Deep Learning Note 4 -- Mismatched Training and Dev Set
Following up last post Deep Learning Note 4 — Error Analysis, this post focuses on dealing with mismatched data distributions between training and dev/test sets. Deep learning hungers for a lot of training data. It is tempting to put whatever data you can find into the training set. There are some best practices for dealing with situations when the training and dev/test distribution differ from each other. As a verification, the original post is published on my blog and linked together.
Training and testing on different distributions
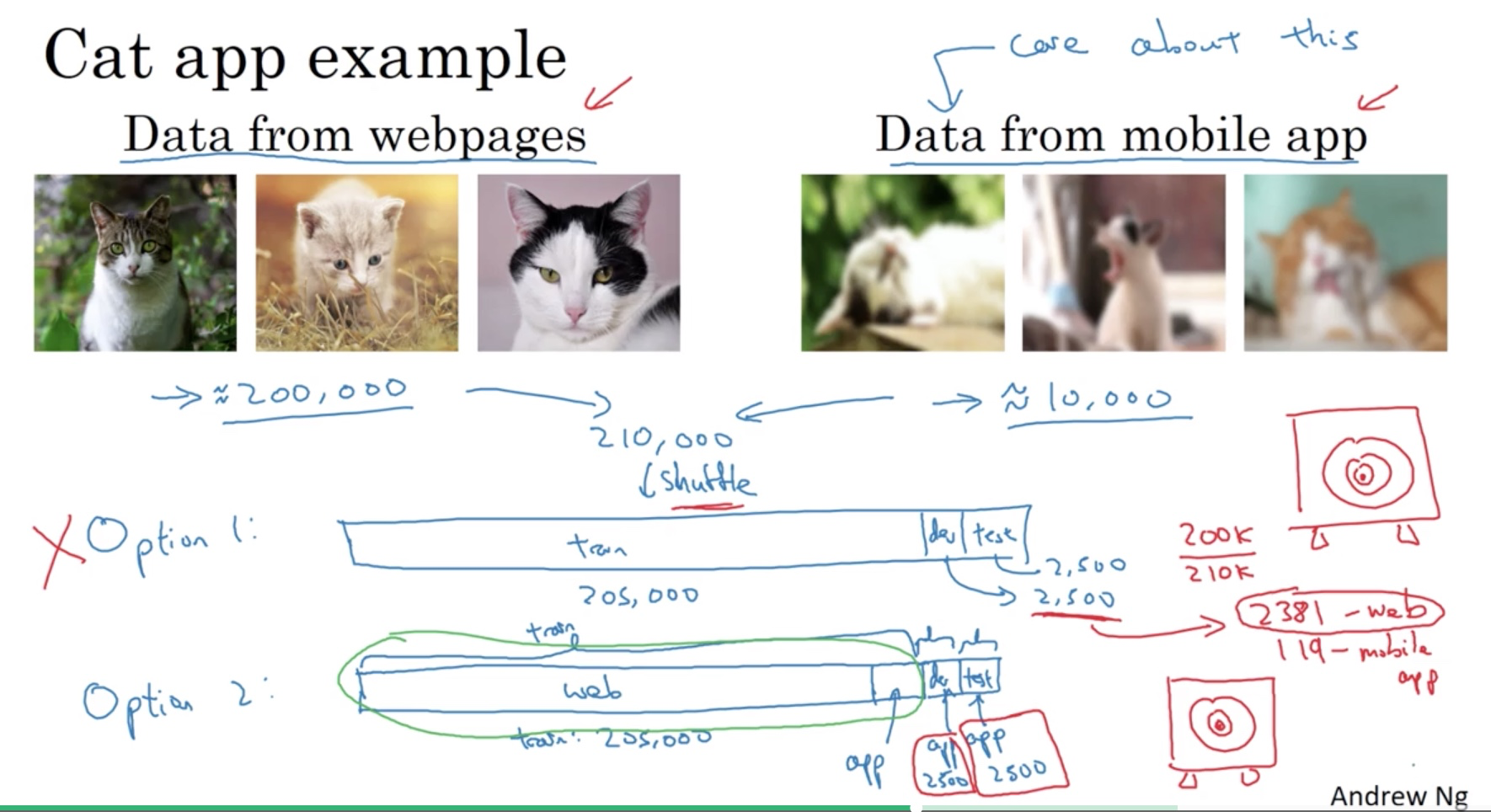
Imagine that you have 10, 000 mobile uploads which you care about. It’s too few for your algorithm to learn. You can find 200,000 high resolution images from the web for training but they are different from production environment.
Option 1
Put both sets of images together and randomly shuffle them. The dev/test set shares the same distribution of training set but the percentage of the mobile upload is very low. Wrong target.
Option 2
Instead, we use the mobile uploaded images for all the dev/test set and put the rest into the training set. Although the training and dev/test set now have different distributions, you are telling the algorithm to target the real situations you care about. In fact this will get you better performance in the long term.
Bias and variance with mismatched data distributions
Data mismatch could complicate our error analysis. Using the same cat classification example, suppose the human error is close to 0%, what if the classifier’s training error is 1% but the dev error is 10%? Is it because of a variance problem (that the algorithm didn’t see the examples similar to what’s in the dev set) or a data mismatch (that the training set is just too easy, i.e., high resolution pictures versus blurry images in the dev set) or both? How much can we contribute the difference to each category?

