Participating in MIT's DeepTraffic competition
I've signed up for MIT's Self-Driving cars class, which by the way is freely available to everyone!
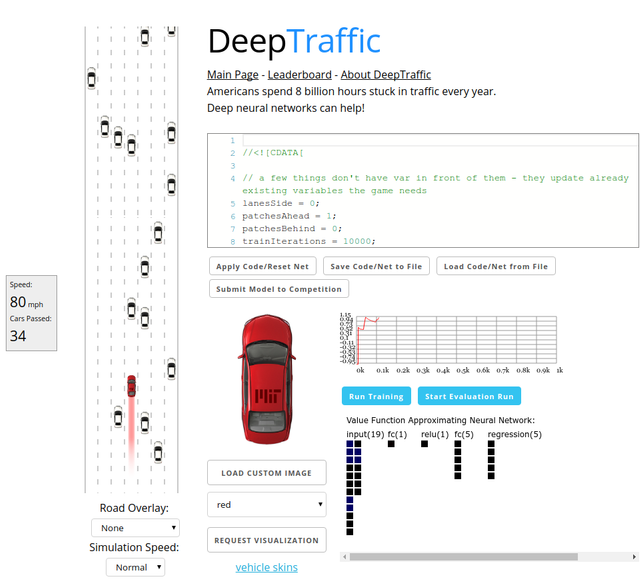
The first task in the class is building a neural network that drives a car as fast as possible through highway traffic. You don't need any prior programming knowledge, and parameter tuning is done in the browser, so anybody can do it :)
You'll need to learn about neural networks and Q-learning.
There are loads of resources with building a neural network out there, so I'll skip that part.
Regarding the Q-learning and reinforcement learning, I recommend David Silver's class(you can also watch the youtube videos).
The deepqlearn code that's used in the starter code can be found here.
There are a couple parameters from there that I would like to go into more detail.
learning_steps_burnin
Agent moves at random for learning_steps_burnin steps.
learning_steps_total
Agent will learn over the learning_steps_total steps, and it should get better and better at accumulating reward. Note that the agent will still take random actions with probability epsilon_min even once it's fully trained.
epsilon_test_time
What epsilon to use at test time
epsilon_min
The agent will still take random actions with probability epsilon_min, even once it's fully trained. To completely disable randomness(i.e. be deterministic once training is over), set this to 0.
experience_size
Size of experience replay memory.
Note that more difficult problems need, of course, bigger memory.
Instead of performing an update and then throwing away the experience tuple, we keep it around and build up a training set of experiences. Then, we don't learn from the new experience that comes in at time t, but instead sample random experiences and perform an update on each sample.
This is as training a Neural Network with SGD on a dataset in a regular ML setting, except here the dataset is a result of agent interaction.
Having a big enough experience_size reduces drift and forgetting.
The agent will still take random actions with probability epsilon_min, even once it's fully trained. To completely disable randomness(i.e. be deterministic once training is over), set this to 0.
start_learn_threshold
Number of examples in experience replay memory before the agent begins learning.
gamma
Controls how much plan-ahead the agent does.
Gamma is the discount factor from the Bellman equation, and determines the importance of future rewards:
factor=0==> short-sighted agent, looking for short-term rewardsfactor=1==> strive for long-term high reward
Hi! I am a robot. I just upvoted you! I found similar content that readers might be interested in:
https://groups.google.com/d/topic/convnetjs/QMbTOdhsnRg