Voting theory in Ensemble Learning
What Will I Learn?
- You will learn how to use resampling to avoid class imbalance problem
- You will learn how to use Borda count to maximize your ensemble accuracy
- You will learn the importance of diversity in ensembles
Requirements
- Machine Learning
- Ensemble Learning Theory
Difficulty
- Intermediate
Tutorial Contents
1. Introduction
Ensemble learning is a machine learning paradigm where multiple learners are trained to solve the same problem. It draws inferences from a set of hypothesis rather than a single hypothesis. It is expected that each of the learners in the ensemble are diverse so that their opinion count. If they aren't diverse, then their predictions become correlated and the whole system is as effective as a single classifier.
In this post, we are focussing on the classification problems. Generally in practice, either majority voting or plurality voting is used. In the literature of Voting theory, there are many other voting techniques which is fairer in choosing the best candidate than these two methods. In this post, we implement those methods and check their influence on the performance of the classifier.
We are assuming that every voter has the same influence on the outcome of the voting, each voting decision is independent of other voter's decisions, the ensemble is moderately diverse and the voting decision is unbiased.
Independence and diversity is ensured by bootstrapping the training data. Voting bias can be avoided by duplicating the entries associated with less occurring class labels to avoid class imbalance problem.
2. Voting Theory
Suppose we have 10 base learners trying to predict one of these three labels trying to predict one of the three categories whose labels are H, O and A. The following table shows their votes and the alternatives. Alternatives are derived from probability distribution of the prediction.
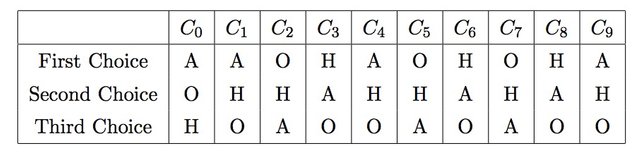
These individual votes can be combined and is made into a preference schedule which shows number of voters in the top row and their ranked preferences.
The following code would taken in the predicted probabilities in form of numpy array and would return the preference schedule.
import operator
def generate_preference(pred_proba,labels):
'''
Accepts:
pred_proba: Numpy array containing probabilities
labels: list containing output labels
Returns: Preference in form of list of list
'''
pred_proba = pred_proba[0]
num_class = pred_proba.shape[0]
vote_dic = {}
for i in range(num_class):
vote_dic[labels[i]] = pred_proba[i]
sorted_x = sorted(vote_dic.items(), key=operator.itemgetter(1))
sorted_x.reverse()
preference = []
for i in range(num_class):
preference.append(sorted_x[i][0])
return list(preference)
Running this code, we get the preference schedule for the current problem from the predicted class distributions.
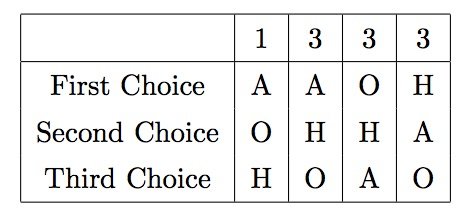
For the plurality method, we care only about the first choice options. If we total them up, we can easily see that A is the clear winner. But is it fair?
In the above preference schedule, let’s just focus on H vs A. In the first two columns, A is the winner as it has higher preference than H. In the last two columns, H is the winner for the same reasons. It is clear that 6 out of 10 classifiers prefer the category H.
This doesn't seem to be fair. Condorcet noticed it and devised Condorcet Criterion which says that If there is a choice that is preferred in every one-to-one comparison with other choices, then that choice should be the winner. We call this winner the Condorcet Winner.In the above example, we can easily verify that H is preferred over O and hence, H is the Condorcet Winner.
But is this perfect? Turns out one can modify the preference schedule such that we will get a cyclic preference. X preferred over Y, Y preferred over Z and Z preferred over X.
But in the situations where such cyclic preference doesn't exist, this voting method can be used.
Another voting method to look at is Borda Count. This method is majorly used worldwide in determining the winner. It describes a consensus-based voting system since it can sometimes choose a more broadly acceptable option over one majority support. It considers every voter’s entire ranking to determine the outcome.
To find the Borda winner, we assign points in the order of preferences. Higher preference gets higher point. One such initalizations could be (3,2,1) where first preference gets 3 points, second preference gets 2 points etc. Then we take the cumulative sums and find the class which scored highest points.
The following code implements the borda count method.
def borda(preference_ballot):
'''
Accepts: list of list => preference_ballot
Returns: Winner
'''
counts = {}
candidates = list(set(preference_ballot[0]))
max_point = len(candidates)
for i in range(max_point):
counts[candidates[i]] = 0
for pref in preference_ballot:
for i in range(len(pref)):
counts[pref[i]] += (max_point -i)
return int(max(counts, key=counts.get))
It should be noted that these voting methods are useful in multiclass setting. In the case of two class classification, Majority voting should be preferred as it is fair.
3. Experimentation
The dataset considered for this experimentation is Glass Dataset from UCI Machine Learning repository.
