Seed - Development - Transaction Squashing & Blocks

Repository
https://github.com/Cajarty/Seed
Overview
The following development changes were based upon the design article Transaction Squashing and the discussion articles Transaction Squashing Proposition and Transaction Squashing Considerations For Jitter.
Transaction squashing is the simple concept of merging sequential changes into one single change. We are trying to prove this concept in order to keep the size of our DAG and Blockchain lean. As a high throughput, low latency blockchain product, a major fear is the sheer size of our system growing at an unsustainable rate. Transaction squashing is our attempt at keeping the growth size sustainable.
This article goes into the base implementation, including squashing transactions into blocks, squashing blocks into more condensed blocks, triggering the squashing mechanism, and the blockchain storage of these newly created blocks.
Block
A "Block" in Seed is not the same as a traditional Block. In regular blockchain systems, blocks are fully verifiable, as they are a key component of the validation system. In Seed, transactions are already valid once they enter a block. In traditional blockchain systems, a miner creates the block, finding a nonce and doing a computationally heavy problem solving activity known as "mining". In Seed, blocks are fully deterministic in their creation, with miners being excluded from the picture.
Squashed Data
Due to transactions being validated by the entanglement/DAG, all blocks are inherently trusted. In order to keep the block chain lean, this squashing process remove a large amount of the information for each transaction. The goal was to keep enough information that users can validate a blocks legitimacy, without needing to know all the information that came with each transaction.
When a block is created, all transactions have key pieces of information extracted. Enough that a user can execute all the claimed transactions and get an end change set they should have gotten. These combined changes to the ledger can also be found inside the block itself. If the execution of all transactions matched the squashed changes, we know the claimed changes are honest.
Implementation
The block implementation can be found in the /seedSrc/block.js file. As a block is simply a data storage object with minimal logic. The only functions on the block class relate to calculating its hash.
A block's data, in practice, looks like the following:
{
"blockHash" : "Base-56 Encoded Hash",
"generation" : 1,
"transactions" : {
Transaction1Hash : [ Sender Address, Module Checksum, Function Checksum, Passed In Arguments, Signature ]
Transaction2Hash : [ Sender Address, Module Checksum, Function Checksum, Passed In Arguments, Signature ]
},
"changeSet" : {
"ModuleName" : {
"localData" : 3
},
"userData" : {
"ABC" : {
"privateData" : 2
},
"DEF" : {
"privateData" : 1
}
}
}
}
Blocks can be created through a newBlock exported function. This is accessible by requiring "seedSrc/block.js" or through the LLAPI entrance point in the seedSrc/index.js file.
Blockchain
In traditional blockchains, a "blockchain" is simply a cryptographically secured variation of a data structure known as a linked list. Each block is a node on this list, who knows only of the node before it. In Seed, blocks do not know of the blocks which come before it, and are stored in multiple lists rather than one. Therefore, the name "chain" is slightly misleading, however is still being used to be consistent with other blockchain systems. A "Blockmapping" would technically be a more fitting name.
In Seed, once transactions are squashed into a block, they are added to the blockchain as a "first generation testament block". If the newly created block's hash matching the requirements for triggering the squashing mechanism, all blocks of the same generation are squashed together and re-added into the blockchain, creating a more condensed "second generation" block. This cycle can repeat indefinitely, keeping the size of the blockchain lean.
Implementation
The blockchain implementation can be found in the /seedSrc/blockchain.js file. This file exports one function which is used for adding another block.
This function will add a block to storage in memory, and may trigger the squashing mechanism of blocks if it has the right hash for it.
The blockchain data structure may look like the following, where blocks of the same generation are organized together:
{
"1" : [ FirstGenerationBlock, FirstGenerationBlock, FirstGenerationBlock, FirstGenerationBlock ],
"2" : [ SecondGenerationBlock, SecondGenerationBlock ],
"4" : [ FourthGenerationBlock ]
}
Squasher
The "Squasher" file wraps the logic regarding the "squashing mechanism" mentioned above. The file which contains the Squasher has three exports, one for squashing Transactions into a block, another for squashing Blocks into a more condensed block, and a final for checking whether a hash should trigger the mechanism.
