Creating a curation intelligence - Post 2 - A decent model, and how I got it
Hello everyone! Approximately a year ago, I began to try to learn about artificial intelligence in order to create a machine learning model to predict post values for curation. 9 months ago, I felt like the progress I'd made was enough to make this post. I did not expect making a part 2 to take so long, but it turned out to take a lot of time and a lot of different rabbit holes to get to the point where I feel like the progress I've made is worth posting. At this point, I think I have successfully achieved my goal of making a curation intelligence (though I have not yet tested it in the real world). In this post, I will do two things: 1) discuss what I have, and 2) discuss the long process that was necessary to get to this point.
After so long, a curation intelligence

I remember when I was 14. I was new to Steem and completely unfamiliar with how anything related to programming or ai worked. During our first year on Steem, if I recall correctly, I badgered my father about two bot concepts: a voting bot and a spell-check bot. I remember sending him this article which I found on google about how to make a voting bot in less than 10 lines of code, and thinking that all we had to do was use that code to make a ton of money curating. For this project, I have had to create both of these obsessions my 14 year old self had, and man has it taken a lot of time and work.
You can read about how I managed to learn how to spell check languages I don't speak in the previous post, but one update I have on that concept is that I've discovered dictionaries for many other languages including Korean and Bengali. I am quite happy with the spell checker at this point. It's capable of detecting and checking over 20 languages (though unfortunately Chinese and Japanese are not included at this point). If there is enough interest in a posted tutorial on how to spell check Steem articles, I will definitely post that.
But anyway, after all this time, I finally have a model that I am happy with (though I certainly think it will be better after I learn more). Below will be a bunch of the steps I took, but first let's look at the models' performance. I have decided to approach the problem as a binary classification problem - i.e. predict whether or not the post will be worth at least x amount of dollars or not. Instead of using a deep network at this point, I have used a Random Forrest Classifier. To follow will be 10 examples of models which trained with data from posts over the last 9 months predicting whether the test data (data it didn't train with) will be worth at least a certain amount of dollars or not. The data is data that was available when the post was 60 minutes old, and all of the posts included in the data were worth less than a dollar at 60 minutes. Also keep in mind that the test data is only 25 percent of the total data over the last 9 months (the other 75 percent was used for training). The following screenshots will include the confusion matrix as well as the classification report:
Predicting 100 dollar posts
Here's the model's performance predicting 100 dollars or more:
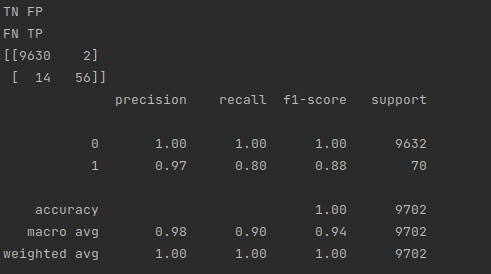
As you can see, there were 56 posts predicted to be worth more than 100 dollars that actually were worth more than 100 dollars (true positives), 2 posts predicted to be worth 100 dollars or more that weren't worth 100 dollars or more (false positives), and 14 missed 100 dollar posts (false negatives). It also correctly identified 9630 posts that were not worth 100 dollars or more (true negatives).
Predicting 90 dollar posts
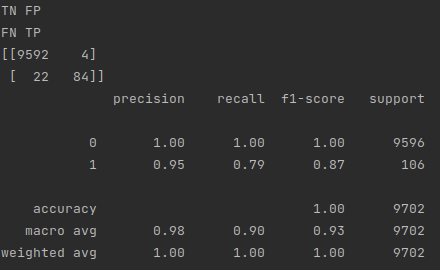
As you can see, there were 84 posts predicted to be worth 90 dollars or more that actually were worth 90 dollars or more (true positives), 4 posts predicted to be worth 90 dollars or more that weren't worth 90 dollars or more (false positives), and 22 missed 90 dollar posts (false negatives). It also correctly identified 9592 posts that were not worth 90 dollars or more (true negatives).
Predicting 80 dollar posts
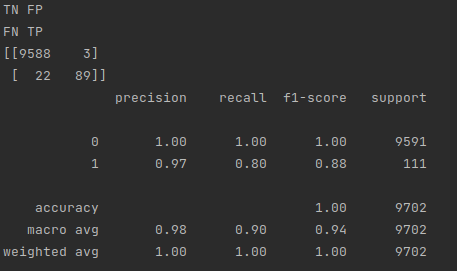
As you can see, there were 89 posts predicted to be worth 80 dollars or more that actually were worth 80 dollars or more (true positives), 3 posts predicted to be worth 80 dollars or more that weren't worth 80 dollars or more (false positives), and 22 missed 80 dollar posts (false negatives). It also correctly identified 9588 posts that were not worth 80 dollars or more (true negatives).
