An accessible overview of Meltdown and Spectre, Part 1
This is an adaptation for Steemit of Trail of Bits Blog. if you want to have it in HTML format you can see it here.
In the past few weeks the details of two critical design flaws in modern processors were finally revealed to the public. Much has been written about the impact of Meltdown and Spectre, but there is scant detail about what these attacks are and how they work. We are going to try our best to fix that.
This article is explains how the Meltdown and Spectre attacks work, but in a way that is accessible to people who have never taken a computer architecture course. Some technical details will be greatly simplified or omitted, but you’ll understand the core concepts and why Spectre and Meltdown are so important and technically interesting.
This article is divided into two parts for easier reading. The first part (what you are reading now) starts with a crash course in computer architecture to provide some background and explains what Meltdown actually does. The second part explains both variants of Spectre and discusses why we’re fixing these bugs now, even though they’ve been around for the past 25 years.
Background
First, a lightning-fast overview of some important computer architecture concepts and some basic assumptions about hardware, software, and how they work together. These are necessary to understand the flaws and why they work.
Software is Instructions and Data
All the software that you use (e.g. Chrome, Photoshop, Notepad, Outlook, etc.) is a sequence of small individual instructions executed by your computer’s processor. These instructions operate on data stored in memory (RAM) and also in a small table of special storage locations, called registers. Almost all software assumes that a program’s instructions execute one after another. This assumption is both sound and practical — it is equivalent to assuming that time travel is impossible — and it enables us to write functioning software.
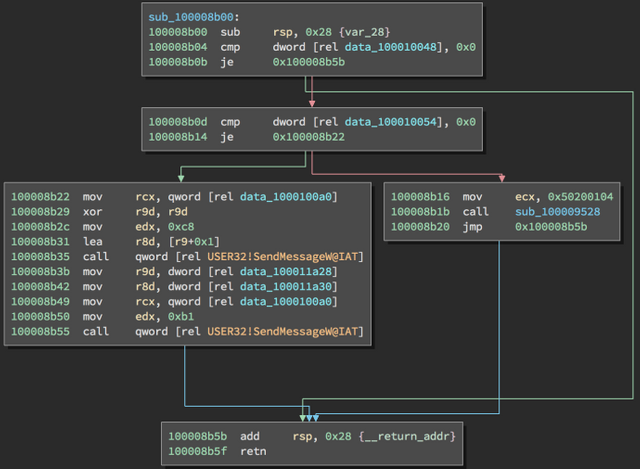
These Intel x86-64 processor instructions in notepad.exe on Windows show what software looks like at the instruction level. The arrows flow from branch instructions to their possible destinations.
Processors are designed to be fast. Very, very fast. A modern Intel processor can execute ~300 billion instructions per second. Speed drives new processor sales. Consumers demand speed. Computer engineers have found some amazingly clever ways to make computers fast. Three of these techniques — caching, speculative execution, and branch prediction — are key to understanding Meltdown and Spectre. As you may have guessed, these optimizations are in conflict with the sequential assumption of how the hardware in your computer executes instructions.
Caching
Processors execute instructions very quickly (one instruction every ~2 ns). These instructions need to be stored somewhere, as does the data they operate on. That place is called main memory (i.e. RAM). Reading or writing to RAM is 50-100x slower (~100 ns/operation) than the speed at which processors execute instructions.
Because reading from and writing to memory is slow (relative to the instruction execution speed), a key goal of modern processors is to avoid this slowness. One way to achieve this is to assume a common behavior across most programs: they access the same data over and over again. Modern processors speed up reads and writes to frequently accessed memory locations by storing copies of the contents of those memory locations in a “cache.” This cache is located on-chip, near the processor cores that execute instructions. This closeness makes accessing cached memory locations considerably faster than going off-chip to the main storage in RAM. Cache access times vary by the type of cache and its location, but they are on the order of ~1ns to ~3ns, versus ~100ns for going to RAM.
