Deep Learning Note 4 -- Error Analysis
Following up last post Deep Learning Note 3 — Comparing to Human Level Performance on the Machine Learning Strategy, the next two posts cover the error analysis and how to handle mismatch training and dev/test sets. As a verification, the original post is published on my blog and linked together.
Carrying out error analysis
Look at dev examples to evaluate ideas
Using the cat classifier as an example, say you have 90% accuracy and 10% error. Your team looked at some errors and found misclassified examples on dogs into cats. Should you spend time making the classifier do better on dogs? It depends. You need to figure out whether it’s worthwhile to do so.
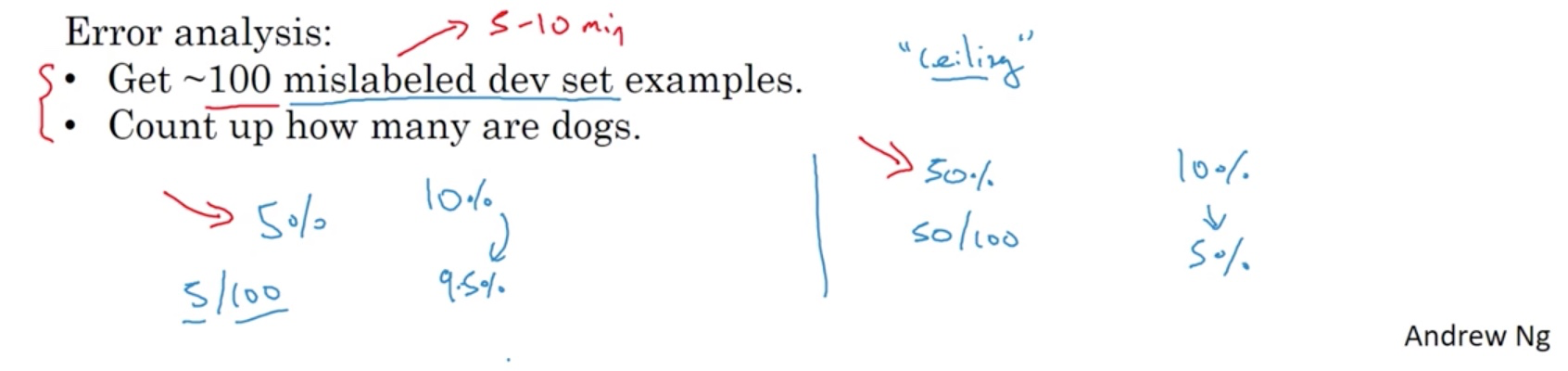
If we check 100 mislabeled dev set examples and find only 5% of them are dogs, then the ceiling of your performance improvement with working on dog picture is 5%. In this case, it may not worth your time. However, if it’s 50%, then you find something that could potentially reduce half the error rate.
Evaluate multiple ideas in parallel
As simple as a spreadsheet on the percentage of different categories of errors (for both false positives and negatives):
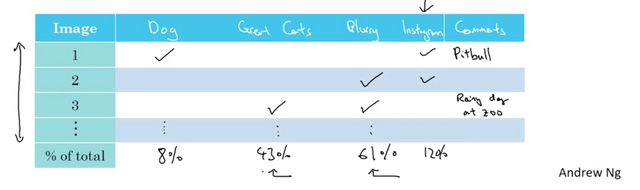
Prioritize
This gives us an idea of the options we should pursue. It shows that no matter how well you do on dog or instgram images you can only improve at most 8 or 12 percent. If you have enough resources, you can have one team working on great cats and the other on the blurry images.
Clean up incorrectly labeled data
Is it worthwhile to fix up incorrectly labeled examples in your data? Your algorithm are learning from wrong examples in the training process.

Training Set
DL algorithms are quite robust to (near) random errors in the training set. You can just leave the error as they are as long as the total data size is big enough and the error percent is not too high. Systematic errors will mess up the DL algorithms.
Dev set
You can do the same error analysis count up. Given your overall dev set error and the percentage of errors caused by incorrectly labeled, you can decide if it’s worthwhile to fix them.
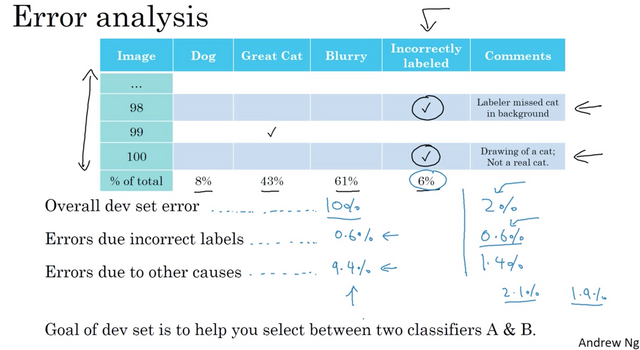
If you decide to fix the incorrect labeled examples, here are some guidelines:
- Apply the same process to your dev and test sets to make sure they continue to come from the same distribution.
- Consider examining examples your algorithm got right as well as those it got wrong. It’s not always done since examining right examples takes a lot more time. Just something to consider.
- Train and dev/test set may now come from slightly different distributions. This is OK and the reason will be explained in later notes. It’s crucial that the dev and test sets come from the same distribution.
Some more advices from Dr. Andrew Ng:
- First, deep learning researchers sometimes like to say things like, "I just fed the data to the algorithm. I trained in and it worked." There is a lot of truth to that in the deep learning era. There is more of feeding data in algorithm and just training it and doing less hand engineering and using less human insight. But I think that in building practical systems, often there's also more manual error analysis and more human insight that goes into the systems than sometimes deep learning researchers like to acknowledge.
- Second is that somehow I've seen some engineers and researchers be reluctant to manually look at the examples. Maybe it's not the most interesting thing to do, to sit down and look at a 100 or a couple hundred examples to counter the number of error. But this is something that I so do myself. When I'm leading a machine learning team and I want to understand what mistakes it is making, I would actually go in and look at the data myself and try to counter the fraction of errors. And I think that because these minutes or maybe a small number of hours of counting data can really help you prioritize where to go next. I find this a very good use of your time and I urge you to consider doing it if those machines are in your system and you're trying to decide what ideas or what directions to prioritize things.
Build your system quickly and iterate
- Set up dev/test set and metric
- Build initial system quickly
- Use Bias/Variance analysis & Error analysis to prioritize next
This advice applies less strongly if you have a lot prior experience or this field has a large body of academic results on the same problem you can rely on. However, if you are tackling a new problem for the first time, then I would encourage you to really not overthink or not make your first system too complicated.
If your goal is to build a system that works well enough, then build something quick and dirty. Use that to do bias/variance analysis, use that to do error analysis and use the results of those analysis to help you prioritize where to go next.