Read about the Web3 data track: unicorns, breakers and future stars.
Read about the Web3 data track: unicorns, breakers and future stars.
Although tens of billions of dollars of unicorns have been grown, the data track of Web3 has just begun. Standing in the flood of exploding on-chain applications, every bit and byte defines what kind of Web3 citizen you are, and we need to find a new order and paradigm to resist the entropy increase of the new world together.
Author: FC@SevenX Ventures
Translated by Muqi Yang
This article is for learning and communication purposes only, and does not constitute any investment reference.
If the buzzword of 2021 is meta-universe, then this year's seat will probably be reserved for "Web3", and all of a sudden, various science, analysis, outlook, and questions are coming, making this term a well-deserved traffic password.
Although the definition of Web3 varies from one opinion to another, there is a consensus that Web3 enables users to have ownership and autonomy over their own data, which is the key factor driving the evolution of Web2 to Web3. As our lives and work become more thoroughly digitized, i.e., as human activities are presented as data streams, this cession of data rights is especially critical.
Therefore, we have reasons to believe that the data track of Web3 will become the most important part of the new order and has a broad space for development. From the perspective of entrepreneurs, the decentralized network driven by blockchain technology is an open, permissionless distributed database in essence, and there are many scenarios that need to be served in the direction of data naturally. and grow. In today's article, I will sort out the market structure and typical players of the existing Web3 data track, briefly explain its future development trend, and share some SevenX's investment judgment.
The core points of this paper.
- Web3 breaks data silos, while returning data rights to individual users, who can carry it with them at any time and can combine and interact with applications at will.
- The structure of Web3 data track can be divided into four levels: data source, data acquisition, data query and indexing, data analysis and application. The degree of decentralization, scalability, speed and accuracy of the services provided, and irreplaceability of the scenarios are the main dimensions we use to judge the projects.
- With the gradual enrichment of data market participants and the precipitation and accumulation of data itself, the value of data will increase dramatically, but how to use data to generate greater value while better following the spirit of blockchain fundamentalism to protect privacy is another important issue.
- Building a decentralized reputation system through multi-dimensional data vectors is one of the most important use cases in the Web3 data market. Based on the reputation system, it is possible to unlock various financial scenarios such as credit lending.
When I am talking about Web3 data, what am I talking about
In the process of development of human civilization, a large amount of data is generated, which is either forgotten and lost in the long river of time, or recorded and precipitated into the known history, while the emergence of the Internet allows human beings to record and share data in a more efficient and wider capacity way, thus the value of data is further explored and its importance gradually becomes the consensus of the whole society, and in the In the cover story of the May 2017 issue of The Economist, data was defined as "the world's most valuable resource.
But as more and more data is deposited on the Internet, a fundamental problem begins to emerge: the data generated by individuals creates value, but the data does not belong to them, and the value created is not distributed to them. So people yearned for a new order, and Web3 was born.
So how is Web3 reinventing the value of data? There are three main areas.
Make data open, transparent and untamperable.
In the Web2 world, applications gain access to user data by offering a free service, then monopolize that data to profit and build their business moats. Data is stored on their centralized servers, with no access to the outside world and no way to know what data is stored, how and at what granularity, and user data can be wiped out overnight if these applications are attacked or actively end their services. But with blockchain technology as the underlying We3 framework, on-chain data is made open, transparent and untamperable, which is a prerequisite for their better use.
Break down data silos and improve interoperability.
Whenever you use a new application, you don't need to go through the registration process, which should be the most intuitive manifestation of the negative impact of Web2 data silos on the user side. This repetitive collection is caused by the fact that each application has its own database, which is independent of each other and cannot be connected. At the same time, user behavior data is fragmented in the hands of different applications and can neither be reused across platforms nor integrated. In the world of Web3, on the other hand, broadly speaking, users only need one address to access and use various decentralized applications, and the data corresponding to each on-chain interaction that occurs at this address can be combined without any application permission.
Better value distribution through token economy.
