문과 아재도 쉽게하는 R 데이터 분석 – (5) 로지스틱 회귀(Logistic Regression)
로지스틱 회귀로 성별 판별하기
눈크기와 눈의 형태만 가지고 성별을 판단할수 있을까요? 우리가 흔히 생각하는 여자의 눈은 좀더 크고 반달에 가까운데 반해 남자의 눈은 좀더 찢어지고 작은 편입니다. 그렇다면 정말 차이가 존재할까요? 만약 차이가 존재한다면, 눈의 형태로 혹시 성별을 판단할수 있을지 확인해봅시다.
로지스틱회귀란?
로지스틱 회귀는 이진형 사건의 발생확률을 예측해줍니다. 예를들어 특정한 얼굴형태를 가진 사람들은 과연 여자일까요? 남자일까요? 혹은 자율주행 자동차는 왼쪽에 가야할까요 오른쪽으로 가야할까요? 이러한 상황에 맞춰 통계적인 확률값을 내주는것을 로지스틱회귀라고 합니다. 모든 값들은 0~1 즉, 0% 와 100%사이에 있으며 각각의 테스트 데이터는 특정한 확률을 가질수 있습니다. 51%정도의 확률이 된다면 애매하기는 하지만 어쨌든 50%보다는 크긴 크므로 뭔가 구별을 할수는 있는 상황입니다. 물론 90%가 넘어가는 데이터에 대해서는 거의 확실시 하며 그렇다고 할수도 있겠죠.
로지스틱 회귀는 앞에서 살펴보았던 일반적인 회귀와는 조금 다릅니다. 그 결과가 수치가 아니라 0~1을 가지는 확률이 나와야하기 때문입니다. 따라서 아래와 같은 glm() 함수를 호출하여야합니다. Generalized Linear Model인데, lm이 각각의 독립변수가 정규분포를 따른다고 가정하는 특수한 상황이라고 가정했을때, glm()은 몇가지 파라미터를 통해 조금더 일반화된 상황에서의 회귀 모델을 도출하게 해줍니다.
m <- glm(gender ~ size + width, family = binomial)
위에서 볼수있는건 binomial이라는 옵션을 추가로 준것을 확인할수있습니다.
아직 실제 데이터로 glm을 돌리기전에 실제적으로 gender별 눈크기가 차이가 있는지 살펴보는것도 의미가 있을것 같습니다.
데이터 불러오기
data 는 mr-go.com/image/data/face.csv 에 있습니다.
이 데이터를 가지고 데이터를 불러오고, 훈련 데이터와 테스트데이터로 나눠봅니다.
data <- read.csv("labeled.csv")
일단 성별 평균은 다른가?
t.test(
data[gender == "male",c("c_eye_left_size")] ,
data[gender == "female",c("c_eye_left_size")]
)
Welch Two Sample t-test
data: data[gender == "male", c("c_eye_left_size")] and data[gender == "female", c("c_eye_left_size")]
t = -21.077, df = 2050.2, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.364413 -1.132120
sample estimates:
mean of x mean of y
5.436620 6.684886
t.test는 실제로 평균이 다른지 확인해볼수 있는 요긴한 함수입니다. 대립가설은 평균의 차이가 있다는것인데, 실제로 남녀 평균의 차이가 있군요. p-value값도 유의미하구요. 여자가 평균적으로 눈이 정말 큰걸까요? 그렇다면 이제 본론으로 들어가서 눈 자체로 한번 판별을 해봅시다.