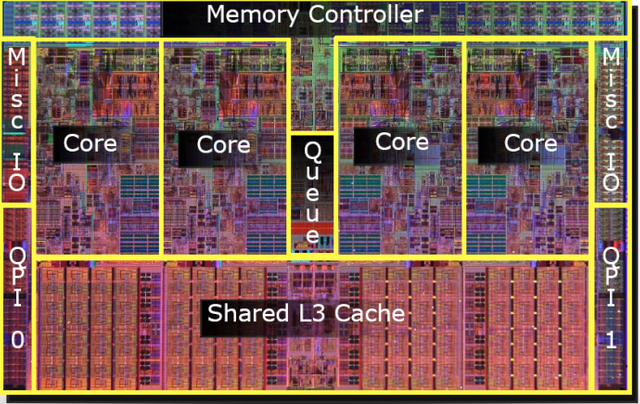
An image of an Intel Nehalem processor die (first generation Core i7, taken from this press release). There are multiple levels of cache, numbered by how far away they are from the execution circuitry. The L1 and L2 cache are in the core itself (likely the bottom right/bottom left of the core images). The L3 cache is on the die but shared among multiple cores. Cache takes up a lot of expensive processor real estate because the performance gains are worth it.
{kind=link}
Cache capacity is tiny compared to main memory capacity. When a cache fills, any new items put in the cache must evict an existing item. Because of the stark difference in access times between memory and cache, it is possible for a program to tell whether or not a memory location it requested was cached by timing how long the access took. We’ll discuss this in depth later, but this cache-based timing side-channel is what Meltdown and Spectre use to observe internal processor state.
Speculative Execution
Executing one instruction at a time is slow. Modern processors don’t wait. They execute a bundle of instructions at once, then re-order the results to pretend that everything executed in sequence. This technique is called out-of-order execution. It makes a lot of sense from a performance standpoint: executing 4 instructions one at a time would take 8ns (4 instructions x 2 ns/instruction). Executing 4 instructions at once (realistic on a modern processor) takes just 2ns — a 75% speedup!
While out-of-order execution and speculative execution have different technical definitions, for the purposes of this blog post we’ll be referring to both as speculative execution. We feel justified in this because out-of-order execution is by nature speculative. Some instructions in a bundle may not need to be executed. For example, an invalid operation like a division by zero may halt execution, thus forcing the processor to roll back operations performed by subsequent instructions in the same bundle.
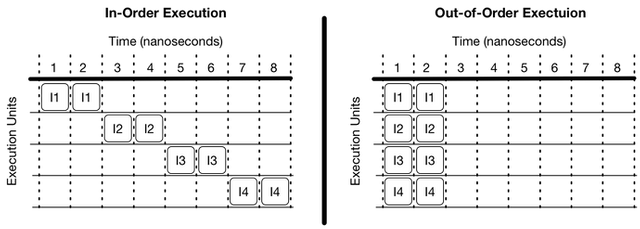
A visualization of performance gained by speculatively executing instructions. Assuming 4 execution units and instructions that do not depend on each other, in-order execution will take 8ns while out-of-order execution will take 2ns. Please note that this diagram is a vast oversimplification and purposely doesn’t show many important things that happen in real processors (like pipelining).
Sometimes, the processor makes incorrect guesses about what instructions will execute. In those cases, speculatively executed instructions must be “un-executed.” As you may have guessed, researchers have discovered that some side-effects of un-executed instructions remain.
There are many caveats that lead to speculative execution guessing wrong, but we’ll focus on the two that are relevant to Meltdown and Spectre: exceptions and branch instructions. Exceptions happen when the processor detects that a rule is being violated. For example, a divide instruction could divide by zero, or a memory read could access memory without permission. We discuss this more in the section on Meltdown. The second caveat, branch instructions, tell the processor what to execute next. Branch instructions are critical to understanding Spectre and are further described in the next section.
Branch Prediction
Branch instructions control execution flow; they specify where the processor should get the next instruction. For this discussion we are only interested in two kinds of branches: conditional branches and indirect branches. A conditional branch is like an fork in the road because the processor must select one of two choices depending on the value of a condition (e.g. A > B; C = 0; etc. ). An indirect branch is more like a portal because the processor can go anywhere. In an indirect branch, the processor reads a value that tells it where to fetch the next instruction.
