Forecasting Adventures 4 - Processing Blockchain.info's Data

Okay so while my software is in review mode (please review it if you are a coder), I thought why not analyze Blockchain.info's statistical data's impact on the BTC/USD price. I already did an analysis of those datapoints in the past, but I think I was sloppy in the past, I didn't processed the data correctly, so those results might be bogus.
So I have got some spare time today and tomorrow, so why not analyze that data in my spare time, I like to do that in my spare time, I usually spend my time with useful things and not watching stupid TV shows and playing video games like other people do, plus my wife is with her parents so why not do this in my spare time, "searching for knowledge". You know knowledge is power, and knowing the BTC/USD market means that money can be made of that.
So while my software is in review mode, I thought I compare the Blockchain.info statistics, and analyze that. Basically using those as an exogenous variable for the BTC/USD time-series ARIMA model.
Basically constructing an ARIMAX(p,d,q){Blockchain.info dataset} kind of model where the exogenous variables would be those datapoints in different combinations or by themselves. Of course I would test for seasonality as well, so it might as well be a seasonable model.
Well that would be nice, but when I downloaded Blockchain.info's data, I found that it's very very messy. Basically their dates are ridiculously disorganized, I mean take a look at this:
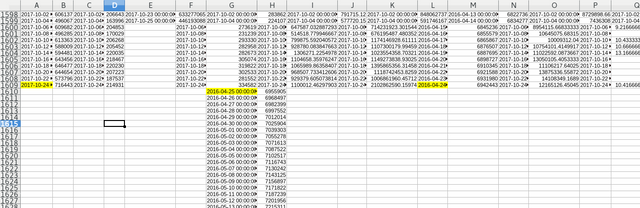
I have merged the datasets together (automatically) and this is the mess that I get. How the hell am I supposed to work with that data if half of the data is missing from certain points or the dates are numbered incorrectly. And before you'd think, it's not my merging method that is at fault here, the dates are indeed messed up, just take a look at the BTC/USD price data vs the trade volume:

As you can see either the dates are sliding 1 day ahead or backwards or some times 2-3 days are missing, in some cases even a week is missing. Some data is daily available other only bi or tri-daily, some data is even available hourly and other data is missing entire years from it.
It's a complete mess. Blockchain.info surely didn't put the effort into processing and syncing that data together, because in it's current form, it's unusable for any statistical analysis. I mean you can't compare the data if the dates are sliding or missing, it would be like comparing apples to oranges.
So even though I was excited to do some analysis on the data, unfortunately it looks like I have to process and correct it first. This is a very painful process, since it we would not know any better we'd have to compare every single datapoint in every single file to the BTC/USD price set, one by one.
Of course that is unfeasible for a dataset that it tens of thousands of points big, but the statistical software doesn't correct it, and even if it does, it usually puts a dummy value there like 0, which makes it inaccurate.
But I am a smart person, so I made my own correction software for it. It was very painful and boring but it had to be done since otherwise we can't analyze it.
Data Processing & Correcting Tool for Blockchain.info's Data:
I am really getting good in coding python with some inspiration from Stackoverflow's answers where I get some of the syntax from, but the code I built myself.
What I built is a tool that takes the original price data the "old data" as I referred to it in other articles, and check every single other file to be in the same data format as that file is. If dates are missing we take the previous available date, if that is missing, then we take the one before it. Basically it corrects the data recursively, where we can set the level of recursion.
Yeah I am a fucking genius, I built an entire software for recursively correcting datasets with missing or sliding values, so you should thank me since I will make it public so that you can do that too!
How to use it:
Put all the data files except the file that you want to compare it to in a folder where the software is. So if we name the software recursive_correct.py and it's located in Documents, then put the btc_usd.csv next to it, and create a new folder named data in Documents and place the rest of the .csv files in Documents/data.
Then since it's a python script (I tested it on pre 3.x python) so you should run it as python recursive_correct.py although it should work on python 3.x as well, but the dependencies might be messed up, so I just used in old python.
Then I set the recursive level to 6, which means it will iterate 6 values back to look for a match, and it will take a lot of time to process it, for me it took 50 minutes to go through all the data, because we have basically 4 nested loops so the processing requirement is big.
So it just goes through all files, all recursive levels, across the entire dataset and checks for each date line to be matching. If they match, it just writes that, if it doesn't, then it goes 1 recursion deeper and checks for the previous element for the previous day, and so on until it meets the recursive limit.
Then after all files are processed it writes them back into the data folder with a proc_ prefix so you can compare them manually.
Then it merges all the proc_ files together in 1 .csv file next to eachother in the next columns, so you can check if everything is in order.
If the date is missing then it will write there a notfound signal or if the recursion is too deep and we went beyond the dataset then it will write oob for out of bounds.
There are some datasets where the data starts 1 or 2 years later, there is nothing we can do there, we just can't use that data. Otherwise if the data is not found, then we just need to increase the recursion limit, but only on that file alone, so that should be done manually, otherwise it will take a loooot of time.

So this is how the trade-volume.csv got corrected, as you can see the first column shows the date of the btc_usd.csv file and the second column is the date of the trade-volume.csv file. What we did is just slided the previous values into the current value.
There is no cheating here, since we can do whatever we want with the past data. The only rule is that we can't use future data. So by replacing the missing Oct 20 data with Oct 19 data, it's perfectly valid correction.
After Processing
So I have processed all the datafiles that I can grab my hands on, that had complete data. I left out the duplicates like that n-transactions which was filtered by popular addresses and so on, it makes no difference statistically since our models can detect that anyway.
It took a lot of time but the latest version of the software is a little bit faster after I have removed unnecessary loops. There are no errors and no out of bound problems in the output dataset (simply because I have ignored too damaged datafiles, only slided datafiles got processed).
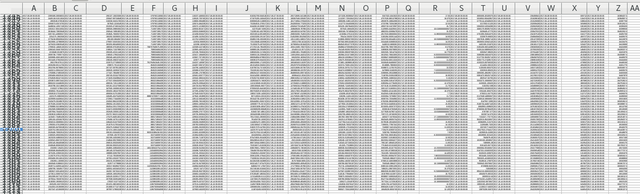
It aligns perfectly and I find no problems with it:
Download Tool from Here
Sha256-Digest:
35da70475a02324d01b643c47dce5dca67bc138c6f4c5da442cf1d8d4e7c2590
Download Processed Data from Here
Sha256-Digest:
33f19046c4f4e832c6704eb62c76423213d8bc2138da4f77399a1e9e924cfc04
As always if you find problems, bugs or errors please signal it, or help me correct it! I made this tool public so it’s the least you can do to help me make it better!
Sources:

Sorry to break this to you, but you double posted.
The transaction went through, but they didn't tell your browser.
I used steemd.com to check what's actually done.
Ah fuck, I got a "transaction broadcast error" so I tried posting it multiple times....
What the hell is happening with Steemit, and how to delete the other posts?
In the first 3 minutes, you can delete your post.
Else, you do what you did. Write -deleted- over your post and save it.
BTW, you can still go look at the posts you overwrote. They are still there. Steemd can get you the links.