[Python] 파이썬 웹크롤링봇 만들기 -4- 파싱툴을 활용한 본문 추출하기
안녕하세요,
이번 포스팅에서는 BeautifulSoup 와 lxml을 활용해서 Coindesk 뉴스에서 본문을 추출하는 것을 해보도록 하겠습니다.
이전 포스팅 [Python] 파이썬 웹크롤링봇 만들기 -3- 암호화폐뉴스사이트 크롤링
마지막에는, 새로 업데이트되는 뉴스를 텔레그램으로 보내는 봇을 만들것 입니다.
뉴스 페이지 호출하기
Python의 HTML parsing 라이브러리인 BeautifulSoup와 lxml을 활용해서 Coindesk뉴스의 본문을 추출해 보겠습니다.
BeautifulSoup 또는 lxml 둘 중 하나 로 충분히 내용을 추출 할 수 있습니다. 저희가 스터디를 했을때는 연습삼아 둘 다 사용했었습니다.
BeautifulSoup 내부적으로는 lxml을 사용하고 있으며, 처음 python을 접하시는 분에게는 lxml 보다는 BeautifulSoup를 쓰는 것을 추천드립니다.
지난 시간에 feedparser를 통해서 새글 정보를 불러오는 코드부터 다시 시작해보겠습니다.
import feedparser
feed = feedparser.parse("https://www.coindesk.com/feed/")
coindesk_urls = []
for entry in feed['entries']:
coindesk_urls.append(entry['link'])
위의 코드를 실행한 후 coindesk_urls 목록에서 첫번째를 꺼내서 본문 내용을 추출해 보겠습니다.
첫번째 URL은 아래와 같습니다.
coindesk_urls[0]
'https://www.coindesk.com/bitcoin-price-looks-north-as-stock-market-falls-again/'
requests를 통해서 해당 URL을 호출 합니다.
import requests
resp = requests.get(coindesk_urls[0])
BeautifulSoup로 본문 추출하기
먼저 BeautifulSoup 라이브러리를 import합니다. bs4 는 BeautifulSoup4 버전의 뜻이고 그 안에 BeautifulSoup라는 클래스?가 있어서 해당 부분만 호출합니다.
from bs4 import BeautifulSoup as bs
soup = bs(resp.text, "html.parser")
resp.text은 reqeusts로 가져온 응답인 resp에서 text만 추출해낸 것입니다.
coindesk_urls[0] 링크를 웹브라우저로 열었을때 보이는 html들의 원문인 셈입니다.
BeautifulSoup 에 resp.text 위와 같이 넣어줍니다. "html.parser" 인자를 넣어주지 않아도 상관없지만 Warning메시지를 보고 싶지 않다면 기술해주는 것이 좋습니다.
잠시, 웹브라우저를 열고 해당 URL 페이지를 열어서 내부 구조를 살펴보겠습니다.
아래 그림은 크롬 브라우저의 개발자도구를 같이 열어 놓은 브라우저 화면입니다. 크롬의 개발자도구는 '메뉴-도구더보기-개발자도구' 로 열수 있으며, 브라우저마다 개발자도구가 조금씩 다르므로 자신이 쓰고 있는 브라우저에서 찾아보시면 되겠습니다.
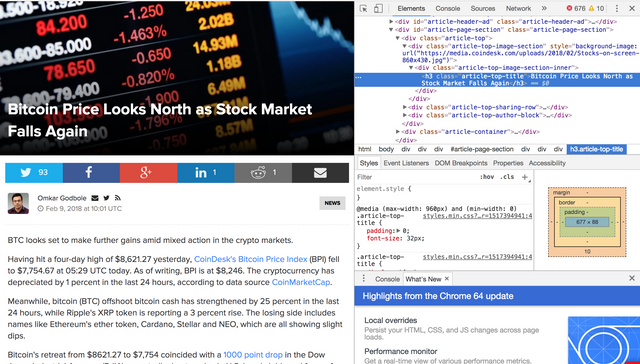
우측 돋보기 아이콘이 웹페이지에 표시된 구성요소의 정보를 찾아주는 도구로서 그림의 붉은색 상자를 클릭하고 웹브라우저에 표시된 객체에 마우스를 올려놓으면 해당 구성요소(Element)를 html 코드를 보여줍니다. 화면상 좌측은 웹브라우저가 html코드를 보고 랜더링한 화면, 우측은 html 코드 자체를 보여주는 화면입니다.
