Deep Learning Note 3 -- Comparing to Human Level Performance
Following up last post Deep Learning Note 3 — Machine Learning Strategy of Setting up the Learning Target on the Machine Learning Strategy, this post covers the last 3 points on how to work on a machine learning project and accelerate the project iteration. Topics covered in this post are marked in bold in the Learning Objectives. The original post was published on my blog and as usual, the posts are linked together for verification purpose.
Learning Objectives
- Understand why Machine Learning strategy is important
- Apply satisfying and optimizing metrics to set up your goal for ML projects
- Choose a correct train/dev/test split of your dataset
- Understand how to define human-level performance
- Use human-level performance to define your key priorities in ML projects
- Take the correct ML Strategic decision based on observations of performances and dataset
Why human level performance?
Two main reasons:
- As deep learning advances, many applications are now working much better and become feasible to compete with human’s performance.
- The workflow of designing and building machine learning system is much more efficient when you are trying to do something that humans can do. ML has someone (human) to learn from.

In the graph above, the green line is the Bayes (optimal) error, which is a theoretical error that is optimal. In reality, the Bayes error may not be 0%. For example, a image could be so blurry that nobody can tell what it is or an audio clip is so noisy that no one can tell what it contains.
Before surpassing human level performance, the progress achieved could be fast since you have some tactics to apply. However, once crossing that line, it is harder to improve because ML can no longer learn from humans and you don’t know what the true Bayes error is.
So long as ML is worse than humans, you can:
- Get labeled data from humans
- Gain insight from manual error analysis: Why did a person get this right?
- Better analysis of bias/variance.
Reducing Bias or Variance?
The gap between your training error and the human error is called avoidable bias. If there is a large gap, it means your algorithm is not even fitting the training set well. In this case, focus on reducing the bias.
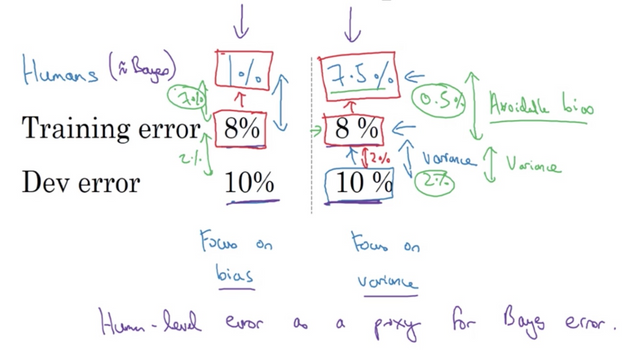
As shown above, on the left side the human error (a proxy of Bayes error) is 1% while the training error is 8%. Apparently you have a much larger room to reduce bias than the 2% variance. On the right side, the avoid bias is only 0.5% while the variance is 2%. This gives you an idea of what to focus on improving.
Human level performance

We use the lowest error we can get (here, 0.5%), as the purpose of approximating the Bayes error. The theoretical Bayes error should be no greater than human-level error, but we don’t know how much lower.
For the purpose of publishing a paper or deploying a system to production, you may choose to you a different error as the human-level error, say option (b). As long as it’s better than a typical doctor, it is a GOOD ENOUGH system in some context. Therefore, you should always know what your purpose is and choose the human-level error accordingly.
Knowing a well-defined human-level error also helps you know whether you can do better on the model. For example, you may think 0.7% is good enough, but in fact you can further reduce it to 0.5%, although you may not have the need to do so.
Surpassing human level performance