First step is to load the data and clean it.
import pandas as pd
import numpy as np
columns=['id','RI','Na','Mg','Al','Si','K','Ca','Ba','Fe','Type']
dataset = pd.read_csv('glass.txt',names=columns)
dataset['Type'] = dataset['Type'].astype(int)
labels = dataset['Type'].unique()
yColumn = len(columns) -1
trainColumns = range(yColumn)
X = np.array(dataset.drop(['Type'], 1))
y = np.array(dataset['Type'])
Looking at the class distributions, we can observe that majority class is 2. We need to upsample the minority class so that class imbalance problem is avoided.
from sklearn.utils import resample
df_majority = dataset[dataset.Type==2]
df_minority1 = dataset[dataset.Type==1]
df_minority7 = dataset[dataset.Type==7]
df_minority3 = dataset[dataset.Type==3]
df_minority5 = dataset[dataset.Type==5]
df_minority6 = dataset[dataset.Type==6]
df_minority_upsampled1 = resample(df_minority1,
replace=True, # sample with replacement
n_samples=76, # to match majority class
random_state=123) # reproducible results
df_minority_upsampled7 = resample(df_minority7,
replace=True, # sample with replacement
n_samples=76, # to match majority class
random_state=123) # reproducible results
df_minority_upsampled3 = resample(df_minority3,
replace=True, # sample with replacement
n_samples=76, # to match majority class
random_state=123) # reproducible results
df_minority_upsampled5 = resample(df_minority5,
replace=True, # sample with replacement
n_samples=76, # to match majority class
random_state=123) # reproducible results
df_minority_upsampled6 = resample(df_minority6,
replace=True, # sample with replacement
n_samples=76, # to match majority class
random_state=123) # reproducible results
# Combine majority class with upsampled minority class
df_upsampled = pd.concat([df_majority, df_minority_upsampled1,df_minority_upsampled7,df_minority_upsampled3,df_minority_upsampled5,df_minority_upsampled6])
print(df_upsampled.Type.value_counts())
X = np.array(df_upsampled.drop(['Type'], 1))
y = np.array(df_upsampled['Type'])
We now divide the data into training and testing.
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.89, random_state=42,stratify = y)
Test dataset is huge because the dataset is simple to train. We feed this dataset to ensemble of four classifiers.
from sklearn import preprocessing,neighbors,svm
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import tree
clf1 = neighbors.KNeighborsClassifier()
clf2 = svm.SVC(probability=True)
clf3 = LogisticRegression()
clf4 = tree.DecisionTreeClassifier()
clf1.fit(X_train, y_train)
clf2.fit(X_train, y_train)
clf3.fit(X_train,y_train)
clf4.fit(X_train,y_train)
accuracy_1 = clf1.score(X_test, y_test)
accuracy_2 = clf2.score(X_test, y_test)
accuracy_3 = clf3.score(X_test,y_test)
accuracy_4 = clf4.score(X_test,y_test)
print(accuracy_1,accuracy_2,accuracy_3,accuracy_4)
#(0.89901477832512311, 0.81527093596059108, 0.9211822660098522, 0.91133004926108374)
Then we find the performance of borda count over majority voting.
def get_prediction_borda(test_example):
ensemble = [clf1,clf2,clf3]
labels = list(clf1.classes_)
preference_ballot = []
for base_learner in ensemble:
preference_ballot.append(generate_preference(base_learner.predict_proba(test_example),labels))
return borda(preference_ballot)
from collections import Counter
def get_prediction_majority(test_example):
ensemble = [clf1,clf2,clf3]
predictions = []
for base_learner in ensemble:
predictions.append(base_learner.predict(test_example)[0])
occ = Counter(predictions)
return int(max(occ,key=occ.get))
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
predictions_borda,predictions_majority = [],[]
for test_example in X_test:
predictions_borda.append(get_prediction_borda(test_example))
predictions_majority.append(get_prediction_majority(test_example))
print('Accuracy with Borda Count: ',accuracy_score(y_test,predictions_borda))
print('Accuracy with Majority Voting',accuracy_score(y_test,predictions_majority))
print('F-1 score of Borda Count',f1_score(y_test,predictions_borda,average='macro'))
print('F-1 score of Majority Voting Classifier',f1_score(y_test,predictions_majority,average='macro'))
The output comes like this
('Accuracy with Borda Count: ', 0.95320197044334976)
('Accuracy with Majority Voting', 0.89901477832512311)
('F-1 score of Borda Count', 0.95317662826622429)
('F-1 score of Majority Voting Classifier', 0.89689270238362406)
Here all the four base learners are having approximately similar accuracy so the voting system follows the assumption of each having similar influence on the output. They were trained on a balanced dataset so opinion is also unbiased. As these assumptions follows, Borda count method outperforms Majority Voting method. When these conditions doesn't hold, we can use majority voting.
Posted on Utopian.io - Rewarding Open Source Contributors
Hey @brobear1995 I am @utopian-io. I have just upvoted you!
Achievements
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x
Thank you for the contribution. It has been approved.
Like your work
You can contact us on Discord.
[utopian-moderator]
Thank you!
@brobear1995, Approve is not my ability, but I can upvote you.
You got a 9.09% upvote from @sunrawhale courtesy of @brobear1995!
This service has been created with the help of @yabapmatt so please show your support by voting for him for witness!
This post has received a 0.18 % upvote from @drotto thanks to: @brobear1995.