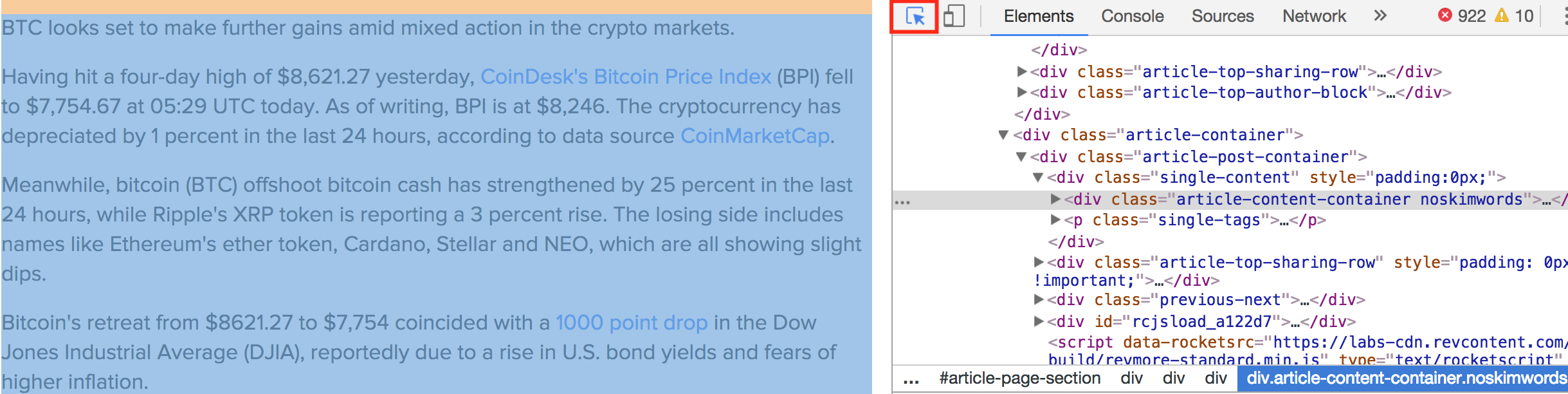
여기서 본문 정보를 감싸고 있는 객체인 <div class="article-content-container noskimwords"> 가 본문을 포함하는 구역입니다.
다시 Jupyter notebook으로 돌아와서, html 코드에 해당하는 부분을 soup에서 호출해보겠습니다.
soup.find("div", {"class":"article-content-container noskimwords"})
호출해보면 아래와 같이 지정한 div tag 안쪽 html전체가 출력됩니다.
<div class="article-content-container noskimwords">
<p>BTC looks set to make further gains amid mixed action in the crypto markets.</p>
(중략)
document.documentElement).appendChild(o)}(document,"script","omapi-script");</script></div>
BeautifulSoup 객체에서 find method는 Html TAG 와 해당 태그 안에 있는 구성요소들을 기입해주면, 알아서 해당 객체를 찾아 호출해줍니다.
개발자 도구 화면에서 <div class="article-content-container noskimwords"> 바로 아래줄에 있는 <P>BTC ... 과 동일 함을 확인 했습니다.
하단부에 보면 Disclouse 이 후 부분은 우리가 원하지 않는 내용입니다. 개발자도구에서 확인해보면 <em> 태그로 둘러 쌓여져 있는것을 볼 수 있습니다.