How the value created by the data can be distributed to the individuals who generated it is an important topic that Web3 is geared towards answering, and the evolving token economy may be the core means to achieve this value redistribution, which any user who has ever gained from various airdrops should have a very intuitive feeling. In the context of Web3, the data accumulated and generated by the user's interaction with any application is the carrier of value capture.
In fact, the evalution of the Crypto market itself also drives the development of the Web3 data track to a large extent. On the supply side, the formation of the multi-chain universe, the explosion of various applications, the booming development of NFT, and the large influx of new users have all led to an exponential growth in the type and quantity of data; on the demand side, the multi-dimensionality and complexity of demand has given rise to countless imaginative scenarios and opportunities around data acquisition, collation, access, query, processing, and analysis.
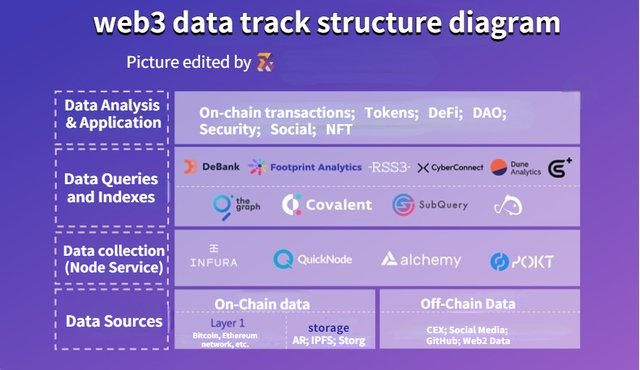
The structure of Web3 data track can be divided into four levels: the bottom level of data sources, the second level of data acquisition, the third level of data query and indexing, and the top level of data analysis and application.
First layer, data sources
Data sources as a whole are divided into on-chain and off-chain data. On-chain data mainly includes: chain-related data (such as hash, timestamp, etc.), transfer transactions, wallet addresses, smart contract events, and some data saved in the cache (such as queued data in the ethereum mempool), which are maintained by a decentralized database, and the reliability is guaranteed by the consensus of the blockchain. In addition, storage is also the main source of on-chain data, currently concentrated in IPFS, Arweave, Storj and other protocols. The off-chain data mainly includes data from centralized exchanges, social media data, GitHub data, and some typical Web2 data, such as PV, UV, daily activity, monthly activity, downloads, search index, etc.
There has been an exponential growth in the type and volume of data in the last two years, but there are currently three problems as far as the level of data sources is concerned.
- Some public chains adopt light node model, which leads to incomplete data on the chain, such as Solana.
- The storage layer generates congestion because of the large amount of data. My good friend REVA once uploaded her NFT work to IPFS, but when she tried to call it, it took 2 hours to download a file of several hundred megabytes successfully (think of the crash of not being able to download an SD movie for two hours). But there are already projects on the market to address this problem, such as SevenX's Portfolio: Meson Network, a decentralized CDN network that aggregates idle servers through mining, scheduling bandwidth resources and serving them to the file and streaming media acceleration markets, including traditional websites, video, live streaming and blockchain storage solutions. Currently, AR, IPFS, etc. are already supported.
- The data under the chain lacks a way to ensure its authenticity, and the data dimension needs to be expanded.
Second layer, data acquisition
The most important player in this layer is the node service provider. If you choose to get the data on the chain by building nodes by yourself, you need higher time, money and technical costs, and you may also face problems such as memory leakage and insufficient disk space, while node service providers greatly optimize this process. As the infrastructure of the whole data track, node service providers are the first players to participate, and unicorns with a valuation of tens of billions of dollars have been born.
Infura, Quicknode, Alchemy and Pocket are some of the more famous service providers, and developers and entrepreneurs will mainly consider the number of coverage chains, business models and the diversity of additional services when choosing one (are there CDN-like services? Is it possible to access mempool data? Is it possible to provide private nodes?) Infura has experienced node downtime more than once before, and whether it is decentralized is also one of the criteria for people to choose. (In November 2020, Infura was not running the latest version of the Geth client, and some special transactions triggered a bug in this version of the client, and then Infura went down and caused a series of chain reactions: the mainstream trading platform could not charge the ERC-20 Token, MetaMask was not available, etc.)