Triggering The Squashing
Not all transactions or blocks trigger the squashing mechanism. Only ones who, when hashed, begin with a certain pattern will work.
For the time being, that pattern is having a hash start with either the ASCII value "0" or "1". These hashes are base 56 encoded, therefore this provides a 1 in 26 change of triggering the process. At a later date, this logic will be fine-tuned with a more logical occurrence, however in the mean time it is to be kept low so it triggers frequently for unit tests.
Relative vs. Absolute Changes
Squashing relative changes are less complicated than absolute changes. That is, squashing "Bob sent Jill $10" and "Jill sent Bob $5" into "Bob sent Jill $5" is easy. Squashing "Bob set the sign to say Hello" and "Jill set the sign to say World" is hard, since whether the end result is "Hello" or "World" comes down to jitter.
If we know the order the transactions came in, then it is an easy problem to solve. However, other than a few rough heuristics (such as knowing the order of nodes directly connected in a graph), we can't truly tell which transaction was created first.
In order to accomplish this for consistency, as all blocks must be fully deterministic in their creation, transactions now claim a timestamp upon their creation. This timestamp is stripped from them during the squashing phase, however it is used for ordering the blocks. As long as we know the order, we can consistently make absolute changes, like setting strings or objects.
This claimed timestamp is subject to change, however. It poses a number of minor issues, such as giving users a way to re-roll their hash or lie about their timestamp. For now it will be used, however ideally we want the end implementation to not rely on timestamps at all, as they are not easy to prove the authenticity of.
Squashed Data
As stated in the Squashing design article, the act of squashing data is taking multiple objects which represent changes to the ledger, and condensing them into a single object.
For example, the following two ChangeSets:
{
"Seed" : {
"ABC" : {
"balance" : "+10"
},
"DEF" : {
"balance" : "-10"
}
}
}
and
{
"Seed" : {
"ABC" : {
"balance" : "+10"
},
"GHI" : {
"balance" : "-10"
}
}
}
Would look like the following after squashing
{
"Seed" : {
"ABC" : {
"balance" : "+20"
},
"DEF" : {
"balance" : "-10"
},
"GHI" : {
"balance" : "-10"
}
}
}
Implementation
The implementation can be found in the /seedSrc/squasher.js.
The algorithm for squashing is mostly done in helper functions which are shared by the transactionsToBlock and blocksToGenerationBlock exported functions.
Firstly, transactions are put into a mapping of transaction data. An extracted transaction is referred to as a "lean transaction" due to requiring much less data. The mapping stores the transactions' hash as the key, and the value stored is an array containing a transactions sender address, executed modules checksum, executed functions checksum, the arguments passed into the transaction, and the transaction's signature. The lean transactions will look like the following when stored in a block.
"transactions" : {
Transaction1Hash : [ Sender Address, Module Checksum, Function Checksum, Passed In Arguments, Signature ]
Transaction2Hash : [ Sender Address, Module Checksum, Function Checksum, Passed In Arguments, Signature ]
}
Secondly, transactions have their "changeSets", the object regarding how they changed the ledger, squashed into one. All numbers are squashed together as if they are relative (i.e. a 5 and a -2 squash into a 3), all strings have the newer version overwrite the older (i.e. "Hello" and "World" squash into "World"), and all objects recursively are squashed following this same algorithm. The squashed data may look like the following in a block.
"changeSet" : {
"ModuleName" : {
"localData" : 3
},
"userData" : {
"ABC" : {
"privateData" : 2
},
"DEF" : {
"privateData" : 1
}
}
}
Afterwards, the block is given a generation. If its being created out of raw transactions, it starts with a generation value of "1". If its created out of other blocks, it is given the generation which is 1 higher than that of the blocks that were squashed (i.e. squashing a bunch of third generation blocks creates a single fourth generation block).