본문구역인 article-content-... 에서 부터 <em>가 있는 부분까지를 추출해보겠습니다.
soup_body에 본문 구역으로 찾은 객체를 넣어줍니다.
soup_body = soup.find("div", {"class":"article-content-container noskimwords"}) #soup_body본문 구역이라고 합시다
BeautifulSoup에 find의 특징은 조건에 매치된 것 중에 첫번째 객체만을 줍니다.
soup_body.find("em")
<em><strong>Disclosure:</strong>CoinDesk is a subsidiary of Digital Currency Group, which has an ownership stake in Coinbase and Ripple.</em>
find_all 는 해당 조건에 해당되는 결과 모두 return 합니다.
soup_body.find_all("em")
[<em><strong>Disclosure:</strong>CoinDesk is a subsidiary of Digital Currency Group, which has an ownership stake in Coinbase and Ripple.</em>,
<em><a data-wpel-link="external" href="https://www.shutterstock.com/image-photo/stock-market-on-display-142801960" rel="noopener external noreferrer" target="_blank">Stock prices</a> image via Shutterstock</em>]
BeautifulSoup의 Element로 선택된 객체를 기준으로 previous_siblings사용하여 옆으로 이동을 할 수 있습니다. 영문그대로 형제들 말입니다.
단, previous_siblings는 형제자매 tag들을 하나씩 추출해내는 generator함수를 생성해 줍니다.
generator함수라 하면, 해당 함수를 호출할때마다 구성요소 하나씩을 꺼내준다고 생각하시면 되겠습니다.
end_point = soup_body.find("em")
end_points의 지점부터 거꾸로 호출해나갑니다.
body_elem = []
for elem in end_point.parent.previous_siblings:
body_elem.append(elem)
body_elem 리스트를 호출해보면, 본문의 마지막 지점으로 선택한 end_point 에서부터 거슬러 올라가기 때문에 내용을 보면 거꾸로 되어 있습니다.
body_elem은 list 객체이므로 뒤집어서 text만 출력해보겠습니다.
" ".join(body_elem[::-1])
TypeError Traceback (most recent call last)
<ipython-input-211-64bf33791a1b> in <module>()
----> 1 " ".join(body_elem[::-1])
TypeError: sequence item 3: expected str instance, NoneType found
이런, 중간에 None이 나오는군요, 이유인즉 BeautifulSoup가 html를 해석 할때 내부적으로 NavigableString로 저장하는 것들이 있습니다. 이 객체들은 바로 text로 변환이 안되고 None이 됩니다.
try~except로 에러가 나지 않는 것만 body_text에 추가하겠습니다.
body_text = []
for elem in body_elem[::-1]: #list의 [::-1] 의 -1은 step으로 거꾸로 한스탭씩 올라간다는 의미입니다.
try:
body_text.append(elem.text)
except:
pass
body_text는 list 객체이므로 합쳐서 출력해보겠습니다.
print("\n".join(body_text))
join 앞에 \n이 의미하는 것은 개행문자(new line) 입니다.
list의 join method를 통해 문장 사이사이 \n 추가하면서 본문 list를 합쳐서 하나의 string으로 출력합니다.
BTC looks set to make further gains amid mixed action in the crypto markets.
(중략)
On the downside, a break below $7,535 (Feb. 7 low) would signal breach of higher lows pattern and open the door for a drop to $7,000 levels.
lxml로 본문 추출하기
from lxml import html
이번에는 lxml 로 BeautifulSoup에서 처리한 동일한 뉴스 페이지의 내용을 파싱해보도록 하겠습니다.
이전에 사용하였던 resp.text를 그대로 lxml 에 넣어 보겠습니다. lxml에 바로 집어 넣는것이 아니라 fromstring으로 html string을 넣습니다.
lxml_html = html.fromstring(resp.text)
lxml_html
<Element html at 0x7f0488c15a48>
lxml 객체를 호출하면 BeautifulSoup와는 다르게 Element 객체로만 나옵니다. BeautifulSoup는 string만 추출해서 출력해주는 method를 불러내어 text만 출력하게 해주지만, lxml의 경우는 그냥 객체만 출력합니다. lxml에서 실제 내용(text)을 출력하려면 내부 method를 호출해주어야 합니다.
