이제 Ollama에서 Llama 3.2 Vision 11B 및 90B 모델을 실행할 수 있습니다.
시작하기
Ollama에서 Llama 3.2 Vision 모델을 사용하려면 먼저 Ollama 0.4 버전 이상이 필요합니다. Llama 3.2 Vision을 사용하기 전에 반드시 Ollama를 0.4 버전으로 업그레이드하거나 새로 설치해야 합니다.
Ollama 0.4를 설치한 후 다음 명령어를 실행합니다:
ollama run llama3.2-vision
llama3.2-vision:90b 모델을 실행하려면:
ollama run llama3.2-vision:90b
프롬프트에 이미지를 추가하려면 터미널에 이미지를 끌어다 놓거나 Linux에서는 프롬프트에 이미지의 경로를 추가합니다.
참고: Llama 3.2 Vision 11B에는 최소 8GB의 VRAM이 필요하며, 90B 모델에는 최소 64GB의 VRAM이 필요합니다.
예제
손글씨
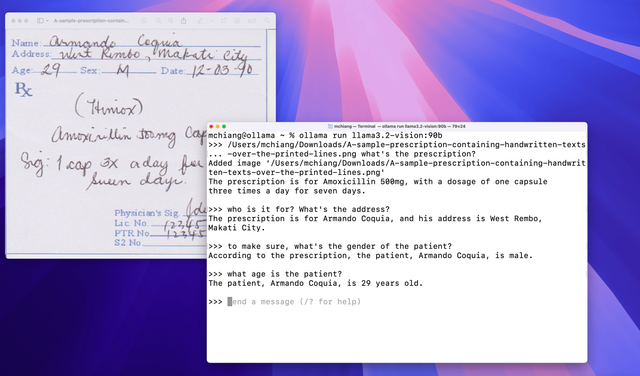
광학 문자 인식(OCR)
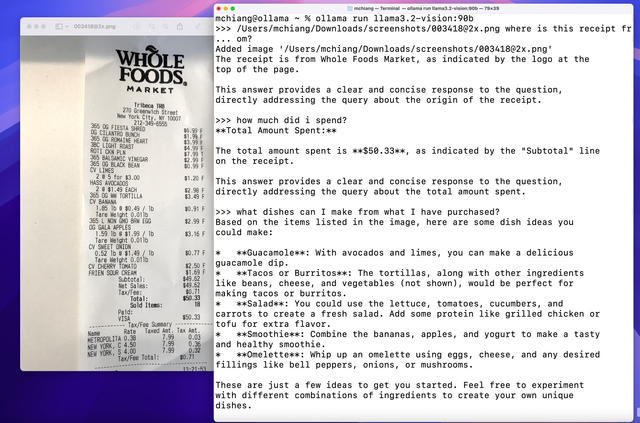
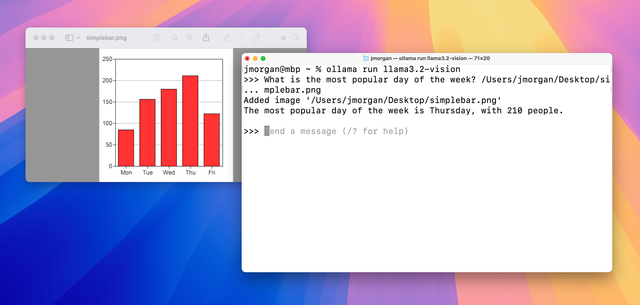
차트 및 표
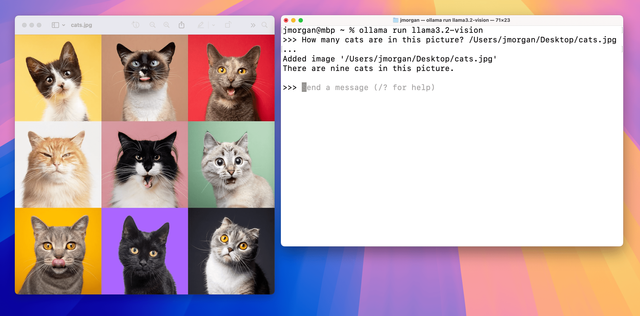
이미지 Q&A
사용법
먼저 모델을 가져옵니다:
ollama pull llama3.2-vision
Python Library
파이썬에서 Llama 3.2 Vision을 사용하려면:
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'What is in this image?',
'images': ['image.jpg']
}]
)
print(response)
JavaScript Library
자바스크립트에서 Llama 3.2 Vision을 사용하려면:
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2-vision',
messages: [{
role: 'user',
content: 'What is in this image?',
images: ['image.jpg']
}]
})
console.log(response)
cURL
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2-vision",
"messages": [
{
"role": "user",
"content": "what is in this image?",
"images": ["<base64-encoded image data>"]
}
]
}'
[광고] STEEM 개발자 커뮤니티에 참여 하시면, 다양한 혜택을 받을 수 있습니다.
Upvoted! Thank you for supporting witness @jswit.