Bayesian Networks and Their Value - An Essay, Part 2
If you have not read Part 1, make sure to check it out before reading this post!
Supervised learning refers to when algorithms have training data. Unsupervised learning occurs when there is no training data available. In other words, in supervised learning, we already know the results and the model learns to reach those results. In unsupervised learning, we do not have previous knowledge of the results. Therefore it is up to the algorithm to identify patterns on its own and reach a conclusion. Unsupervised learning is closer to artificial intelligence (Castle, 2017). Research in supervised learning has showed naive Bayes to be competitive with famous, complex, and respected classifiers such as C4.5 (Friedman et al., 1997). As mentioned above, the assumption when using naive Bayes is that all variables are conditionally independent and that they have a parent node to all variables. This condition is completely unrealistic. Consider a BN for assessing the risk in loan applications. Correlations will most likely exist among variables such as age, education level, and income. That is why the good performance of naive Bayes is somewhat surprising. In machine learning, classification is a common task for data analysis and pattern recognition. In order to classify, the creation of a classifier is need. A classifier is a function that assigns a category or label to an instance that is described by a set of attributes. Many classifiers have graph-like representations connecting nodes. Some of those representations include decision trees, decision lists, neural networks, decision graphs, and of course, BNs.
Once a BN has been constructed, it can answer any query about probabilities given a set of evidence and priors. In addition, given evidence, it can update its probabilities by using smart algorithms, called bayesian updating. This is especially important and useful since humans have been shown to be inefficient in this sort of updating (T. D. Pilditch, Hahn, & Lagnado, under review). Furthermore, as humans, we are skilled at qualitative inference, but not at quantitative inference. BNs can be regarded as tools for quantitative inference and therefore be of much use to us. Finally, BNs are machine learning compatible. Machine learning and artificial intelligence algorithms might be some of the strongest tools of our era. Thanks to the flexibility and the simple portrayal of complex situations of BNs, different algorithms from machine learning can be used for the learning portion of a specific BN. This characteristic of BNs makes them very appealing for complex data analysis.
As a BN grows, its complexity grows even faster. Take the naive Bayes classifier I mentioned above, for example. When two variables are perfectly correlated, than the removal of one of them will improve the performance of the classifier. Nevertheless, problems arise if these variables are only partially correlated. If one of those variables is removed, useful information can be lost, and if both stay, the calculations become more expensive. Furthermore, BNs help us portray uncertainty. However, the portrayal of uncertainty is very hard to achieve accurately. When uncertainty meets complexity, the problem becomes exponentially hard to solve adequately. This is a possible make-it-or-break-it point for BNs. Uncertainty needs to be monitored over carefully to make sure it is being portrayed as accurately as possible while the increment in complexity needs to be avoided when possible. When a variable is added, complexity increases. Therefore, a series of actions need to be taken. Uncertainty needs to be revisited to make sure it is being appropriately captured, and complex interactions, mixed types of evidence, and mixed types of relations need to be accounted for.
BNs can provide value to several very important real world scenarios. Since the 1990s, BNs have been studied in the context of medical decision making (P. Lucas, n.d.). BNs bring the statistical and causal knowledge that is very much required in doctors while also taking into account uncertainty that is very present in the medical field. Uncertainties are involved when dealing with diagnosis, treatment selection, planning, and prediction of prognosis (P. J. F. Lucas, Boot, & Taal, 1998). BNs have been tested and used for both diagnosis and treatment selection for patients. The unique structure of BNs allow questions like “What is likely to be the result for the patient if I prescribe X treatment?” to be answered. Nevertheless, developing a model of a realistic medical problem is not easy, and BNs are no exception.
A more concrete example of how BNs can be used in the medical field can be found in the diagnosis and treatment selection for ventilator-associated pneumonia (VAP). VAP is very common in hospitals, especially in the intensive care unit (ICU). Many patients that are admitted into the ICU need respiratory support by mechanical ventilation. Furthermore, many of the patients in the ICU are severely ill which in turn negatively affects their immune system. Both the respiratory support by mechanical ventilation and the negative impact on the immune system of a severe illness are promoters of the development of bacterial pneumonia (Bartlett, 1997). In hospitals, and particularly in the ICU, there is a widespread dissemination of multi-resistant bacteria. In turn, this dissemination will cause the colonization of more individuals after some time. Therefore, the effective treatment of VAP is imperative. In this context, the “right” treatment would be one where the selected antibiotics are effective without causing major side effects. Prescription of antibiotics can be reduced to one of three cases, prescribing none, one, or two drugs. Assume that d represents the total number of possible drugs. Then we would have (d-1 choose 2) + d possible prescriptions. BNs can be expanded to display all these possible combinations. When developing a BN revolving around VAP, its structure can be designed using causal knowledge, dependencies, influences, and correlations. These can be obtained from knowledge of domain experts, literature, or extracted using structure-learning algorithms. The BN can be created with a defined probability distribution but later refined by using existing data.
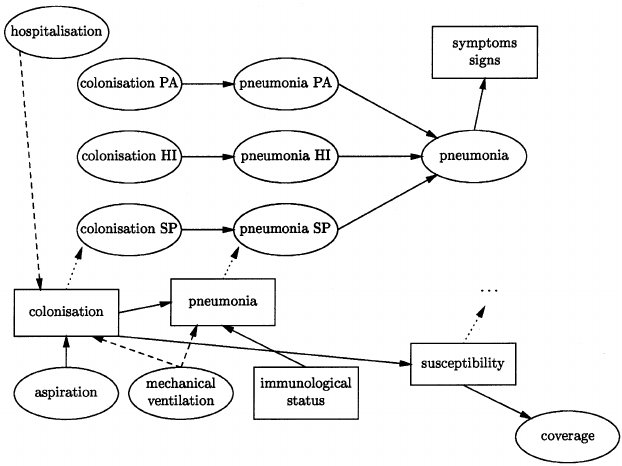
Figure 2. Structure of part of the VAP model (P. Lucas, n.d.). Boxes stand for collections of similar vertices. Dashed arcs indicate temporal influences.