To separate the two effects, one approach is to carve out a training-dev set out of the original training set. These two sets will have the same distribution. If the difference between them is small, it means there is less a variance problem. At the same time, if the difference between the training error and dev error is high, then there is a mismatch problem. The examples on the right laid out 4 possibilities.

The errors on different data set usually go up. The gap between Dev and Test error measures the degree of overfitting to the dev set. After all, the dev and test sets have the same distribution. If there is a large gap, then your algorithm may have overfit the dev set and you should find a larger dev set.
Occasionally you may find situations where the dev and test errors are actually lower than the training or training dev error. This is because the training data are harder than the dev/test set and your actual application data is easier.
Summary
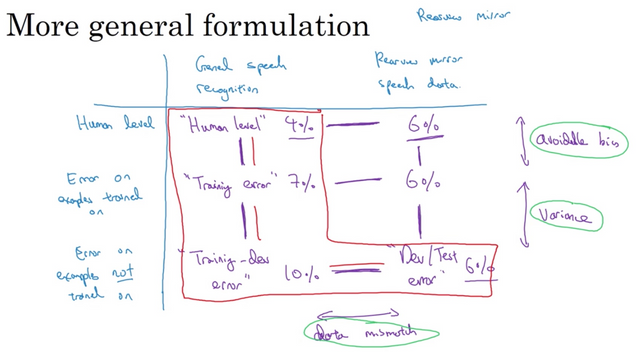
By analyzing the errors and their gaps in the red box we can usually find a promising direction on what to focus on next.
Sometimes it’s also useful to fill out the whole table outside the red box. For example, by comparing human level performance on the general data and target data, we know that the target data is harder. The training error and dev/test error on the target data also shows that your algorithm is already doing pretty well. The way to get the training error on the target set is to take some target data, put it in the training set so the neural network learns on it as well, and then you measure the error on that subset of the data.
Addressing data mismatch
- Carry out manual error analysis to try to understand difference between training and dev/test sets. Try to figure out how the dev set is different or harder than the training set.
- Make training data more similar or collect more data similar to dev/test data.
Artificial data synthesis

Artificial data synthesis helped boost the performance for voice recognition applications. However there are something you need to watch out. If you have only 1 hour of noise and have to apply it repeatedly to an audio with 10,000-hour of data, then your algorithm may overfit to that 1 hour of background noise, although to human ears, it is perfectly fine. We can’t tell the difference. One hour is just like using 10,000 hours of unique noise.
Cool! I follow you.
Congratulations @steelwings! You have received a personal award!
Click on the badge to view your Board of Honor.
Do not miss the last post from @steemitboard:
Congratulations @steelwings! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!