Graph Analytics on IMDB Top 250 movies - Part 1
Repository
https://github.com/yashwanth2804/Spark-IMDB-Graph

What Will I Learn?
- You will learn how to extract data from websites
- You will learn how to use apache spark as ETL tool
- You will learn some distributed computing concepts
Requirements
System Requirements
FreeBSD 10.3 or later
Linux 2.6.23 or later with glibc
macOS 10.10 or later
Windows 7, Server 2008R2 or later
with atleast i3 or equivalent AMD processor and 8gb ram is preferred.
Programming Skills
Better if had good understanding of python,scala languages
Atleast minimum knowledge on how distributed computing works
Some hands-on work on apache spark,any word count example.
Difficulty
- Intermediate
Tutorial Contents
Graph Analytics on IMDB Top 250 movies - Part 1
Main Theme
The main intention of this tutorial is to get the artists who have more shared connections(ranking) in the IMDB top 250 movies and how one artist connected to other artists.
Data Extraction
Language : Python
Tools/lib : csv,Itertools,lxml,requests
Task-1 : Scrape all top 250 movies titles
- create a file
ImdbTitleScrapper.py - Import required tools
import csv import itertools from lxml import html import requests - Get the endpoint url
#Imdb top 250 - https://www.imdb.com/chart/top #Imdb top rated Indian - https://www.imdb.com/india/top-rated-indian-movies/ #Imdb top rated Telugu Movies - https://www.imdb.com/india/top-rated-telugu-movies #Imdb top rated Tamil Movies - https://www.imdb.com/india/top-rated-tamil-movies/ #Imdb top rated Malayalam Movies - https://www.imdb.com/india/top-rated-malayalam-movies - next part is to provide this url to
requestswhich returns a ElementTree. So that we can perform a global XPath query against the document.pageUrl = 'https://www.imdb.com/chart/top' page = requests.get(pageUrl) tree = html.fromstring(page.content) #<class 'lxml.html.HtmlElement'> MoviesList = tree.xpath('//td[@class="titleColumn"]') #[<Element td at 0x7f4a175decb0>, <Element td at 0x7f4a175ded08>,....]
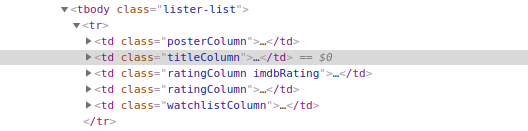
Fig - selecting titleCoumn element for every table row
- Now that we have a list of all Elements which matched the query, we further proceed to scrap the title name for each element using typical split by "/" operation
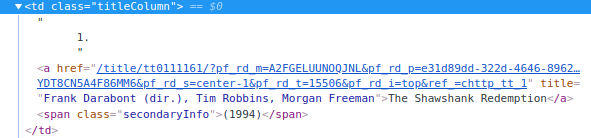
Fig - Expanded view of td which contains movie title
for i in MoviesList:
title_url = i.xpath('./a/@href')
#['/title/tt0111161/?pf_rd_m=A2FGELUUNOQJNL&pf_rd_p=e31d89dd-322d-4646-8962-327b42fe94b1&pf_rd_r=BMDRYPWSQ8BK0T38TWB2&pf_rd_s=center-1&pf_rd_t=15506&pf_rd_i=top&ref_=chttp_tt_1']
str1 = ''.join(title_url)
title = str1.split("/")[2] #prints tt0111161 -movie title
- Next step is to send this tiltle to some method to get the main cast to this movie
Task-2 : Get the main casts for the given movie title
- create a file
ImdbCastScrapper.py - Define a function as below
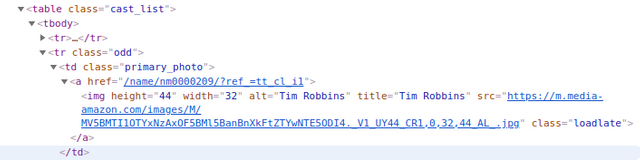
def getCast(titleid):
casts =[]
page = requests.get('https://www.imdb.com/title/'+titleid+'/')
tree = html.fromstring(page.content)
Casts = tree.xpath('//table[@class="cast_list"]/tr/td[@class="primary_photo"]') # [<Element td at 0x7fee28ed97e0>, <Element td at 0x7fee28ed9838>,....]
for i in Casts:
name = ''.join(i.xpath('./a/img/@alt')) # Tim Robbins
casts.append(name)
return casts;
this method will return the casts for the given title
- Now we will have
MoviesCast[]andactors[]array values which hold the casts in every movie and actors name respectively.
Task-2.1 : Import getCast(titleid) method in ImdbTitleScrapper.py
Importing
getCastmethod at topfrom ImdbCastScrapper import getCastAdd these lines of code in
forloop ofMoviesListfor i in MoviesList: ... ... movieCast = getCast(title) actors.append(movieCast) moviesCast.append(','.join(movieCast))Now we will have
MoviesCast[]andactors[]array values which hold the casts in every movie and actors name respectively.actors[]have actually contains a list of array like below, so we need to flatten this to a single list of actors.[ ['Jhon','Robert','wil'], # cast from movie 1 ['Eddey','Robert','smith'], # casts from movie 2 ... ]Use the following code to merge the arrays together
merged = list(itertools.chain(*actors))After this code execution you will have list like below
['Jhon','Rober','Wil','Eddey','Robert','smith']You may notice duplicate names of actors in
actors[]because some actors might act in multiple movies but we want thisactors[]array to be a unique list of actorsuniqueActors = set(merged)
Task-3: Saving the Actors and cast to csv files
_
# Saving actos uniqe list
with open('actors.csv','wb+') as file:
for line in uniqueActors:
file.write(line)
file.write('\n')
file.close()
# Saving MovieCasts uniqe list
with open('MoviesCast.csv','wb+') as file1:
for line in moviesCast:
file1.write(line)
file1.write('\n')
file1.close()
Data Transformation
Language : Scala
Tools/lib : Apache Spark
Transformation is an important task in bigdata world because the data which we get may not be in correctly formatted or unwanted data, also have some noise in it.Some might have structured data like oracleDB,sql databases,semi-structured data like JSON,CSV,XML formats. Both the semi and structured data represents 5-10 % of the data available. You got now! unstructured data eating the world with 90-95% share in the data world. Some examples of unstructured data are like audio, video files and log files, End Of Thinking Capacity ....
