A Beginner's Guide to Prometheus for Kubernetes Monitoring
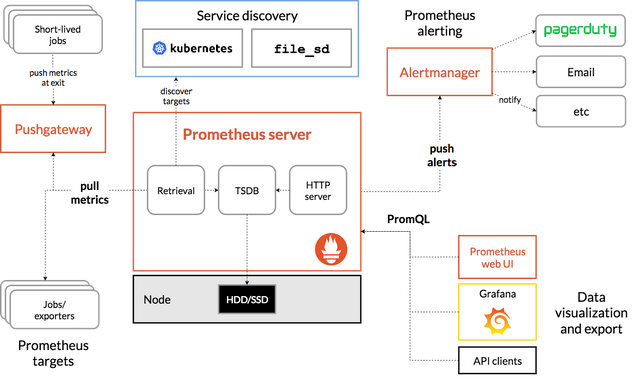
Prometheus is an open-source tool you can use to monitor your containers and microservices. It is used by a wide variety of organizations across business sectors, including Docker and Ericsson. Prometheus was created in 2012 by SoundCloud and joined the Cloud Native Computing Foundation in 2016. In 2018, the project was graduated by CNCF.
Prometheus is customizable and lightweight, enabling you to easily collect metrics and fire alerts. Due to this functionality, it has become a vital component of many DevOps workflows including those that use Kubernetes.
Prometheus Advantages
Advantages of using Prometheus include:
- Kubernetes integration—it is the default monitoring utility used with Kubernetes. It supports dynamically scheduled services and service discovery.
- Multi-dimensional data model—it provides a label-based, time-series database that you can query with PromQL.
- Built-in alert manager—enables you to send notifications according to rules and channels you specify. The built-in nature enables you to avoid the use of external systems or APIs.
- Pull-based metrics—enable you to collect metrics data through an exposed HTTP endpoint. This enables you to collect metrics on-demand.
What to Monitor in Kubernetes
When monitoring Kubernetes with Prometheus, there are several aspects you should focus on. The main three are infrastructure, Kubernetes services, and internal services.
Infrastructure
When monitoring your infrastructure, you should ensure that the underlying server components of all clusters are monitored. Monitoring these components helps you diagnose and avoid workload interruptions.
Specific aspects to monitor in your infrastructure include:
When monitoring your infrastructure, you should ensure that the underlying server components of all clusters are monitored. Monitoring these components helps you diagnose and avoid workload interruptions.
Specific aspects to monitor in your infrastructure include:
- CPU utilization—including both user and system resource consumption. This can be accomplished with iowait, that can reveal bottlenecks that delay I/O processes.
- Disk pressure—although you can use Logical Volume Manager (LVM) to dynamically resize resource volumes, you still need to monitor available volume space. This is particularly important for any resources running etcd or datastores to avoid data corruption and loss.
- Pod resources—for Kubernetes to efficiently schedule pods, it needs to know what resources a pod needs and what resources are available. You should be monitoring to determine which resources the scheduler can use and to verify that predicted pod needs are accurate.
Kubernetes Services
Although many Kubernetes services are self-healing, you still need to monitor service operations. This includes master and worker nodes and etcd clusters. If these services go down and you aren’t aware of it, you’ll experience downtime and potentially significant revenue loss.
Internal Services
In addition to your Kubernetes resources, you need to monitor your individual applications. Kubernetes is typically able to maintain your configurations for you but cannot fix issues within applications. Monitoring enables you to determine if applications are behaving correctly and if performance is as expected.
What Metrics Does Prometheus Provide?
When monitoring, Prometheus offers four types of metric you can choose from:
- Counter—a cumulative metric that can only increase or be reset to zero. This metric is useful for measures such as number of requests, errors, or tasks completed.
- Gauge—a point-in-time metric that can go up or down. This metric is useful for measures such as current memory use or concurrent requests.
- Histogram—a metric that samples observations and categorizes data into customizable buckets. This metric is useful for aggregated measures such as response sizes, Apdex scores, or request durations. Apdex is used to measure the performance of applications, specifically user satisfaction.
- Summary—a metric that samples observations, provides a total count of observations, provides a sum of observed values, and calculates quartiles. This metric is useful for obtaining accurate quartiles.
When using these metrics, there are a few important aspects to keep in mind:
- Prometheus allows you to use labels to define the exact data that metrics pull. These labels must be applied to metrics when called.
- Prometheus has predefined naming conventions that you should follow for each type.
Prometheus For Kubernetes Best Practices
There are several best practices you can employ to ensure that you are using Kubernetes effectively.
Ensure Container Visibility
A container is a largely immutable, black box which can make it difficult to monitor. Fortunately, you can use the Kubernetes API and kube-state-metrics to expose container data, solving part of this issue. For example, data might include unschedulable nodes or the number of replicas running in an environment.
To accomplish this, you need to expose a metric port within the container. Frequently, your container services already provide an HTTP interface that you can use by just adding an additional metrics path.
If you cannot expose a port or take advantage of an existing interface, however, you need to modify your code to support these options. If you cannot modify your code, you can use a sidecar on the container to run a Prometheus exporter.
Start From Timestamps
When pulling metrics it is faster and more reliable to use timestamps than measures of time since. You can still easily get the time since value by subtracting the timestamp value from the current time. By avoiding a direct pull of the time since value you avoid issues created by failures of update logic and speed up the pull process.
Use Labels Sparingly
In Prometheus, you use labels to differentiate between characteristics of metrics. For example, request types or stages. You can use labels to refine your metrics and gain greater insights. However, each labelset you create and apply requires additional resources since data must be tracked and filtered accordingly.
If you only have a few labelsets, the resource cost is negligible. If you have hundreds of labelsets across all of your servers, however, you may see performance impacts. To avoid this, try to keep your metrics labels to 10 or fewer and if possible, avoid labels on metrics. If you must have more labels, you might consider performing your analyses outside of Prometheus.
Conclusion
Prometheus is an open-source tool for monitoring Kubernetes workloads. Prometheus is integrated natively as the default monitoring tool in Kubernetes, including a built-in alert manager. When running Prometheus, the standard metrics are counter, gauge, histogram, and summary. You can add more labels, but try not to overdo this. Maintaining a simple organizational system is crucial for easy monitoring.