A brief comparison of the four node service providers is as follows.



On February 8, Alchemy closed a $200 million funding round at a $10.2 billion valuation; Infura parent company ConsenSys also closed a $200 million funding round last year at a $3.2 billion valuation; as of March 2022, Pocket had a market capitalization of $3.28 billion outstanding
The third layer, data query and indexing
Above the node service providers that directly interact with various public chains are the market players that provide data query and indexing services. They make the raw data more accessible and usable by parsing and formatting the data.
The Graph
The Graph is a decentralized on-chain data indexing protocol that went live on the main web in December 2020 and so far supports indexing data from more than 30 different networks, including Ethereum, NEAR, Arbitrum, Optimism, Polygon, Avalanche, Celo, Fantom, Moonbeam, Arweave, etc. Moonbeam, Arweave, and more.
It is similar to traditional cloud-based services APIs, with the difference that traditional APIs are run by centralized companies; while on-chain data indexing consists of decentralized indexing nodes. With the GraphQL API, users can access information directly through subgraphs (subgraphs), which is fast and resource efficient. the Graph has designed the GRT token mechanism to encourage multiple parties to participate in its network, involving Delegator, Indexer, Curator, Developer. Developer). The flow of business is briefly summarized as follows: the user makes a query request, the Indexer runs The Graph node, the Delegator pledges GRT tokens to the Indexer, and the Curator uses GRT to guide which subgraphs have query value.
Covalent
Covalent provides a data query layer that allows its users to quickly call data in the form of APIs, currently supporting Ethereum, BNB Chain, Avalanche, Ronin, Fantom, Moonbeam, Klayth, HECO, SHIDEN and mainstream Layer2 networks.
Covalent supports queries for all blockchain data types, such as transactions, balances, log types, etc., as well as queries for a particular protocol. the most prominent feature of Covalent is that it can query across multiple chains without the need to recreate an index like The graph subgraph, which can be achieved by changing the Chain ID. The project also has its own token, CQT, which holders can use to pledge and vote for events such as new database uploads.
SubQuery
SubQuery provides a data query service for Polkadot and Substrate projects, allowing developers to focus on their core use cases and front ends without wasting time building custom back ends for data processing. subQueary is inspired by The Graph, also using the graphQL language, and its token economics are similar to those of The Graph There are three types of roles in the SubQuery system: consumer, indexer, and delegate. Consumers post tasks, indexers provide data, and delegates delegate free SQT tokens to indexers, incentivizing them to participate more honestly in the work.
Blocknative
Blocknative focuses on the retrieval of real-time transaction data and provides mempool's data browser, such as address tracking, internal transaction tracking, information about unsuccessful transactions, and information about replaced transactions (accelerated or cancelled). Because mempool data and final block data do not coincide, the requirement for real-time is higher. blocknative provides more immediate and accurate field queries.
Koii Network
Koii is a decentralized ecosystem for creators that aims to help them own and earn value from their content in perpetuity. Anyone can use the Koii system to earn token rewards by deploying tasks, running nodes, or producing/registering content, and the system rewards participants based on data processed through proof of real traffic, enabling a cycle of "attention economy". In addition, the Atomic NFT developed by the Koii team enables the preservation and validation of NFT and its Meta-Info (the actual digital content represented by NFT) on the same chain, so that all content on the Koii platform can be generated according to the same standards, and if this scalability succeeds in driving the accumulation of content to a certain level, Koii will also Koii will also become a major content data indexing platform if this scalability succeeds in driving content accumulation to a certain level.
Several of the projects listed below provide both data query and indexing services, as well as products that are part of the data application and analysis layer, and are described here for convenience.
Dune Analytics
Dune Analytics is a comprehensive Web3 data platform that allows querying, analyzing, and visualizing huge amounts of on-chain data. Dune Analytics provides three types of data tables: raw transaction data tables, project-level data tables, and aggregated data tables.
