Steem Pressure #6 - MIRA: YMMV, RTFM, TLDR: LGTM
MIRA has recently become the most famous ETLA on STEEM.
But what exactly is MIRA and what does it do? Let’s take a look at MIRA performance-wise.
MIRA (Multi Index RocksDB Adapter)
The purpose of MIRA is to allow Steem blockchain nodes to store almost all necessary data on a disk in a modern database, as opposed to a shared memory file
But why is that better?
Non-MIRA steemd works fine… as long as its state file, which is located in shared_memory.bin, fits on a RAM disk or your system has enough RAM for buffers and cache to handle it. The state file grows and once you run out of RAM, performance degrades SIGNIFICANTLY because of its extreme I/O intensive nature.
Pre-MIRA main issues:
- Full API: To provide full API support, you need servers with a ridiculously high amount of RAM (512GB+)
- Consensus node: A lot of memory is needed even for a basic node that doesn’t need very low latency (like a private steem node for broadcasting and managing a wallet)
- Exchanges: They usually run steemd on a potato-grade VPS servers where NAS or IOPS limiting is a common practice.
Full API
A Long, long time ago, you had no choice but to run a big monolithic node if you wanted to satisfy all the API needs.
Nowadays you can build a customized infrastructure that suits you best.
Hivemind can replace slow and resource hungry tags and follows plugins.
The account history plugin, which was blessed with RocksDB optimization earlier, may significantly reduce the burden on a “fat node” (i.e. LOW_MEMORY_NODE=OFF).
Unfortunately, a “fat node”, even after removing the burden of tags, follows, and account_history, is still memory hungry.
30M blocks need 175GB for shared_memory.bin file.
That means that nowadays a server with 256GB of RAM is barely enough.
(Don’t forget that somewhere there there’s a 64GB RAM machine for a consensus node running a RocksDB powered account history plugin and a 16GB RAM machine with jussi and hivemind.)
Consensus node
A consensus node doesn’t need that much RAM, but it still needs a significant amount. It should be a lightweight node but it isn’t exactly lightweight if you need a 32GB RAM machine with a decent storage backend (in my benchmark, I used a 3x SSD drive in RAID0 configuration, not really a typical setup for your workstation at home).
A consensus node can be found in many use cases: a seed node, a broadcasting node, a witness node, or a private node for cli_wallet interaction.
If you have it running, this means that you have your own copy of the Steem blockchain which is essential for decentralization.
Exchanges
Unfortunately, we can’t expect exchanges to run a fancy server dedicated to Steem in order to process a simple transfer operation. Sure, we can tell them that Steem is awesome, and that’s very true, but they care about money, and even though many other coins can also be a pain in the back(end), some of them tend to have daily volumes 500x higher than Steem.
In the past, it took some of the exchanges weeks to replay.
“Hey, exchange, we don’t want to insult you but…”
Is not a good way to start a conversation, so it’s essential that we make Steem run on a potato. Faster.
So what is MIRA and how can it help?
There is already a lot of material on that topic, most importantly:
@vandeberg’s What is MIRA?
@steemitblog’s MIRA: Soft Roll-Out Begins!
YMMV (Your Mileage May Vary)
Depending on your needs, MIRA can make your time of replay 2-5x longer or infinitely faster (“within a few days” is a much better ETA than “never”).
- If you are a witness, have a good 64GB RAM machine with a local SSD storage backend, you won’t be happy, because MIRA doesn’t help much in your case - on the contrary, it will slow you down.
- If you run a seed node or a consensus node on hardware similar to my benchmark setup, that is 32GB RAM with a low latency storage backend you won’t be happy either, because replay times are expected to be much longer, but once it’s running you should be happy, especially when you were about to run out of your fancy storage space. Yes, RocksDB data take less space than the
shared_memory.binfile. - If you run the most common node, a consensus node on an average machine or a VPS, where the storage backend is usually either limited in terms of IOPS or has higher latency because it’s network attached, you will be happy, because in that environment MIRA behaves much better. That applies to many low ranked backup witnesses, exchanges, and even individuals who want to run their own node locally.
- If you would like to run fat nodes or full nodes, or you have a decent infrastructure with state providers, or much more RAM than a consensus node needs (to reindex in-memory using the hybrid mode), then you will be more than happy to run MIRA. A fat node on a 64GB RAM workstation? Sure.
RTFM (Read The Friendly Manual)
You need to get to know MIRA better to be able to make it work for you in the most efficient way.
MIRA has many options that allow the user to improve performance. For most use cases, the default options will be sufficient. However, one consideration when configuring MIRA is resource limiting.