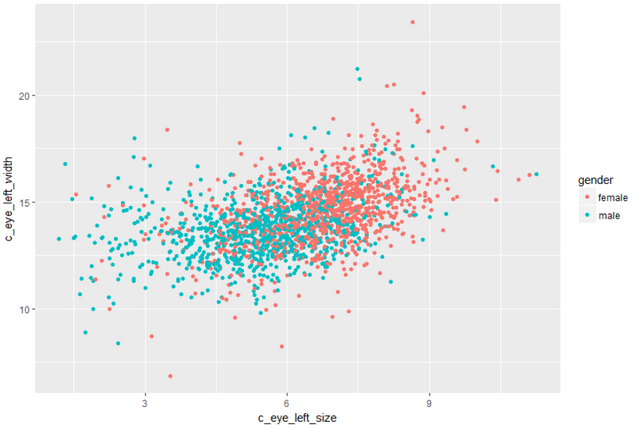
실제로 성별대로 추출하기
실제 sample()함수보다 더 강력하게 데이터를 나눌수 있는 함수가 유용한caret패키지에 제공되고 있습니다. caret은 Classification And REgression Training의 약자를 맞추려 억지를 부린느낌은 있지만, 데이터를 분할하고 전처리하는데 특화되어있는 패키지입니다.
아래와 같이 샘플링할 인덱스를 추출하여,
index<-createDataPartition(y=data$gender, p=0.8, list=FALSE)
그 인덱스를 사용해 데이터를 나눠줍니다.
train <- data[index,]
test <- data[-index,]
모델 훈련하기
m <- glm(gender ~ c_eye_left_size + c_eye_left_width, family = binomial, data = train)
summary(m)
Call:
glm(formula = gender ~ c_eye_left_size + c_eye_left_width, family = binomial,
data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.4115 -0.9319 -0.5450 1.0023 2.7047
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 6.07212 0.53758 11.295 < 2e-16 ***
c_eye_left_size -0.58768 0.04435 -13.250 < 2e-16 ***
c_eye_left_width -0.18924 0.04012 -4.717 2.39e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 2483.8 on 1799 degrees of freedom
Residual deviance: 2120.2 on 1797 degrees of freedom
AIC: 2126.2
Number of Fisher Scoring iterations: 3
glm안에 들어가는 매개변수를 다시한번 살펴보면 gender는 성별, size와 width는 눈 크기와 길이를 뜻합니다. *을 보면 실제로 유의미한 변수인건 맞는것 같습니다.
모델로 예측하기
result <- ifelse(predict(m, type="response",newdata=test) > 0.5, "male","female")
이제, 50%가 넘어가는 경우 male로 판별하고, 그 이후인 경우 female로 판별하는 간단한 로직을 추가해보았습니다.
모델 평가하기
언제나처럼 간단합니다.
table(result, test$gender)
result female male
female 135 68
male 36 101
눈크기로 성별을 판단하는것은 조금은 무리였을까요? 눈 길이와 크기는 뭐 엄청 어처구니가 없는 숫자가 나온건 아니지만, 예측율은 좀 떨어지긴 하네요. 정확도(Accuracy)의 경우는 전체 테스트 데이터 수인 340개 중, 제대로 맞아떨어진 True들의 갯수인 236, 즉 69.4%입니다.
조금 더 빡센 기준 도입해보기.
그렇다면, 로지스틱 회귀로 튀어나온 확률 중 70%이상이 확실한 데이터만 그 정확도를 따져보면 어떨까요? 이럴 경우를 대비해 ifelse구문대신 함수를 하나 만들어서 처리해봅시다.
r <- (predict(m, type="response",newdata=test))
cl <- function(x) {
if (x > 0.7) return("male")
else if (x > 0.3) return("neutral")
else return("female")
}
table(sapply(r, cl), test$gender)
female male
female 100 17
male 17 50
neutral 111 132
neutral을 제외하고 보는 정확도(Accuracy)의 경우, 81.5%로 좀더 확실해졌습니다. 다만, 성별을 판별할수 없는 경우는 버려야 하니 아까운 부분이 있습니다.
마무리
어떤 범주에 속할 확률을 바로바로 뽑아낸다는 점에서 로직스틱 회귀는 범주형 결과를 내놓는데 있어 굉장히 많은 역할을 한다고 할수 있겠습니다.
Get your post resteemed to 72,000 followers. Go here https://steemit.com/@a-a-a