인공지능 - 나이브 베이즈 (Naive Bayes)
- Naive Bayes Classifier
Bayes’ Theorem에 근거한 분류법이며 naïve Bayes 알고리즘은 문서를 통계적 기법을이용하여 클래스를 규정하는 알고리즘이다.

이 남자가 결혼했을까 안했을까를 판단해보자. 사진에서는 자식이라 생각 할 수 있는 아이와 함께있고, 선글라스와 패션모자를 쓰고 있다. 이러한 관찰을 Observation이라 생각하고 이 사람이 결혼 했는지 여부를 Classify하는 것을 Naive Bayes로도 할 수 있다.
우선 이전에 학습한 암진단 문제를 갖고 생각해본다.
X(결과가 양성이다 음성이다),Y(암이 있다 없다) random variable이 있었고 Y가 query variable, x가 observation variable이라 했다.
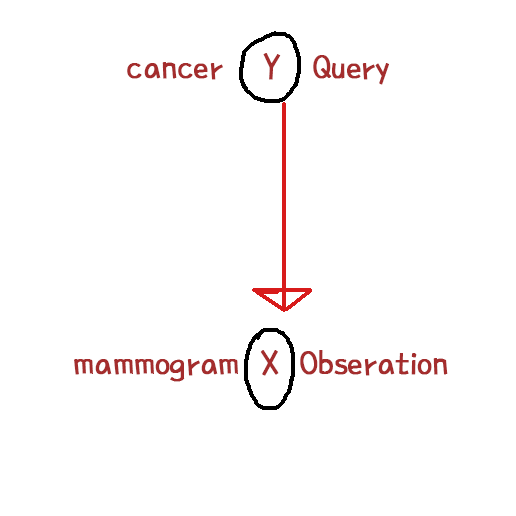
일반적으로 Naive Bayes는 이 Query Variable에서 화살표로 나가서 Observation을 로 가는거고 이게 뜻하는 것은 y random variable 즉, 환자가 암에 걸렸는지갸 mammogram의 결과가 어떻게 되는지에 확률적으로 영향을 준다는 것이다.
그래서 암이 있는 환자의 경우 이 mammogram이 양성으로 나올 확률이 굉장히 높고, 암이 없는 환자의 경우 mammogram이 음성으로 나올 확률이 굉장히 높다는 것 이다. 이런 조건부 확률에 표현을 동그라미와 화살표로 표현 하는 것이 Naive Bayes Classifier이다.
마찬가지로 앞에 나온 남자의 결혼 유무를 사진만 보고 Naive Bayes Classifier을 한다면, 결혼 유무를 query variable로 두고 아이와 함께있다와 패션이 어떤지를 observation으로 둘 수 있다.
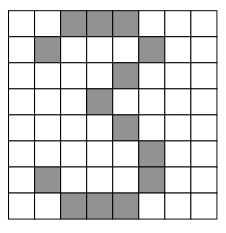
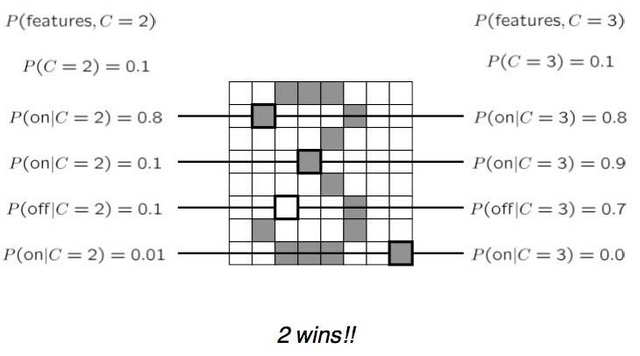
Digit Classifier이다. 우리가 숫자를 0~9까지 분류를 한다면, 위와같이 feature를 만들어서 digit이 input으로 왔을 때, 8x8의 총 64개의 feature로 분할한다.
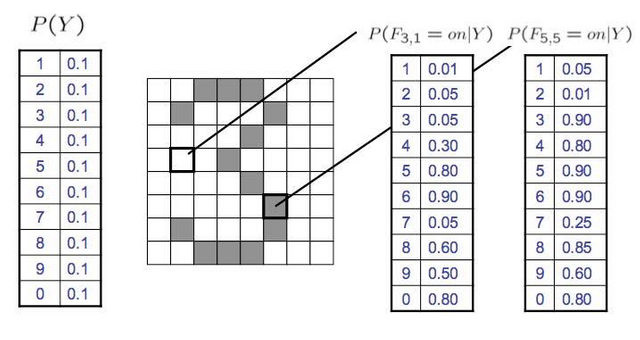
처음 시작 칸을 0으로 마지막칸을 7로둔다, 그럼 위와같으 F(3,1)은 4행 2열의 위치하게 되고 F(3,1) = 0 (흰부분은 0 검은부분은 1로 둔다.)이 된다. 이렇게 구분을 해 두면 어떤 칸이 칠해져 있는지에 따라서 이게 무슨 숫자다라고 분류를 하는 것을 우리가 digit recognition의 classifier, Naive Bayes Classifier라고 볼 수 있다. 이때 각 숫자에 대해서 칸이 칠해진 확률을 정할 수 있는데 위의 P(F(3,1))은 숫자 3의 경우 0.05의 확률로 칠해지고, P(F(5,5))의 경우 숫자 3은 0.90 확률로 칠해진다는 뜻 이다.
이런식으로 y가 이 특정 분류, 카테고리 여기서는 숫자일 때, 이 확률 테이블을 CPT(conditional probability table)이라 하는데, 64개에 대하여 전부 존재한다.
왼쪽의 P(Y)는 prior probability, 또는 class probability라 한다. 이것은 각 숫자를 하나의 class라 보면 1이라는 class에 대한 prior확률은 무엇이냐. 이것은 우리가 무슨 숫자를 쓰냐에 따라서 다르지만, 0~9까지 prior probability, 또는 class probability는 다 똑같이 0.1이다라고 가정한 것 이다.
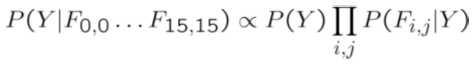
이 query variable에 대하여 y라는 것은 digit recognition에서는 0부터 0, 1부터 9까지 된다. 각각의 class에 대한 확률, 사후확률 posterior probability를 계산해서 가장 높은 class로 분류하는 것이다.
(0,0)에서 (15,15)까지 각 feature가 on이냐 off냐 즉, 칠해져있냐 안 칠해져있냐 그것이 조건이 되고 그 조건이 주어졌을 때 , 각 0에서부터 9까지의 class의 posterior probability이 뭔지 계산을 하면, 그중 가장 높은 값을 고른다는 것 이다. 보통 뒤에 분모 P(F)는 계산하지 않는다. 왜냐하면 이 부분은 모든 class에 대해서 똑같은 값이 나오기 때문이다. 그래서 분자들만 계산하여 Maximum값을 취한다.
likelihood는 각각의 class가 주어졌을 때 이런 feature값들이 나올 확률값을 likelihood라 한다.
Overfitting
Smoothing
실제로 관찰한 것보다 한번씪 더 봤다고 하기

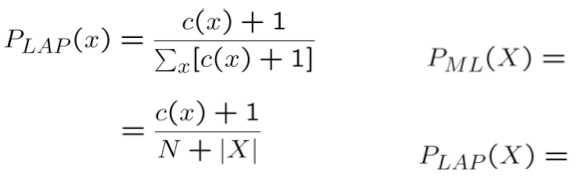
또다시 찾아온 불금!! 힘내세요!!곧 주말이에요!
주말이에요! :)