On the right side, once you surpass human level performance, it’s hard to tell the direction for improvement:
- Are you overfitting?
- Is the Bayes error even lower? If so, is it 0.3%, 0,2% or 0.1%?
- What should you focus on improving? Reducing bias or variance?
You can still make progress but some of the tools mentioned before may not work anymore. (Question: what should we use then?)
Tasks that ML significantly surpass human
- Online advertising
- Product recommendations
- Logistics (predicting transit time)
- Loan approvals
Why?
- All examples here are NOT NATURAL PERCEPTION(vision, recognition) problems.
- Lots of data, structured data.
However, with deep learning, in some perception-based problem, ML has already surpassed human.
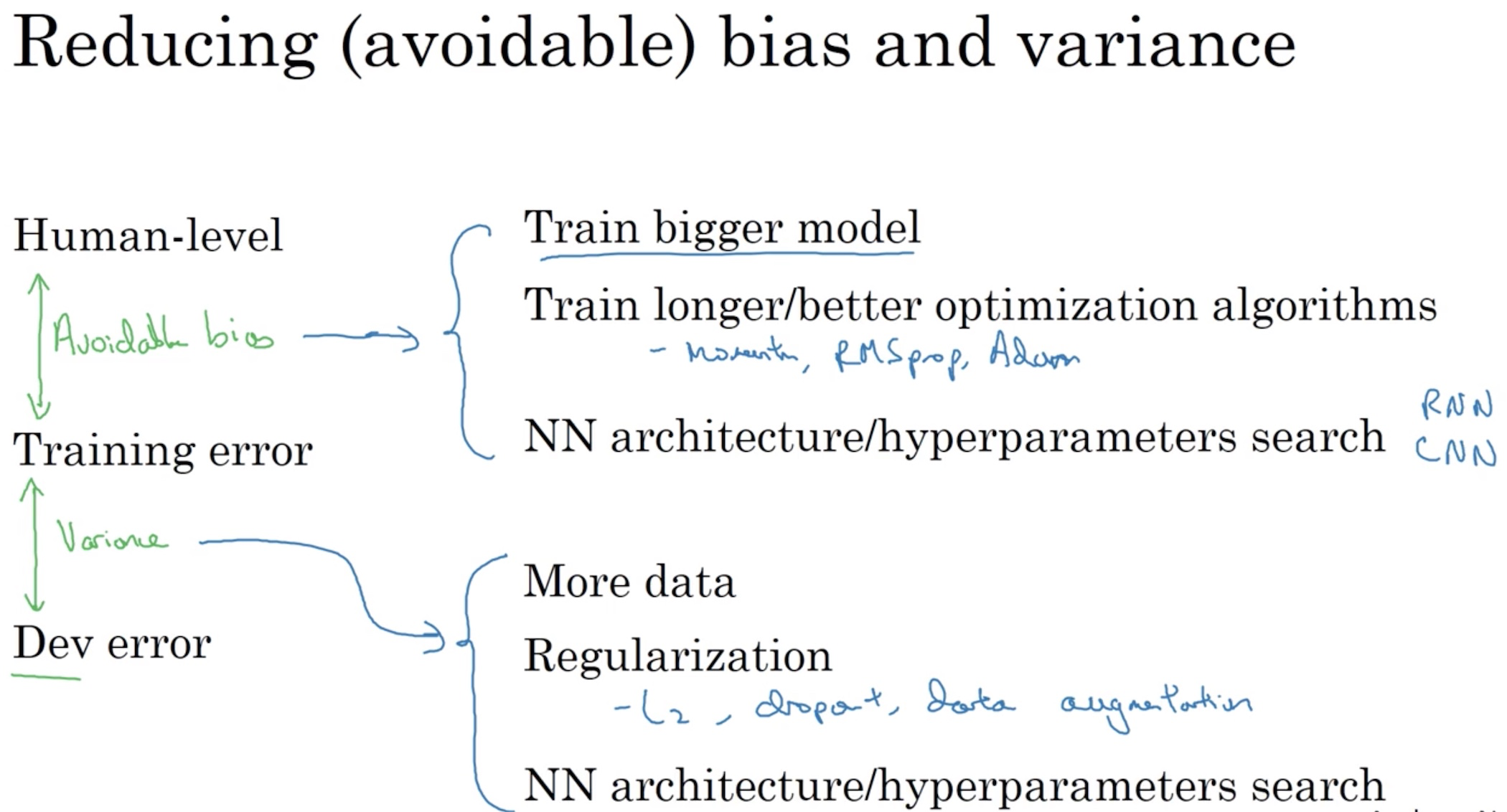
Improving your model performance
To do well on supervised learning, there are two fundamental assumptions:
- You can fit the training set pretty well, achieving low avoidable bias.
- Training set performance generalizes to dev/test set, achieving low variance.
Tools for improvement
Congratulations @steelwings, this post is the third most rewarded post (based on pending payouts) in the last 12 hours written by a Newbie account holder (accounts that hold between 0.01 and 0.1 Mega Vests). The total number of posts by newbie account holders during this period was 1609 and the total pending payments to posts in this category was $1007.35. To see the full list of highest paid posts across all accounts categories, click here.
If you do not wish to receive these messages in future, please reply stop to this comment.
Congratulations @steelwings! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPNice post. Upvoted and followed.