Steem Sincerity - Working with SteemPlus to crowdsource spam classification training data
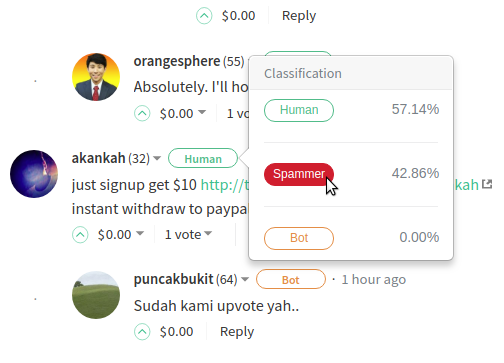
@stoodkev is the developer of the impressive SteemPlus Chrome browser extension, and seeing the potential benefits of the Sincerity project, he and @cedricguillas have added classification labelling to the app (see here). Users will for example see the following kinds of view.

Hopefully as the classification becomes more accurate, this will be an even bigger benefit to users, both of his app and also the Steem community in general. Responsible promotion bots may embrace Sincerity to provide extra information on who should receive their votes, and who shouldn't.
Because he understands this, @stoodkev suggested that we could also use SteemPlus for providing feedback on the classifications, as has come up with a excellent interface for his users to do this, shown below.
So I have added an additional API endpoint for collecting this data to add it to the Sincerity database. This will hopefully serve as an efficient approach to expanding the classification data that is used. Currently the training set is very small, but this will hopefully lead to a much more significant repository. Of course, this data will be subject to a rigorous review process to preclude any possible abuse before being used to train the account classifier, and this may include further community involvement.
I welcome any other sites, apps or extensions to consider incorporating the Sincerity API, and am available to help with integration if necessary.
o, instantlove
Great teamwork @andybets and @stoodkev!
I will implement the spammer-score API as soon as possible into @smartmarket (smartsteem.com) and maybe even @smartsteem as well.
However, my guess is that I have to play around with the spammer score value.
Nevertheless - really great job @andybets!
Thanks very much! I'm working to improve the classification process as we speak, but that's the reason the API provides its estimate of probabilities rather than an absolute classification. App can decide for themselves how to responsibly use the imperfect data.
Any documentation on the classification endpoint? I could start posting my work to add to the training data.
None of my work is automated so I would feed you 'pre-reviewed' data so maybe you want to consider another private endpoint to save you the additional effort. I'm sure there's others like me that could feed in some great data here and expedite your training.
Thank you, I will be in touch. I just need to work out how to assimilate all the information in the most appropriate way.
I totally understand, this is no small task! Let me know how I can help.
Amazing job! It's a pleasure to work with you!
Likewise :)
something needs to be done to seriously improve that classification.
bots that give 3 times as much upvotes than comments (and we are talking just a few hundreds) are classified as top 500 spammers with a 1.0 spammer score (yes, I am talking about my poor @cuddlekitten) while actual spambots leaving thousands of identical comments get a 0.42 human score (see @tomole444).
For the time being maybe you could put a huge warning sticker on the API as it's still pretty damn inaccurate. A lot of people are already embracing the API, and yes, it is a great step forward for the steem ecosystem... but with such inaccuracies it could be quite damaging to the wrong accounts.
Thanks for the feedback. I'm working on improving classification, I have presented the limitations of the software in my posts about the subject. I agree that the classification for tomole444 is not correct, and I also disagree with the scores received by cuddlekitten.
I think there should be a stronger biasing of the data towards evaluating total number of comments and downvote-ratio.
I'll be curious as to how this progresses, but I do indeed think it should be used with caution as it is, as this becomes available to "end-users" already the labels will be taken as true-beyond-doubt and cuddlekitten has been made aware of her new spammer-label by a few confused cuddle friends already.
Okay you need a larger set for training. More peoepl need to paticipate in this effort for it to show more accurate results. This is a great project and I would try to follow it as much as can. Thanks :-)
Came here after @steevc resteemed this post. Thanks to him as well
@tipu upvote this post for 1 sbd :)
Hi @andybets! You have received 1.0 SBD @tipU upvote from @cardboard !
from @cardboard !
@tipU! upvotes with 220% profit and pays 100% profit + 50% curation rewards to investors :)
That's really cool. Could save me time checking up on some commenters.
oh that's neat! :)