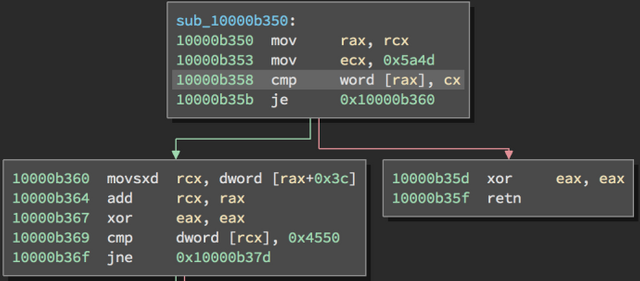
A conditional branch and its two potential destinations. If the two operands of the cmp instruction are equal, this branch will be taken (i.e. the processor will execute instructions at the green arrow). Otherwise the branch will not be taken (i.e. the processor will execute instructions at the red arrow). Code taken from notepad.exe

An indirect branch. This branch will redirect execution to whatever address is at memory location 0x10000c5f0. In this case, it will call the initterm function. Code taken from notepad.exe.
Branches happen very frequently, and get in the way of speculative execution. After all, the processor can’t know which code to execute until after the branch condition calculation completes. The way processors get around this dilemma is called branch prediction. The processor guesses the branch destination. When it guesses incorrectly, the already-executed actions are un-executed and new instructions are fetched from the correct location. This is uncommon. Modern branch predictors are easily 96+% accurate on normal workloads.
When the branch predictor is wrong, the processor speculatively executes instructions with the wrong context. Once the mistake is noticed, these phantom instructions are un-executed. As we’ll explain, the Spectre bug shows that it is possible to control both the branch predictor and to determine some effects of those un-executed instructions.
Meltdown
Now let’s apply the above computer architecture knowledge to explain Meltdown. The Meltdown bug is a design flaw in (almost) every Intel processor released since 1995. Meltdown allows a specially crafted program to read core operating system memory that it should not have permission to access.
Processors typically have two privilege modes: user and kernel. The user part is for normal programs you interact with every day. The kernel part is for the core of your operating system. The kernel is shared among all programs on your machine, making sure they can function together and with your computer hardware, and contains sensitive data (keystrokes, network traffic, encryption keys, etc) that you may not want exposed to all of the programs running on your machine. Because of that, user programs are not permitted to read kernel memory. The table that determines what part of memory is user and what part is kernel is also stored in memory.
Imagine a situation where some kernel memory content is in the cache, but its permissions are not. Checking permissions will be much slower than simply reading the value of the content (because it requires a memory read). In these cases, Intel processors check permissions asynchronously: they start the permission check, read the cached value anyway, and abort execution if permission was denied. Because processors are much faster than memory, dozens of instructions may speculatively execute before the permission result arrives. Normally, this is not a problem. Any instructions that happen after a permissions check fails will be thrown away, as if they were never executed.
What researchers figured out was that it was possible to speculatively execute a set of instructions that would leave an observable sign (via a cache timing side-channel), even after un-execution. Furthermore, it was possible to leave a different sign depending on the content of kernel memory — meaning a user application could indirectly observe kernel memory content, without ever having permission to read that memory.
Technical Details
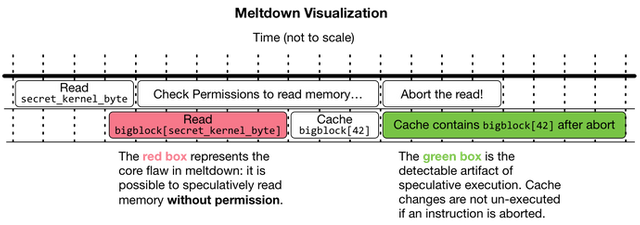
A graphical representation of the core issue in Meltdown, using terminology from the steps described below. It is possible to speculatively read core system memory without permission. The effects of these temporary speculative reads are supposed to be invisible after instruction abort and un-execution. It turns out that cache effects of speculative execution cannot be undone, which creates a cache-based timing side channel that can be used to read core system memory without permission.