From figure 2, we can observe that colonization has two temporal influences: the duration of hospitalization and the duration of mechanical ventilation. The longer one is hospitalized and the longer one is on mechanical ventilation, one becomes more likely to eventually suffer from VAP. It has been showed that for the purpose of diagnosis, these temporal relations are not important (de Bruijn, Lucas, Schurink, Bonten, & Hoepelman, 2001). However, if prediction of likely causative organisms and treatment selection is what is being looked for, the temporal relations are crucial. Graphs like figure 2 make these relations and the whole problem as a whole easy to understand. Nevertheless, it is important to keep in mind that the underlying formal semantics are sophisticated. If in a BN, all relevant variables for diagnosis and treatment selection are included, then the same network can be used for several different medical-decision making tasks. For the purpose of treatment selection, the best treatment is the one that will maximize coverage and minimize side effects. Therefore, a utility function needs to be implemented. The result is called a decision network, or influence diagram (Shachter, 1986). To turn it back into a BN, the bounded image of the utility function can be mapped to the interval [0,1]. This is yet another strength of BNs they provide great flexibility when deciding what methods to use.

In conclusion, BNs have advantages for both research and applied settings. They are a compact representation of probabilistic models that use probability theory for inference. It is a way for explicitly modeling causal factors. BNs support both predictive and diagnostic reasoning. They also need the collection of less parameter values than a full joint probability model. Furthermore, in a BN, both objective data and subjective beliefs can be represented. Finally, a BN reaches a conclusion based on reasoning that can be auditable since it is explicit. This provides a strength when compared to some “black-box” modeling techniques such as a neural network (Pilditch & Dewitt, 2018). All the strengths mentioned above are the reasons why BNs have been studied and used so much in the past decades. BNs are being used by several industries and fields that can be wildly different from one another. For example, wine classification and forensics. One the reasons is that a BN can be a classifier. Classifiers are needed everywhere. On the other hand, BNs also have weaknesses. Those weaknesses are mainly related to uncertainty and complexity. Hence, caution needs to be exerted when portraying uncertainty or when incrementing the complexity of a BN. Regarding practical uses, specifically in the medical field, the technical issues related to BNs have been extensively studied, but there is very limited literature in building actual systems. The main reason is that nowadays it is still a great challenge to undertake problems of the complexity one usually sees in medicine. Nevertheless, because of its properties, BNs seem to be one of the most suitable foundations for medical decision making under uncertainty. Perhaps one day instead of going to the doctor, we will input all our symptoms and characteristics in a BN to get a diagnosis and treatment with a decent likelihood of being correct.
References:
- Bartlett, J. G. (1997). Management of Respiratory Tract Infections. Blatimore: Williams & Wilkins.
- Ben-Gal, I. (2008). Bayesian Networks.
- Castle, N. (2017, July 13). Supervised vs. Unsupervised Machine Learning. Retrieved May 1, 2018, from https://www.datascience.com/blog/supervised-and-unsupervised-machine-learning-algorithms
- de Bruijn, N., Lucas, P., Schurink, K., Bonten, M., & Hoepelman, A. (2001). Using Temporal Probabilistic Knowledge for Medical Decision Making. In S. Quaglini, P. Barahona, & S. Andreassen (Eds.), Artificial Intelligence in Medicine (Vol. 2101, pp. 231–234). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/3-540-48229-6_33
- Friedman, N., Geiger, D., & Goldszmidt, M. (1997). Bayesian Network Classifiers, 33.
- Lucas, P. (n.d.). Bayesian Networks in Medicine: a Model-based Approach to Medical Decision Making, 6.
- Lucas, P. J. F., Boot, H., & Taal, B. (1998). A decision-theoretic network approach to treatment management and prognosis. Knowledge-Based Systems, 11(5–6), 321–330. https://doi.org/10.1016/S0950-7051(98)00060-4
- Pearl, J. (1988). Probabilistic Reasoning in Intelligent Systems. San Francisco: Morgan Kaufmann.
- Pilditch, T. D., Hahn, U., & Lagnado, D. A. (under review). Integrating dependent evidence: naive reasoning in the face of complexity.
- Pilditch, T., & Dewitt, S. (2018, February). Knowledge Learning and Inference Lecture - Bayesian Networks Part 2: Application to Problems. University College London.
- Shachter, R. D. (1986). Evaluating Influence Diagrams. Operations Research, 34(6), 871–882. https://doi.org/10.1287/opre.34.6.871
- Spirtes, P., Glymour, C., & Schienes, R. (1993). Causation Prediction and Search. New York: Springer-Verlag.
Best,
Interesting, well written and thorough article. This is as close to higher level math as I have been in a long time. haha
Haha, I am glad you liked it regardless.
This post has received a 13.04% upvote from @lovejuice thanks to @capatazche. They love you, so does Aggroed. Please be sure to vote for Witnesses at https://steemit.com/~witnesses.
Release the Kraken! You got a 5.25% upvote from @seakraken courtesy of @capatazche!