Python For Data Science (#1)- Gender Classification (Male or Female)
Repository
https://github.com/scikit-learn/scikit-learn
What Will I Learn?
- Python for data science
- Scikit-learn library
- Labelled data prediction
- Simple machine learning classifiers
Requirements
- A working computer running macOS , windows or linux distribution(ubuntu preferred).
- An installed Python 3(.6) distribution, such as the Anaconda Distribution.
- Dependencies ( numpy , scipy and scikit-learn).
- Intermediate knowledge about python programming.
Difficulty
- Intermediate
Tutorial Contents
Python For Data Science (#1)- Gender Classification (Male or Female)
hello guys,
In this tutorial we will learn about classification of gender (male or female) if given the body metrics of the subject and predict whether it's male or female after training the classifier over an sample data of body metrics labelled male and female.
Choosing best classifier for an problem can decided based upon their results and requirement check out this link to know more.
Setup (installing required dependencies) :-
If you haven't installed Scikit-Learn and you want to do it then you can check out this link, it has all the information regarding installing the Scikit-Learn library . First create a directory in which you can run tests and predict using coded Python file. The first step will obviously be opening the code editor. After opening the code editor you will need to import required module from sklearn(package) which you can do by typing from sklearn import (classifier name).

In this tutorial we will use decision tree classifier.
So, now we're ready to write our script we'll start by importing it first as we should for all the dependencies we're going to use a specific sub module of scikit-learn(sklearn) called tree that wil let us build a machine learning model called a decision tree.
Decision tree :-
It is like a flowchart that stores data , it asks each labelled data point it recieves a yes-or-no question , does it contain X or not if the answer is yes the data moves one direction if the answer is no it moves in the other it'll build every node in the tree the more data points it receives then when we have a new unlabeled data point we can feed it to the tree it'll ask if a series of questions until it labels it that label is our classification.
The more data we train it on the more accurate the classification.
{kind=link}
DATA SET (sample)
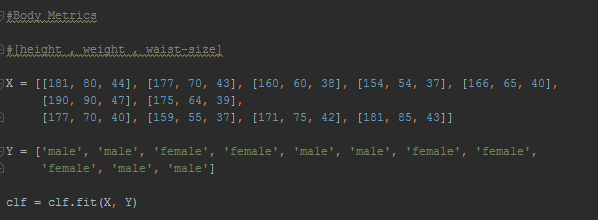
Lets start by creating our data set programmatically we'll write our first variable for dataset , X as a list of Lists a variable is a value that can change and we'll store a list of Lists in it a list is a data type in python that can store a sequence of values here each value is a list itself that contains three numbers that represent the height , weight and shoe-size of a person we'll write 11 of these so our data set size is only 11 people and we will write one more variable called Y to store list of labels each label is a gender(male or female) and is associated with a list of body metrics in the previous list , we'll write them as strings which is a data type used to represent text instead of numbers.
Now that we have our data set we'll want to define a variable to store our decision tree model let's call it clf.
CLF short for classifier and it'll store our decision tree classifier we can reference our tree dependency directly by calling it here and initialize the decision tree by calling the decision tree method on the tree object.

Now that we have our tree variable we can train it on our data set we'll call the fit method on the classifier variable which takes two arguments will store our X and Y variables as the arguments and the result will be stored in the updated clf variable the fit method trains the decision tree on our data set.
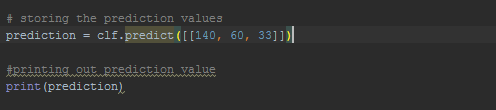
Let's test it by classifying the gender of someone given a new list of body metrics we'll create a variable called prediction to store the result and call the predict method of our decision tree to predict the gender given these three values in a list.
then we can print it out determine all via the print command we can run the script in terminal by saving it as filename . py and running it via the Python filename.py command.
Outputs:-
Model Name:- Decision Tree Classifier
| Input Metrics (height , weight and shoe-size) | Output Label |
|---|---|
| 140, 60, 33 | Female |
| 160, 80 ,43 | Male |
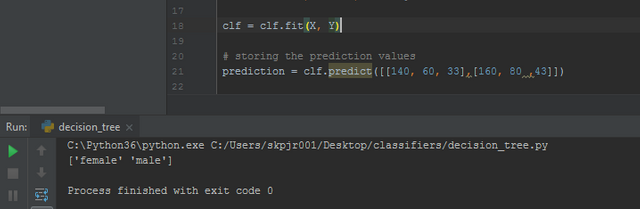
So, in the above data set metrics shoe-size metric can also be replaced by waist size because to classify an subject from other we need an discriminating factor between them , so the more discriminating factor with more data values provides accurate prediction.
You can also use other classifiers to make classification models for prediction I've given the code for those too so try to compare the results and you can even change the metrics factors too.
Thank you for your contribution.
While I liked the content of your contribution, I would still like to extend few advices for your upcoming contributions:
Looking forward to your upcoming tutorials.
Your contribution has been evaluated according to Utopian rules and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post,Click here
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
thanks for your quick review and suggestions i'll show my improvement in upcoming posts.
You have a minor misspelling in the following sentence:
It should be until instead of untill.Thanks! you are fast and efficient.
Hey @skpjr001
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Contributing on Utopian
Learn how to contribute on our website or by watching this tutorial on Youtube.
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
This post has been rewarded with 30% upvote from @indiaunited-bot account. We are happy to have you as one of the valuable member of the community.
If you would like to delegate to @IndiaUnited you can do so by clicking on the following links: 5SP, 10SP, 15SP, 20SP 25SP, 50SP, 100SP, 250SP. Be sure to leave at least 50SP undelegated on your account.
Please contribute to the community by upvoting this comment and posts made by @indiaunited.