- MIRA basic configuration guide english corrects and improvements
Hybrid mode
You can actually reindex with the most expensive indices in memory, using current solution and then migrate to RocksDB after the reindex is complete. If you have enough RAM to keep everything in memory and still enough left for what MIRA needs, you will be happy with that speed.
(If not… then you won’t: take a look at Case 1 below)
LGTM (Looks Good To me)
Here are some of the examples of how MIRA behaves in different use case scenarios and hardware setups:
Case 1: Consensus node on 32GB server optimized for non-MIRA
Intel Xeon E3-1245 V2 @3.40GHz, 32GB RAM, 3x SSD (RAID0)
This is our usual one, that were used for benchmarks in previous episodes.
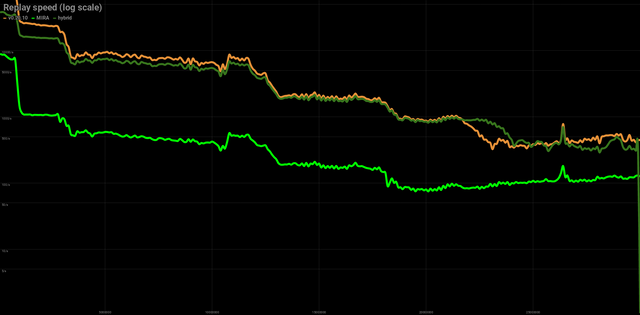
That’s one of the scenarios that gives the worst results. A node that is optimized to run non-MIRA steemd and had done so just fine for the last 30M blocks. It uses tmpfs to reduce latency for the shared_memory.bin file.
With MIRA replay is significantly slower.
MIRA in hybrid mode replays almost as fast as optimized tmpfs, but since machine doesn’t have enough RAM switching from BMIC to RocksDB takes a significant amount of time.
| Replay | v0.20.10 | MIRA | hybrid |
|---|---|---|---|
| 30 M blocks | 8 hours | 48 hours | 8+25 hours |
Case 2: Fat node on 64GB workstation
Intel Core i7-6700K @4.00GHz, 64GB RAM, SSD
“Fat node”
That is built with:
LOW_MEMORY_NODE=OFF and CLEAR_VOTES=OFF
and running plugins aimed to satisfy hivemind needs:
plugin = webserver p2p json_rpc witness account_by_key reputation market_history
plugin = database_api account_by_key_api network_broadcast_api reputation_api market_history_api condenser_api block_api rc_api
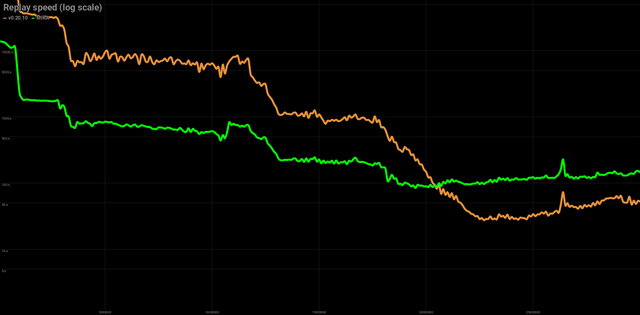
| Replay | v0.20.10 | MIRA |
|---|---|---|
| 30 M blocks | 71 hours | 41 hours |
| State size | 175 GB | 81 GB |
Case 3: Consensus node on a 16GB server
Intel Xeon W3530 @2.80GHz, 16GB RAM, 2x SSD (RAID0)
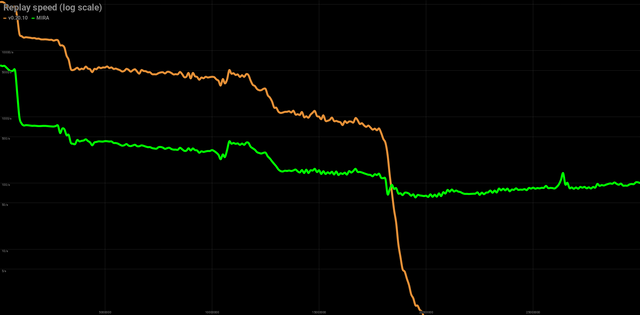
Yes, you guess right, for v0.20.10 a significant drop in performance is around 18M-19M blocks, that’s exactly when shared_memory.bin file grows beyond 16GB (amount of RAM).
I stopped replay process at 20M blocks.
Why?
Because ETA at 18.5M was 3 days, at 19M almost a month, and at 19.5M almost three months.
