문과 아재도 쉽게하는 R 데이터 분석 – (11) Naive Bayes
간단하면서도 간단한 나이브 베이즈 분류기
나이브 베이즈는 정말 오래된 방법의 분류기로, 대부분의 스팸 필터가 장착하고 있는 무기이기도 합니다.
예를들어, 이메일로 전송된 정보중 MONEY라는 단어가 등장했을때, 이를 스팸으로 분류해도 되는가에 대한 해답을 제시합니다.
조건부 확률이란?
위의 MONEY라는 단어가 등장했을때, 스팸일 확률을 한번 따져봅니다.
전체 메일중에 MONEY가 발견된 메일은 10%도 채 안될것인데, 일단 MONEY가 발견되었으니, 이건 100% 벌써 발생한 일입니다.
그렇다면 일단 벌어진일, 즉 MONEY가 발견된 확률은 배제하고나서 이 편지가 스팸일 확률만 계산하면 된다는 것입니다.
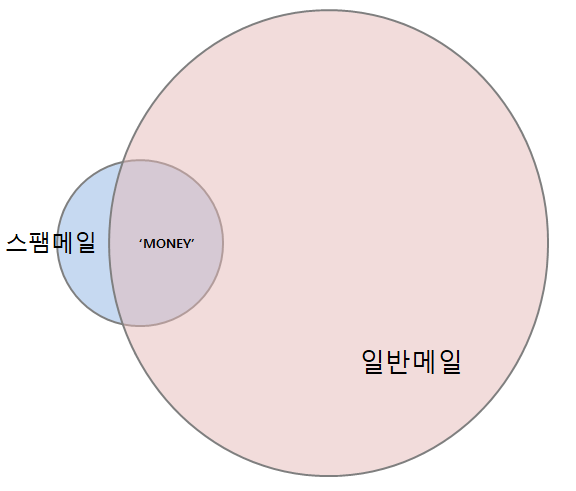
예를들어 위의 그래프를 한번 보면, 일반메일로 오는 메일은 전체적으로 굉장히 많습니다. 그렇지만 MONEY라고 표시된 순간을 확인하면 이 메일은 일반메일보다는 스팸메일에 무게를 두어야 합니다.
이번에는 조금더 복잡하게 자율주행차의 신호등감지를 한번 생각해봅니다.
신호등에 빨간불이 보일때 멈춰야될 상황이 보통 4번, 멈추지 말아야 될 상황이 1번
신호등에 초록불이 보일때 멈춰야될 상황이 보통 16번, 멈추지 말아야 될 상황이 79번
라고 한다면, 어떤 상황에서 차가 멈췄다면, 이는 빨간불일 확률이 많을까요? 초록불일 확률이 많을까요?
당연히 보통같으면 빨간불이라고 대답하겠지만, 차가 멈춘다는 사실은 이미 일어난 사실입니다.
초록불이 켜져있는 시간이 훨씬 많다면, 오히려 위와같은 상황은 초록불일 확률이 16 대 4로 우세합니다. 즉, 80퍼센트라는 것입니다. 이는, 아까 스팸메일과는 다르게 일반적으로는 항상 초록불이 켜져있어서 모수 자체가 크기 때문에 심지어는 차가 멈추더라도 초록불이였을 확률이 더 큰겁니다.
여러개의 조건이 동시에 있다면?
그렇다면 여러개의 사건이 서로 맞물려 여러개가 돌아가고 있는 상황에서의 사후확률은 어떻게 될까요? 예를들어, 신호등의 색 뿐만 아니라 치매가 있으신 할머니가 횡단보도 끝에 걸터앉아 있는 경우, 무단횡단지역인지 여부, 철도건널목인 경우 등 말이죠.
Naive라는 뜻은 순진하다는 뜻으로 그저 모든 각각의 상황을 서로 영향을 주지 않는 독립적인 사건이라고 일단 가정한다는 뜻입니다. 여기서는 각각 따로 확률을 계산해서 사후확률을 계산하고 이를 분류기에 가져다가 씁니다.
투표를 해보자
예를들어 어떠한 정책 사안에 몇가지 대해 투표한 정당의 의원들이 있을수도 있습니다.
그렇다면 어떤 정책에 반대 혹은 찬성을 했는지에 따라 정당을 골라낼수 있을까요?
즉, 반대 혹은 찬성을 했는지 각각 알면 이를 근거로 데이터를 구분할수 있습니다.
다만, 나이브 베이즈는 순진하게도 한 정책에대해 반대를 하는것이 다른 정책에 대해 찬성을 하는것에 대한 상관이 없다고 가정합니다.
즉, 국회의원은 그냥 정책하나하나마다 자신의 소신을 가지고 목소리를 낸다고 가정하는것입니다.
하지만 현실은 동료 의원들의 눈치를 보기도 하고, 어떤 사안에 대해 일관성을 가지려 계속적으로 반대하는 경우도 있기는 하겠죠.
data(HouseVotes84, package = "mlbench")
model <- naiveBayes(Class ~ ., data = HouseVotes84)
model
Naive Bayes Classifier for Discrete Predictors
Call:
naiveBayes.default(x = X, y = Y, laplace = laplace)
A-priori probabilities:
Y
democrat republican
0.6137931 0.3862069
Conditional probabilities:
V1
Y n y
democrat 0.3953488 0.6046512
republican 0.8121212 0.1878788
V2
Y n y
democrat 0.4979079 0.5020921
republican 0.4932432 0.5067568
나이브 베이즈를 통해 훈련된 모델은 각자의 조건부 확률을 계산하게 됩니다. 즉 V1에 투표한 사람이라면 그사람이 보수당 혹은 진보당일 경우에 대해 각각의 확률을 계산한다는 것입니다.
라플라스 추정기
라플라스 추정기를 달아볼수있는데, 이는 중간에 0이 껴들어가 모든 확률을 0으로 만들어버리는것에 대한 방지책이므로 꼭 해주는것이 좋습니다.
model <- naiveBayes(Class ~ ., data = HouseVotes84, laplace = 3)
pred <- predict(model, HouseVotes84[,-1])
table(pred, HouseVotes84$Class)
pred democrat republican
democrat 237 12
republican 30 156
비교적 정확하게 골라내는것을 알수있습니다. 베이즈 추정기는 구분하는 문제에 있어 활용할수 있다는것을 알수있었습니다. 만약 수치데이터를 통해 구별해야한다면, 자동적으로 수치데이터를 클래스를 구별해줘서 낮음, 중간, 높음 등의 라벨을 붙여줘야하는 작업을 해줘야 할수 있습니다.
베이즈 분류기 나이브 베이즈 관련 내용 얘기네요.행복은 내가 찾는 것이란 것이 기억에 남네요. 이렇게 또 하나 찾아갑니다~!