Now let me introduce to you Apache Spark, I am not going to copy paste what official page says here instead give you link to refer Apache_spark.
I have been working since 2 years on it, I love the way how it simplified to run the same piece of code perfectly on both standalone(your laptop) and in a cluster, the rich APIs it provides, Higher-order functions, multiple language support( of course it’s a framework though).
Task 1 : Spark installtion and setup
Start with downloading apache spark software from download page , just go with the default options. There are several ways to develop spark application using eclipse-maven,sbt tools scala Ide+maven , Sbt+Intellij , Eclipse+java8 but without much setup for this tutorial we will use the spark-shell to load the scala file in terminal and run the code.
Make sure you have java installed, if not use this to install
sudo apt-get install openjdk-8-jre
After you extract the spark-2.x.x-bin-hadoop2.7 folder,navigate to bin folder ,open terminal and type this following command ./spark-shell [enter]
Task 2 : Create csv file which holds all possible combinations for every actor in a movie
Our main theme is to build relations among artists/actors and find who holds more connections and how each other connected to others.
In MoviesCast.csv file, we have a list of actors in every movie separated by new line.
Tim Robbins,Morgan Freeman,Bob Gunton,William Sadler,Clancy Brown,Gil Bellows,Mark Rolston,James Whitmore,Jeffrey DeMunn,Larry Brandenburg,Neil Giuntoli,Brian Libby,David Proval,Joseph Ragno,Jude Ciccolella
Marlon Brando,Al Pacino,James Caan,Richard S. Castellano,Robert Duvall,Sterling Hayden,John Marley,Richard Conte,Al Lettieri,Diane Keaton,Abe Vigoda,Talia Shire,Gianni Russo,John Cazale,Rudy Bond
Given the input of actors, we need to create each possible pairs of actors, which represents the relation between them
for example MoviesCast.csv consider below example
a,b,c,d // actors in movie 1
c,d,g,h // actors in movie 2
our apache spark transformation code snippet will produce out as below
a,b
a,c
a,d
b,c
b,a
...
...
...
h,g
first column is src , and second is dst
Here we considered two way relations means if a knows b then b also knows a.
Transformer.scala
import scala.math.random
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark._
//import com.databricks.spark.csv
import org.apache.spark.sql.functions._
import sqlContext.implicits._
object Transformer {
def main(args: Array[String]) {
// Input file is MoviesCast.csv
var CastsFile = sc.textFile("<path_wher_you_saved_>/MoviesCast.csv");
val df_ = CastsFile.map(f => {
val splitArr = f.split(",") // reading line and splitting with ','
val _Tuple_pair = for( a <- splitArr ; b <- splitArr ;if(a != b) ) yield(a,b)
//(a,b),(a,c),(a,d)......(g,a)...
_Tuple_pair //returning tuple pairs of possible combination
})
.flatMap(f => f);
val relationsDF = spark.createDataFrame(df_).toDF("src","dst");
relationsDF.coalesce(1).write.format("com.databricks.spark.csv").save("<Path_to_save>/Relations.csv")
}
}
// scalastyle:on println
Well that's a lot of code let me walk through it, apart from imports
- we created
Transformerscala object scstands forsparkContext.using that object we loaded file usingtextFile(path)method.- loading a file will create the
rdd(which is a core abstraction of apache spark).Rdds are immutable,distributed and fault tolerant. - On that created rdd
CastFilewe putmapon it and iterate over every line.as the data is,delimited we split with,and build an array from it which holds entire cast in that movie. for( a <- splitArr ; b <- splitArr ;if(a != b) ) yield(a,b)is a one-liner for creating possible pairs in a given array- After the map operation, we will have a list of arrays of tuples like below
[[(a,b)(c,d)],[(e,g),(f.h)]] - For flattening this,
flatMapwill return the flattened tuples[(a,b)(c,d)(e,g)(f,h)] - The last section of the code involves creating a dataframe and saving to a file system as
Relations.csvfile.
Task 3 : Loading and executing scala file from spark-shell
Use this command to load scala file
:load <path_to_scala>/Transformer.scala
Inorder to execute the code run this command
Transformer.main(null)
After calling the above method a folder will be created with name Relations.csv.Which holds the all possible relations for every actor.
you can find the source code for DATA EXTRACTION , DATA TRANSFORMATION , DATA
In the next tutorial, we will use this Relations.csv data to build a graphFrame.Using this graphFrame we will easily calculate PageRank and BFS.
Curriculum
This is the first tutorial
Thank you for your contribution @yashwanthkambala.
After reviewing your tutorial we suggest the following points listed below:
Nice work on the explanations of your code, although adding a bit more comments to the code can be helpful as well.
We suggest that you put more screenshots of the results you will get during your tutorial.
The structure of your tutorial is a bit confusing. In your next tutorial try to improve the structure of your tutorial so readers have a better reading of your contribution.
Thank you for your work in developing this tutorial.
Looking forward to your upcoming tutorials.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Thank you I included more topics in single post ,so that might confuse a bit.I will improve what you suggested
Thank you for your review, @portugalcoin! Keep up the good work!
Hi @yashwanthkambala!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @yashwanthkambala!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!