모든 negative 학습 데이터들의 가중치 합
S+:threshold 값 아래의 모든 positive 학습 데이터들의 가중치 합
S-:threshold 값 아래의 모든 negative 학습 데이터들의 가중치 합
error = Min( (S+) + (T-) - (S-) , (S-) + (T+) - (S+) )
*Min(a , b) = ( a + b - | a- b | ) /2
*error가 최소 되는 지점을 임계값(threshold)이라고 함.
Ex) -는 negative 샘플 , +는 positive 샘플 (Feature 값 오름차순)
- - - | + - + + - + +
(6,4) (7,3) (8,2)|(7,3) (8,2) ...
4 3 2 | 3 2
이때, Minimum error = 2 이므로 3 ~ 4번째의 값이 약분류기 임계값이다.
이러한 학습 과정을 통해 적은 Feature들을 모아 최종 모델을 생성한다.
다음엔 이러한 약분류기의 예시로 사용되는 것들의 종류도 정리하는게 좋을 것 같다.
*자료는 개인적인 정리 차원에서 쓴 것 입니다. 공부 과정이므로 틀릴 수 있는 부분이 존재합니다.
참고문헌
Robust Real-Time Face Detection , Viola & Jones, 2004
위키피디아, Adaboost 항목