Predicting 70 dollar posts
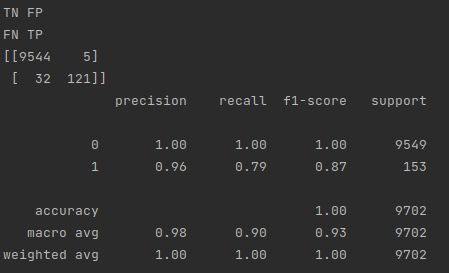
As you can see, there were 121 true positives, 5 false positives, 32 false negatives, and 9544 true negatives
Predicting 60 dollar posts
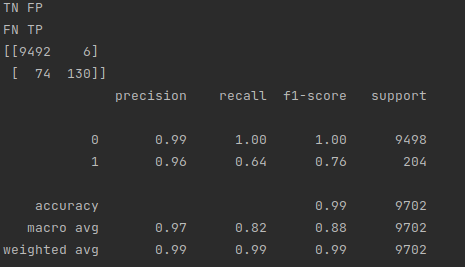
As you can see, there were 130 true positives, 6 false positives, 74 false negatives, and 9492 true negatives
Predicting 50 dollar posts
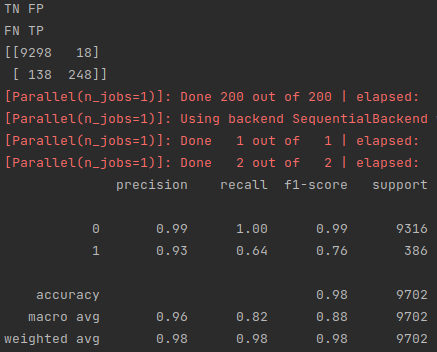
As you can see, there were 248 true positives, 18 false positives, 138 false negatives, and 9298 true negatives
Predicting 40 dollar posts
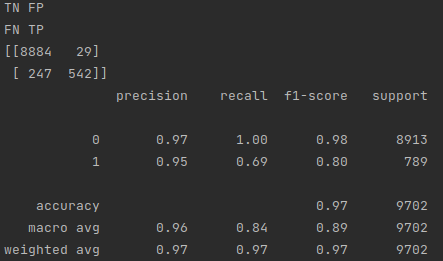
As you can see, there were 542 true positives, 29 false positives, 247 false negatives, and 8884 true negatives
Predicting 30 dollar posts
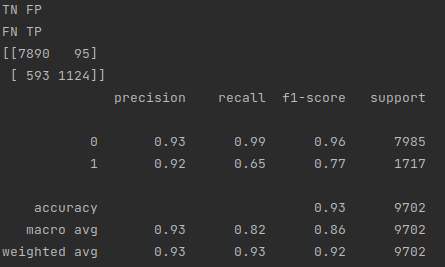
As you can see, there were 1124 true positives, 95 false positives, 593 false negatives, and 7890 true negatives
Predicting 20 dollar posts
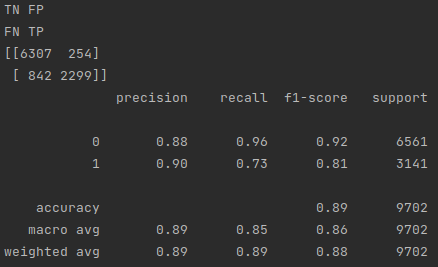
As you can see, there were 2299 true positives, 254 false positives, 842 false negatives, and 6307 true negatives
Predicting 10 dollar posts
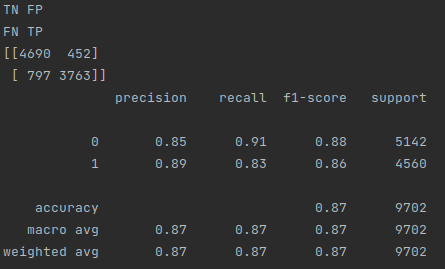
As you can see, there were 3763 true positives, 452 false positives, 797 false negatives, and 4690 true negatives
The thing that excites me most about all of these models is that the false positives are low. It is much more preferable for this to be the case when curating because if the model predicts something to be positive, more likely than not it is. Even if it misses some positives, what it gets will likely be positive. I would rather be conservative and not waste a vote than lose my voting power to a post that the model predicts to be high value and turns out to be low value and therefore yields low rewards.
My hope is to figure out in the coming month how to utilize these different models (or create one model) to maximize curation rewards. Now I will explain all of the steps I took to get to this point.
Steps to get here
My last update mainly pertained to downloading data, and there were certainly more steps to take in this regard, but the first thing I did was finish the course on machine learning, and try to build a Deep Learning model to work with the data I downloaded. It goes without saying, that this model sucked. I had probably a quarter of the data features I now have, and I did not have many samples at all I don't think.