Dune Analytics encourages data sharing. By default, all queries and datasets are public, and users can directly copy others' Dashboard and use it as a reference. Currently, the best group of data analysts in the Web3 space are gathered here. dune Analytics now supports data queries for Ethereum, Polygon, Binance Smart Chain, Optimism, and Gnosis Chain at this stage. In February, it completed a Series B funding round of $69.42 million, valuing the company at $1 billion and officially entering the ranks of unicorns.
Flipside Crypto
Like Dune Analytics, Flipside enables users to query complex data with simple SQL statements, as well as copy and edit SQL queries already generated by others, through visual tools and an automatically generated API excuse. flipside actively partners with leading crypto projects, through structured bounty programs and mentoring that incentivizing on-demand analytics to help projects quickly gain the data insights they need to grow.
Flipside currently supports public chain networks such as Ethereum, Solana, Terra, Algorand, etc. On April 19th, Flipside announced the closing of a $50M funding round.
DeBank
DeBank is a DeFi portfolio tracker that allows users to track and manage their interacted DeFi applications in one place, viewing address balances and changes, asset distribution, licensing status, pending rewards, lending positions, and more. Currently, 1,147 protocols on 27 networks are supported.
Last April, DeBank officially launched its OpenAPI program, opening up 28 APIs including access to all protocols on a particular chain, access to a list of all chains and their contract addresses supported by a protocol, access to real-time portfolios on a protocol, etc. All institutions and individual developers can apply to become official partners and access DeBank's DeFi analytics in real time. Analytics data. Currently, imToken, TokenPocket, Math Wallet, Mask, Hashkey Me, OneKey and Zerion are using DeBank's APIs, and DeBank has successfully extended its market from data applications down to data query and indexing.
CyberConnect
CyberConnect is a decentralized social graph protocol whose solution is to build an extensible standardized social graph module that allows developers to port the social graph module to new applications with simple code, saving time and financial costs, while for end users, their social data becomes a personal portable asset that can be easily ported to new applications, breaking down the barriers between platforms in the Web2 world.
RSS3
RSS3 is a next-generation data indexing and distribution protocol derived from the RSS protocol that allows users to generate RSS3 files based on their addresses and associate their Twitter, Mirror, Instant, and other social platforms into the file. This allows developers to retrieve content posted by users on different platforms through different API interfaces with the user's permission, and to filter and display different information based on application characteristics.
Go+
Based on its own "security engine", Go+ is committed to creating a "secure data layer" in the Web3 world. Users can enter the token contract address and get nearly 30 security monitoring items in three aspects: contract security, transaction security and information security, covering ETH, BSC, Polygon, Avalance, Arbitrum, HECO and other public chain ecologies. At the same time, Go+'s security APIs can also be referenced by other developers and downstream applications to create a more secure crypto ecology for their own projects. These security APIs include: Token detection, NFT detection, real-time risk warning, dApp contract security, interaction security, etc.
The emergence of Go+ actually shows a trend in the Web3 data track, that is, the verticalization of data indexing. sevenX found in its research that with the proliferation of protocols and projects, as well as the complexity of user behavior, more and more vertical data scenarios have emerged in the data market, which are characterized by non-generic data, high frequency of user demand, and users are both data users and data providers. In the future, there will be more and more data indexing, querying and analysis services for these vertical scenarios, and these services will probably become the breakers of the whole market because of their clear positioning.
The fourth layer, data analysis and application
This layer is directly oriented to the C-user (in a broad sense, not only referring to individual users), delivering data products that are ready to use. They help users to complete all the heavy and responsible work, and directly present the data value for users from the perspective of their own data methodology. The participants in this layer can be broadly classified according to the type of data as those targeting on-chain transactions, those targeting token prices, those targeting DEFI protocols, those targeting DAO, those targeting NFT, those targeting security, those targeting social, etc. Of course, there are also more and more project departments focusing on a certain type of data, aiming to become a more comprehensive data analysis platform.
Blockchain Browser
This is probably the earliest data application layer product to emerge, allowing users to search for information on the chain, including chain data, block data, transaction data, smart contract data, address data, etc., directly through a Web page.
Glassnode & Messari & CoinMetrics.io
Blockchain data and information provider, providing investors with on-chain data and transaction intelligence from different perspectives & metrics, outputting market analysis insights and research reports.