At a high level, the attack works as follows:
- A user application requests a large block of memory, which we’ll call
bigblock, and ensures that none of it is cached. The block is logically divided into 256 pieces (bigblock[0], bigblock[1], bigblock[2], ... bigblock[255]). - Some preparation takes place to ensure that a memory permissions check for a kernel address will take a long time.
- The fun begins! The program will read one byte from a kernel memory address — we’ll call this value
secret_kernel_byte. As a refresher, a byte can be any number in the range of 0 to 255. This action starts a race between the permissions check and the processor. - Before the permissions check completes, the hardware continues its speculative execution of the program, which uses
secret_kernel_byteto read a piece ofbigblock(i.e.x = bigblock[secret_kernel_byte]). This use of a piece ofbigblockwill cache that piece, even if the instruction is later undone. - At this point the permissions check returns permission denied. All speculatively executed instructions are un-executed and the processor pretends it never read memory at
bigblock[secret_kernel_byte]. There is just one problem: a piece ofbigblockis now in the cache, and it wasn’t before. - The program will time how long it takes to read every piece of
bigblock. The piece cached due to speculative execution will be read much faster than the rest. - The index of the piece in
bigblockis the value ofsecret_kernel_byte. For example, ifbigblock[42]was read much faster than any other entry, the value ofsecret_kernel_bytemust be 42. - The program has now read one byte from kernel memory via a cache timing side-channel and speculative execution.
- The program can now continue to read more bytes. The Meltdown paper authors claim they can read kernel memory at a rate of 503 Kb/s using this technique.
What is the impact?
Malicious software can use Meltdown to more easily gain a permanent foothold on your desktop and to spy on your passwords and network traffic. This is definitely bad. You should go apply the fixes. However, malicious software could already do those things, albeit with more effort.
If you are a cloud provider (like Amazon, Google, or Microsoft) or a company with major internet infrastructure (like Facebook), then this bug is an absolute disaster. It’s hard to underscore just how awful this bug is. Here’s the problem: the cloud works by dividing a massive datacenter into many virtual machines rentable by the minute. A single physical machine can have hundreds of different virtual tenants, each running their own custom code. Meltdown breaks down the walls between tenants: each of those tenants could potentially see everything the other is doing, like their passwords, encryption keys, source code, etc. Note: how the physical hardware was virtualized matters. Meltdown does not apply in some cases. The details are beyond the scope of this post.
The fix for Meltdown incurs a performance penalty. Some sources say it is a 5-30% performance penalty, some say it is negligible, and others say single digits to noticeable. What we know for sure is that older Intel processors are impacted much more than newer ones. For a desktop machine, this is slightly inconvenient. For a large cloud provider or internet company, a 5% performance penalty across their entire infrastructure is an enormous price. For example, Amazon is estimated to have 2 million servers. A 5 to 30% slowdown could mean buying and installing 100,000 (5%) to 600,000 (30%) additional servers to match prior capability.
What should I do?
Please install the latest updates to your operating system (i.e. MacOS, Windows, Linux). All major software vendors have released fixes that should be applied by your automatic updater.
All major cloud providers have deployed fixes internally, and you as a customer have nothing to worry about.
To be continued…
We hope you have a better understanding of computer architecture concepts and the technical details behind Meltdown. In the second half of this blog post we will explain the technical details of Spectre V1 and Spectre V2 and discuss why these bugs managed to stay hidden for the past 25 years. The technical background will get more complicated, but the bugs are also more interesting.
Finally, we’d like to remind our readers that this blog post was written to be accessible to someone without a computer architecture background, and we sincerely hope we succeeded in explaining some difficult concepts. The Meltdown and Spectre papers, and the Project Zero blog post are better sources for the gory details.
Hi! I am a robot. I just upvoted you! I found similar content that readers might be interested in:
https://blog.trailofbits.com/2018/01/30/an-accessible-overview-of-meltdown-and-spectre-part-1/