Building a hybrid model
My initial thinking was that there was a problem with the time series data (for instance, value at 5 min, 10 min, 15 min, ..., 60 min). My thinking was that this data was like stock data, and I realized that the model often used to work with this kind of data is recurrent neural networks (more specifically a model called LSTM "long short term memory"). I became convinced that the optimal model would be a hybrid model which incorporates a standard ANN for the non-time data and a RNN for the time-series data. The only problem was the course I did did not cover RNNs. So I purchased another course on udemy. This course covered several different kinds of neural networks: artificial neural networks (for standard data), convolutional neural networks (for image data), and recurrent neural networks (for time based data like stock prices, videos, and audio). It also covered unsupervised learning models. Specifically, self-organizing maps, Boltzmann machines/restricted Boltzmann machines, and auto encoders. Overall this course was very beneficial in terms of my general deep learning knowledge.
So when I completed that course, I tried to build a hybrid ann-lstm model. Unfortunately, the lstm portion of the model always seemed to be dead weight no matter what I tried. I became convinced that the reason for this was the parameters I was using were incorrect. So I began to brain storm on how to find the right parameters. Eventually, I had an idea to try to use a genetic algorithm to find the best network design and parameters.
Building a genetic algorithm
So I tried to review genetic algorithms, and began to build a genetic algorithm which I thought would work. I spent over a month on this project, and made it so the program would run 24/7, and update a google spreadsheet with the data so I could view it where-ever I was. After a month, I realized that the lstm portion was just dead weight (I conceptually thought about it, and realized that every article is a unique "object" in terms of time data whereas the stock market has months and months of data for the same stock "object"). So I decided that the reason it wasn't working was because it would never work.
Collecting more data features
After a bit of a break, I decided a good solution might be to find more data features. One thing I thought of was collecting more data on the post author's recent author rewards as well as specific curators' recent curation rewards. So I learned how to do that using the actual steem python module and the public api. One thing I learned fast was that this took way too long due to rate limiting. I then thought the solution was to set up my own node, but realized none of our computers had the specs to do that. So I dealt with the slow download speed for a while, and idiotically cleared the post's I'd downloaded instead of just inserting the new data into the already downloaded articles in the database.
Because the speed was so much slower, I tried to limit the amount of articles I needed to process. I decided only to process posts that were worth at least a cent at an hour. This dramatically reduced the number of articles to download from 400,000 to like 10,000. The problem was when I downloaded them all, there wasn't enough data for the AI to train on. I tried turning it into a classification problem, then treated it like a regression problem, and then tried using genetic algorithms in both cases to try to find an optimal model. It didn't work because there simply wasn't enough data to work with.
Discovering Steemworld's Steem Data Service
Eventually, I realized that @steemchiller's website had a whole portion with data which I could use, and I switched from using the steem python module to downloading the data from steemchiller's. Discovering this also helped me find a bunch of features which I could use that I hadn't thought of.
Learning how to use async programming
I eventually realized while watching a tech tutorial that I could probably speed things up by using asynchronous programming to do things while the program was waiting for a response from the network. So I converted to using an asynchronous functions for my steem world calls. This increased the efficiency, but it was still too slow.
Learning how to use multi-threading and multi-processing
Eventually I discovered multi-threading and multi-processing, and learned how to use that to dramatically increase the download speed. But it was once again too slow. It probably took me a week to download a historic month worth of data, and also my computer got really slow while I was running the program so doing anything else required me to stop the program.
Buying a new computer, and discovering an ethernet port in my dorm room
Eventually, a classmate of mine offered to help me build a computer. So I ordered all the parts, and watched him put the computer together. This new computer has great specs. I got it for pretty cheap, and purchased a used graphics card off of my classmate. The computer has an 8 core processor with 16 threads, 32 GB of ram (with space for more), and 225 GB of SSD storage.
This computer, combined with the ethernet port I found in my room, combined with the use of async, multiprocessing, and multithreading was able to download 9 months worth of data in approximately a week. Not to mention I can do other things on it while it is downloading the articles, and it is much faster when training models for AI.
The day after I started downloading all of the posts, the schools printers all stopped working and I joked with my friends that I was the reason (I wasn't to be clear). My school seems to have a pretty good network connection though. I wish I'd realized there was an ethernet port a year ago :)
Deciding to use a random forest classifier
Playing around with the downloaded data I have, I realized that the random forest classifier is just outperforming any deep learning model I make at this point. So for now, I think it's the best option (especially looking at all of the data in the screen shots above). Considering that I am not doing anything in regards to the model's parameters except choosing the number of estimators makes me think that there's a lot of room for growth if I research more about improving random forest models. Eventually, perhaps I will find that my teacher is right that a deep learning model is better, but for now the random forest model seems to be the way to go.
Conclusion
Thanks for reading this if you made it this far! I'm very excited to share this article! Feel free to leave any feedback! I hope to soon continue development on mod-bot and hopefully also work on some kind of steem-stats visualizer like I discussed in the first post. Have a great night/day!
This was a good insight...
I guess the more appropriate comparison would be the author account, but then you run into the problem that authors post infrequently in comparison to the millions of stock trades that happen daily.
This is great work! I'd love to hear some more about the network inputs.
Thanks! Most of the valuable inputs came from sds.steemworld.org, and the source code for @trufflepig
So nice dear