CoinGecko & CoinMarketCap
Token analysis tools for observing and tracking token prices, trading volume, market cap, etc.
Token Terminal
Analyze DeFi projects with traditional financial metrics such as P/S ratio, P/E ratio, and protocol revenue. Analysis of the NFT trading market is also currently supported.
DeFiLlama
A data analytics platform for DeFi TVLs, supporting 107 Layer1 & Layer2 networks with nearly 1,000 TVLs for DeFi protocols, which can be categorized and compared using different metrics and time dimensions. Currently, DeFiLlama also supports NFT analysis, focusing on transaction volume and Collections types of different trading markets on different chains.
NFTSCan & NFTGO
A data platform focused on the NFT market, providing services such as data analysis and giant whale wallet monitoring, designed to help users better track and evaluate the value of NFT projects and assets, helping to make informed investment decisions.
Nansen
If there is one word that sums up Nansen, it would be "tagging." Nansen has cumulatively analyzed 50 million+ ethereum wallet addresses and their activity, combining on-chain data with a database of millions of tags to help users better find signals and new investment opportunities. one of the most stellar projects in the Web3 data analytics and application layer, having closed a $75 million funding round last December at a $750 million valuation.
Chainalysis
Dubbed the "FBI on the chain," Chainalysis was founded in 2014 as an enterprise data solutions company that monitors and analyzes data on-chain to help governments, cryptocurrency exchanges, international law enforcement agencies, banks, and other clients comply with compliance requirements, assess risk, and identify illegal activity. Last June, Chainalysis announced a $100 million Series E funding round, valuing the company at $4.2 billion.
Footprint Analytics
Footprint is a comprehensive data analytics platform for discovering and visualizing blockchain data. Compared to other applications, Footprint has a lower barrier to use and is very friendly to novice users. The platform offers rich data analysis templates, supports one-click forking, and helps users easily create and manage personalized dashboards, while Footprint also has tagging of other wallet addresses on the chain and their activity, allowing users to make investment decisions with dimensionally rich metrics.
Zerion & Zapper
The earliest DeFi portfolio trackers and managers, both of which now also add support for NFT assets.
DeepDao
DeepDAO is a comprehensive data platform focused on all types of DAO organizations, allowing users to easily view treasury amounts and changes, treasury token distribution, governance token holdings, organization active members, proposals and votes, etc. DeepDAO also provides dozens of tools for both creating and managing DAOs.
There are many more applications at this level, too many to list here.
In fact, SevenX has been focusing on the data track since early on, and has invested in Debank, Zerion, Footprint, Koii, DeepDao, RSS3, CyberConnect and Go+. In the process of screening projects, we have some insights and judgments, which we will briefly share here.
In general, application layer traffic is no longer the core barrier, users may quickly migrate at any time due to other products' ease of use, update speed and other factors, while products with the ability to provide data and form a closed-loop data channel with users will be more competitive, but before the barrier is formed, traffic products have the possibility to feed back.
How do we do the assessment? There are 5 dimensions as follows.
- Scenario selection
(1) Is there a need and is the maturity of the need sufficient or will it happen in the future?
When looking for a requirement, projects need to determine the maturity or stage of the requirement. In the DeFi world "security" is a necessity, and security is a requirement that almost everyone agrees on. So now people prefer to pay an extra step or spend money appropriately to buy a more secure experience.
(2) Do C-sides or protocols first?
We believe that when the demand of the scenario is not fully stimulated, we should do the C-end product first to find the user pain points, otherwise it is easy to take the hammer and find the nail. For example, GoPlus made the Go Pocket wallet in the early days, which was like a model room, and with the model room other partners had a better understanding of what problems the product was solving, which would help a lot in the B-side customer acquisition when extending the protocol later.
After that, SevenX will focus on GameFi, DeFi, DAO, NFT, social, security and other scenarios.
- Data capability
Data acquisition, structuring, etc. are basic skills, but whether you have data capability based on industry knowledge is the key.
