Fuzz-Testing the Snappy Compression Algorithm
- Using American Fuzzy Lop on the Snappy compression library found no new bugs, and reported only high memory usage related to preallocation of an output buffer.
- Users of Snappy should be aware of this preallocation and check the uncompressed size before calling
snappy::Uncompress - Non-C++ implementation of Snappy have had bugs reported by AFL-derived tools.
Snappy
Snappy is a compression library (https://github.com/google/snappy) that is optimized for speed rather than achieving the maximum compression. It’s used in a several NoSQL databases, and in the Ripple blockchain implementation.
Compression algorithms, like parsing libraries, are usually a good target for fuzzing. By their very nature, inputs to decompression are very compact, so small modifications are likely to explore new code paths. We can also demonstrate using a fuzzer to check semantic correctness as well as security properties.
Compiling Snappy and Creating a Test Harness
Snappy uses CMake so it was simple to replace its default compiler with afl-g++ and afl-gcc to generate an instrumented library.
We created two test harnesses. The first takes an uncompressed string and verifies that a compression/uncompression cycle results in the original string. This sort of “round-trip” is common in property-based testing, and we can use it with a fuzzer as well to do a semantic check, rather than merely checking for memory violations or crashes.
#include <snappy.h>
#include <iostream>
#include <string>
#include <cstring>
#include <stdlib.h>
const size_t maxInputSize = 10 * 1024 * 1024;
char inputBuf[maxInputSize];
int main( int argc, char *argv[] ) {
std::cin.read( inputBuf, maxInputSize );
size_t inputLength = std::cin.gcount();
std::string compressed;
snappy::Compress( inputBuf, inputLength, &compressed );
std::string uncompressed;
snappy::Uncompress( compressed.data(), compressed.size(),
&uncompressed );
if ( uncompressed.size() != inputLength ) {
std::cout << "Size mismatch.";
abort();
}
if ( memcmp( uncompressed.data(), inputBuf, inputLength ) != 0 ) {
std::cout << "Content mismatch.";
abort();
}
return 0;
}
Gist: https://gist.github.com/fuzz-ai/a4a2c06116a90a3d793df87701dc5f8c
To test the robustness of uncompression, we feed the original input buffer into Decompress instead:
std::string uncompressed;
snappy::Uncompress( inputBuf, inputLength,
&uncompressed );
Test case generation and results
Snappy includes some files for testing and benchmarking; these are not really suitable for fuzzing, because they are quite large (as is appropriate for a speed-oriented library!) Even several hundred kilobytes make some of the AFL fuzzing steps quite slow, and it is unusual for a bug to require a large input to manifest.
AFL even suggested that one of the test cases could be removed
[*] Attempting dry run with 'id:000004,orig:baddata3.snappy'...
len = 28384, map size = 136, exec speed = 369 us
[!] WARNING: No new instrumentation output, test case may be useless.
The program afl-cmin (for “corpus minimization”) can be used to filter an initial set of test cases to one where each example has at least one distinct code path.
So, for testing purposes, I cut the provided files down to 1KB each, except for the “bad data” cases which were left as-is.
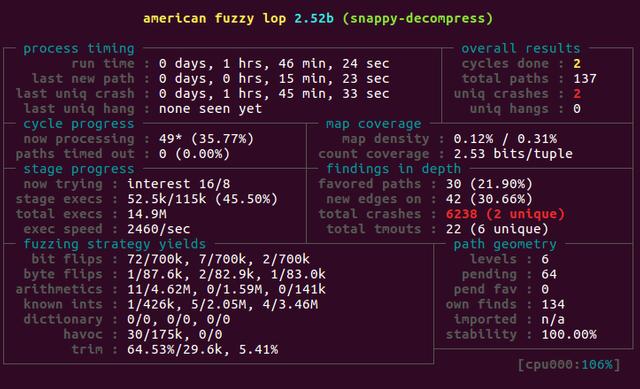
AFL ran several million iterations without finding any significant bugs. As the screen above shows, it is rather easy for the fuzzer to find cases where decompression crashes, but this is due to the 50MB limit on memory allocation.
Analysis
It seems likely that this is not the first attempt to fuzz Snappy, though I cannot find any indication of previously-reported bugs credited to AFL or another tool.
Other implementations of Snappy have been fuzzed successfully; for example, the Rust implementation had an error discovered by afl-rust: https://github.com/BurntSushi/rust-snappy/issues/12
The Snappy C++ interface uses a std::string as output and resizes it at the start of uncompression:
bool Uncompress(const char* compressed, size_t n, string* uncompressed) {
size_t ulength;
if (!GetUncompressedLength(compressed, n, &ulength)) {
return false;
}
// On 32-bit builds: max_size() < kuint32max. Check for that instead
// of crashing (e.g., consider externally specified compressed data).
if (ulength > uncompressed->max_size()) {
return false;
}
STLStringResizeUninitialized(uncompressed, ulength);
return RawUncompress(compressed, n, string_as_array(uncompressed));
}
The maximum size on 64-bit systems is quite large, so this is a possible vector for memory exhaustion attacks if clients use this method without checking GetUncompressedLengthfirst. We need not use a fuzzer to investigate this possibility, since the first four bytes of the Snappy format give us a way to set the uncompressed length in a straightforward fashion.
After the fuzzer has generated its corpus of examples, we could use a standard coverage tool to compare how well the results compare with the benchmarking inputs included with Snappy. Such automatic generation of test cases usually does much better than hand-crafted examples; we'll show an example of this in another article.
Fuzz.ai
Fuzz.ai is an early-stage startup dedicated to making software correctness tools easier to use. Fuzzers, model checkers, and property-based testing can make software more robust, expose security vulnerabilities, and speed development.
Congratulations @fuzz-ai! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board of Honor
If you no longer want to receive notifications, reply to this comment with the word
STOPCongratulations @fuzz-ai! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Congratulations @fuzz-ai! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Congratulations @fuzz-ai! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Thats impressive snappy ;-)