Entanglement Update
The Entanglement was updated in order to take advantage of the newly implemented squashing mechanism. Once a transaction becomes valid, its hash is checked to determine whether it is a transaction which would invoke the squashing mechanism. Once transactions are squashed, the entanglement is cleaned up with transactions removed, as they are no longer stored in the DAG.
Implementation
In the /seedSrc/entanglement.js file is where the implementation took place.
The helper function "tryTrust" possess the logic regarding invoking the squashing mechanism. This check triggers once a transaction is fully validated.
Additionally, the helper functions "getAllValidatedParents" and "removeAllTransactionsFromEntanglement" had to be created for the DAG cleaning process.
getAllValidatedParents
This helper function takes a transaction from the DAG and recursively finds all validated transactions it indirectly help validate. This function would pick the validated parents out of the following diagram, which are the transactions which would be squashed into a block.
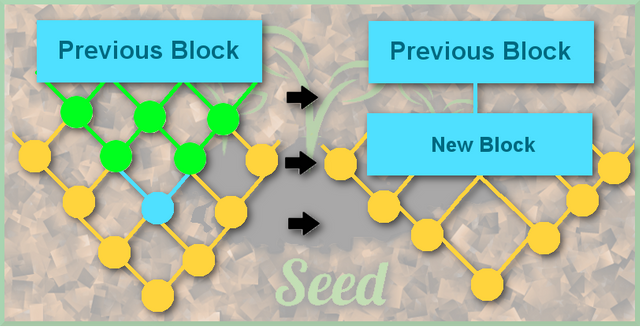
removeAllTransactionsFromEntanglement
This function takes an array of transactions, deleting them from the entanglement. This is used to keep the DAG's memory use low, as historic data is stored in blocks and no longer needed in the entanglement after squashing occurs.
Honourable Mentions
Transaction Timestamps
Transactions were given a timestamp value which is added during the construction of a transaction. This value is the current timestamp stored as epoch time (ticks since January 1st, 1970). This was done to allow transactions to easily be ordered.
This change in its current form cannot be permanent, as it opens up a security dilemma where users can lie about their timestamp by a small amount (reliably within a second or two), and therefore re-roll their hash. Re-rolling the hash may allow them to have a degree of control over the squashing mechanism (potentially forcing squashes to be occurring more often than intended), or potentially give users a limited amount of indirect control over the pseudo-random number generator's Seeding.
Ledger Implements Squashing
Previously, the ledger had its own "squashing" implementation for applying each transactions changes to the ledger.
However, that implementation was limited. It could only look one-level deep, preventing modules from using nested objects in their storage.
This effectively prevented anything deeper than the relationship "Game.User.Inventory.Item". Any deeper of relationship and it would fail.
The squasher.js file's implementation works recursively, allowing data to go as deep as required. A Module could now store, for example, "Game.User.Inventory.Item.Health", which it could not have previously.
References
Seed - Dev. Discussion - Transaction Squashing Proposition (Part 1)
Seed - Dev. Discussion - Transaction Squashing Considerations For Jitter (Part 2).
GitHub
https://github.com/CarsonRoscoe
Thank you for your contribution. This is the type of contribution which we really look forward too. Really well written where each and everything is well explained too and a significant update to the project.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @codingdefined!
So far this week you've reviewed 4 contributions. Keep up the good work!
You have a minor typo in the following sentence:
It should be out of instead of our of.Thank you, it has been corrected :)
Great work once again, @carsonroscoe!
Hey, @carsonroscoe!
Thanks for contributing on Utopian.
Congratulations! Your contribution was Staff Picked to receive a maximum vote for the development category on Utopian for being of significant value to the project and the open source community.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!