- C-terminal product capability
C-terminal product capability mainly depends on whether it can find the urgent needs of the audience as a cold start method and can have ease of use.
- To B expansion capability
To B expansion is a complex decision-making process, whether it can acquire benchmark users, or whether it can efficiently acquire long-tail users according to the product positioning, which are to be considered.
- team background
(1) vertical track web2 big field background, independent operation of a project
(2) open source community experience
(3) rapid learning ability, and unbiased learning
Web3 data possibilities
With the increase of on-chain analysis, the anonymity property of blockchain is gradually broken, for example, people can track the transaction address and transaction behavior of large users based on nansen's tags, and also identify the activities and organizations involved in a particular address and on-chain behavior by on-chain address, which exposes our data to the sunlight and loses the right to choose privacy. And Nansen recently said it has tagged over 100 million wallets, making the need for privacy more and more important.
The main levels of privacy solutions currently included are privacy coins, privacy computing protocols, privacy transaction networks, privacy applications, etc.
If we want to protect our on-chain transactions or activities from selective discovery, or if we want the process to be invisible but the result to be visible, we can choose privacy computing protocols such as Oasis Network, etc. Common techniques include zero-knowledge proofs, secure multi-party computation, modern cryptography-based federation learning, trusted execution links (TEE), etc.
However, the availability of current protocols is more limited, and most are still in the development stage. The one that has landed more is Secret Network, a public chain that has gone live with applications such as the cross-chain bridge Secret Bridge, the privacy DeFi protocol Sienna Network, the privacy transaction protocol Secret Swap, and the Bitcoin Trustless Privacy Resolution Protocol Shinobi Protocol.
Starting in the second half of 2021, head VCs and developers will start to flock to the privacy track in large numbers, and I believe that as this market gradually develops, people will find a balance between how to use data to generate more value while better following the fundamental spirit of blockchain to protect privacy.
Finally, let's briefly talk about one of our judgments on market trends: building a decentralized reputation system through multi-dimensional data vectors is one of the next most important use cases in the Web3 data market, and based on the reputation system, unlocking of various financial scenarios such as credit lending becomes possible.
Lending has always been an important part of the DeFi ecosystem, and currently, the entire market is dominated by collateralized lending (usually over-collateralized) and flash lending. Credit lending, which does not rely on (or is not entirely dependent on) collateral, has been considered the most important evolutionary direction, as credit creates a more freely communicating market.
However, the biggest obstacle facing the introduction of credit lending in DeFi is that lenders are only dealing with one address and cannot effectively verify the solvency of the borrower at the other end of that address and whether he or she has a history of bad credit. Some solutions have tried to accomplish this by bringing off-chain credit data onto the chain, but the question of how to ensure that the off-chain data itself, and its authenticity during the on-chain process, has not been well answered.
Now, with the gradual improvement of the on-chain identity system and the simultaneous growth of data and data analysis tools available for analysis, what users create, contribute, earn and own on the chain can gradually accumulate into the reputation of that user, thus realizing a valid credit assessment from one address to another. In fact, Lens Protocol, endorsed by AAVE, is actually doing just that, managing data with NFT and laying the groundwork for on-chain unsecured credit.
Write at the end
Although a $10 billion unicorn has grown, Web3's data track has just begun. Standing in the flood of on-chain application explosion, every bit and byte is defining what kind of Web3 citizen you are, and we need to find a new order and paradigm to resist the entropy increase of the new world together.
Reference Links
https://www.theblockresearch.com/a-data-dive-into-pocket-network-123733
https://www.theblockresearch.com/alchemy-company-intelligence-115930
https://ath.mirror.xyz/w2cxg5OP1OEcqvSgsEjSSyKRJhPmam0w-fXGogiG-8
Does the multi-level processing of information provide for its maximum qualitative assessment for the user? Is there any filtering? It seems that this whole kitchen is more geared towards statistics and the use of a bunch of garbage information in order to find the final product of the highest quality, and this is a waste of time.
Hello this is a good article let's follow each
Very good
Congratulations @nutbox.mine
This is the most positive post amongst

top 100hot posts on steemit at this moment.