MIRA starts slow, really, really slow, even 10-20x slower than non-MIRA, but after certain point it doesn’t slow down anymore.
| Replay | v0.20.10 | MIRA |
|---|---|---|
| 20 M blocks | 215 hours+ | 27 hours |
| 30 M blocks | at least months | 61 hours |
Previous episodes of Steem Pressure series
Introducing: Steem Pressure #1
Steem Pressure #2 - Toys for Boys and Girls
Steem Pressure #3 - Steem Node 101
Steem Pressure: The Movie ;-)
Steem Pressure #4 - Need for Speed
Steem Pressure #5 - Run, Block, Run!
Stay tuned for next episodes of Steem Pressure :-)
Bonus: with dedication to future performance improvements
“Run Boy Run” - Woodkid, The Golden Age
If you believe I can be of value to Steem, please vote for me (gtg) as a witness on Steemit's Witnesses List or set (gtg) as a proxy that will vote for witnesses for you.
Your vote does matter!
You can contact me directly on steem.chat, as Gandalf

Steem On
good to see you posting despite not answering my PMs :P
Doing my best to keep "once a month" schedule ;-)
Any rewards and incentives for Delegators?
Posted using Partiko iOS
What do you mean?
MIRA is on the backend.
wtf
I didnt understand this well.
Could you maybe write it in layman terms. Will Mira affect user experience? Transaction speed? Cost of running a witness node? Cost of running a full node? Things like that. :)
No.
No.
Yes, for backup witnesses.
Maybe for top20 witnesses (not main node, but some helper nodes they are also running)
Yes, should reduce significantly.
Awesome! Thx for the explanation. :)
Excellent post with very great pieces of information, as usual.
Thanks @gtg. I can't wait to (find time to) rebuild some of my nodes with MIRA.
MAN!!! I wish you wrote the posts for steemit developers... This is amazing and so so much more readable!! Thank you!!
This is pretty awesome news. Great work. I know this has been in the works for a while and it should help cuts costs for all of those running full nodes because those prices are crazy. Keep being awesome with those wizard coding skills.
As always way over my head. But I just wanted to stop by and say hello. I still can't believe I had dinner in Poland with you and Blocktrades and didn't even know I was sitting at the table with @blocktrades until @teamsteem told me who I ate with. You I knew of course and hanging out was a lot of fun.
Since Poland, in order I've had the luxury of enjoying Thailand, Bali, Greece, Bulgaria, Spain, Florida, and now I'm reconnect with my Ecuadorian girlfriend to see with we can make a travel blogging life together. I just got her the name @travelpro-ilean! How is that for banding. You too can be a Travel Pro how about @travelpro-GTG! hahaha. I'm still plugging away and trying to make my travel blogging dreams come true so as you know Any support to my efforts are always greatly appreciated.
Anyway I hope you and your lovely wife are doing well.
Have a great day! -Dan
Looks to me you are doing a fine job as a witness, I checked and have you on my witnesses, I commented to thank you for the upvote in my last post about Peter Rabbit being mysteriously killed.
Thank you. In fact that upvote was thanks to @elsiekjay.
OK, so, when this drops we can move to 16gb servers, but if anything goes wrong or we have to change something than it'll be 2+ days to reindex?
After Mira is in there are there new ways to speed things up?
Well, MIRA is awesome for many cases, but not for our primary block production nodes.
Top20 witness case is the worst case scenario for MIRA I'm afraid.
That doesn't mean it doesn't help us. It enable us to run seed nodes, api nodes and some other helper nodes on less powerful hardware.
I think that further tuning up a hybrid mode settings can bring some great results, problem is that the optimal configuration for any one specific piece of hardware will vary.
Not to mention differences in infrastructure. For example a state provider with 128GB RAM can replay with awesome speed and deliver state to block producer through 10Gbps network in a decent amount of time.
Yes, there's a plenty of ways to speed things up but it's matter of time/effort needed and priorities. Native RocksDB would be much faster, but also much more time consuming.
Great explanation.
I'm interested in your comment about a 128Gb machine, both for personal reasons and because this is the RAM limit for HEDT PCs (and now also the latest Intel 9th Gen Desktop CPUs).
This means that this is the largest RAM one can get on a PC at reasonable prices.
I noticed that the state size in MIRA is only 81Gb. I assume this means that it will fit in RAM on a 128Gb PC (whereas previously it wouldn't).
I've got the following equipment and wanted to know the best config for a fat node, witness node and seed node.
Are those SATA HDD drives or SSD?
It’s a 500 Gb SSD. I also have 4 Pentium 4560s and an i5 8400 and RAM sitting idle. What can I build for Steem?
Posted using Partiko iOS
So lets just not break the chain :-)
This is so detailed for noobs like me. It really decrease some burden on witness runners. Definitely its power the steem block chain. I will resteem this for my friends.