일단 BeautifulSoup에서 했던것처럼 article의 시작부분을 찾겠습니다. lxml에는 find_class라는 method가 있어서 html calss 네임으로 본문의 시작 점을 찾을 수 있습니다.
lxml_html.find_class("article-content-container noskimwords")
[<Element div at 0x7f04883dae08>]
만약 동일한 html class 이름이 있다면 list에 여러개가 되겠지요.
다음은, BeautifulSoup에서처럼 본문의 종료지점인 em 객체를 찾아보겠습니다.
cssselect는 html의 css를 참조? 해서 위치를 찾아가는 method 입니다. 만약 cssselect 라이브러리가 설치되지 않다고 메시지가 나온다면, 바로 아래 명령어를 jupyter notebook 셀에서 바로 실행하면 됩니다. !로 시작하는 것은 shell 명령어를 실행하라는 의미입니다.
!pip install cssselect
Requirement already satisfied (use --upgrade to upgrade): cssselect in
You are using pip version 8.1.1, however version 9.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
저는 이미 설치되어 있기때문에, 위와 같은 메시지가 출력됩니다.
이제 cssselect로 우리가 이미 선택했던 본문 영역 article-content-container noskimwords 아래에서 <em> Tag를 찾아보겠습니다.
lxml_end_point = lxml_html.cssselect("em")
lxml_end_point
[<Element em at 0x7f04883daa48>,
<Element em at 0x7f04883789f8>,
<Element em at 0x7f0488378a48>]
BeautifulSoup에서처럼 <em> tag를 달고 있던 것이 여러개 였던 것과 동일하게 보이네요.
그럼 첫번째 것의 내용을 한번 출력해보겠습니다.
lxml_end_point[0]
<Element em at 0x7f04883daa48>
lxml_end_point[0].text_content()
Disclosure: CoinDesk is a subsidiary of Digital Currency Group, which has an ownership stake in Coinbase and Ripple.'
제대로 찾았군요, BeautifulSoup에서처럼 마지막부터 거꾸로 올라가는 방법을 그대로 써보겠습니다.
lxml_end_point = lxml_end_point[0] #본문의 마지막 포인트를 잡고
p tag 안에 em tag가 들어가 있으므로, em 기준으로 상위인 p tag로 포인트를 옮겨야합니다.
이때 사용하는 method는 getparent로 상위tag 로 포인트를 올라갈 수 있습니다.
end_parent = lxml_end_point.getparent()
end_parent.tag
'p'
태그를 확인해보았으니 이제 형제 tag들을 모아볼까요?
body_lxml = []
for elem in end_parent.itersiblings(preceding=True):
body_lxml.append(elem)
itersiblings는 BeautifulSoup의 siblings 같은 method로 안에 인자를 preceding=True를 넣어주면 해당 포인트에서 글의 역순으로 generator함수가 생성됩니다.
만약, preceding=True 가 없으면 end_parent 이후 나오는 html 들을 함수가 됩니다.
이번에도 거꾸로 정렬해서 하나의 text로 합쳐보겠습니다.
print("\n".join([t.text_content() for t in body_lxml[::-1]]))
BTC looks set to make further gains amid mixed action in the crypto markets.
(중략)
On the downside, a break below $7,535 (Feb. 7 low) would signal breach of higher lows pattern and open the door for a drop to $7,000 levels.
BeautifulSoup와 lxml 두가지로 본문을 추출해 보는 과정을 해보았습니다.
BeautifulSoup보다는 lxml이 처리속도가 빠르고, 에러가 없는편이어서 저는 lxml을 주로 쓰는 편입니다.
다음시간에는 Telegram API를 통해서 본문 메시지를 전송해보는 것을 해보겠습니다.
감사합니다.
이전글 보기
[Python] 파이썬 웹크롤링봇 만들기 -1-
[Python] 파이썬 웹크롤링봇 만들기 -2- First Scraper
[Python] 파이썬 웹크롤링봇 만들기 -3- 암호화폐뉴스사이트 크롤링