[EN/DE] Meltdown & Spectre - The inner workings (Part 1: Basics)

[EN] Basics
Introduction
In this series, I want to cover the exploits nearly everyone heard of by now, Meltdown and Spectre. Most people know, that you are to get passwords and other hidden data by using them. But I want to give a little more detail on what exactly Meltdown and Spectre do, and how they obtain such data. I will try to keep it as simple as possible, so even someone who is not familiar with how processors work exactly should be able to follow. In case something is unclear, feel free to ask me in the comments! Before we start talking about Meltdown in the next post, we need to introduce and explain some terms.
Memory Isolation
Memory isolation is a security feature, used by most modern CPUs. It makes sure, that processes are not able to access each others memory. If a random program could read all your memory for example, it could see all stored passwords.
To make sure a process only accesses memory it is allowed to access, it only uses virtual memory. All virtual memory addresses are mapped to physical memory addresses.
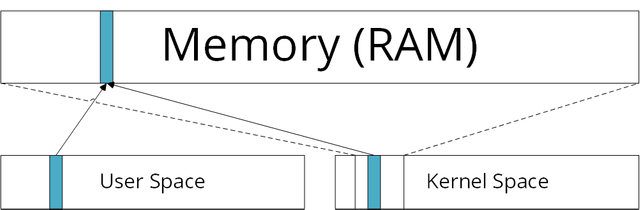
However, all physical memory is mapped in the kernel space (the kernel is the central piece of your operating system, so it needs access to everything, and the kernel space is the memory location where this kernel lies) at a certain offset. The image shows how all the things programs can access (user space) are also mapped into the kernel space. So if you can read everything in the kernel space, you can also ready everything in the user space. This is later used by Meltdown.
Also, the Flush+Reload attack described later uses a feature called memory sharing, where (read-only) memory is shared between two processes when the content is the same. That way a shared library doesn't exist twice in your memory for example.
Out-of-order execution
This is one of the most important things this attack relies one. Let's first look at in-order-execution. A program is divided into different instructions like "move the content of register A to register B". A register is an enormously fast storage, directly connected to the CPU, which is used to store temporary values the CPU works with. Let's assume we have the following instructions:
1. LOAD A, SomeLocation
2. ADD A, B
3. MOVE B, 5
4. ADD B, 10
We load the value stored in SomeLocation into register A, then we add the (in this example unknown) value of B to A (and store it in A). Then we set the value of B to 5 and finally we add 10 to the value of B and store it in B.
A processor using in-order-execution would do exactly that, but there is a possible performance problem here. Once the LOAD operation is called, the processor searches for the value of SomeLocation in it's caches. The processor cache is slower than the registers and usually divided into three levels (L1 cache, L2 cache, L3 cache), L1 being the fastest and smallest one and L3 being the biggest and slowest one. Slow means slow compared to a register but extremely fast compared to RAM. So if the processor can't find the value of SomeLocation in one of the caches (let's assume it can't), it needs to load it from the RAM. If you're a processor, RAM is preeetty slow, so this takes a long time. A large number of instructions could have been executed, while the processor is waiting for the value from the RAM.
So, how to avoid this? The answer is out-of-order execution. Since line 1,2 and 3,4 are independent of each other, the processor is smart and executes them in parallel. Internally B is renamed so the correct value is added to A in the second line. This means the processor is constantly looking for stuff he can already execute while he would normally be waiting.
Flush+Reload attack
We already said, that it takes the processor a pretty long time to load things from RAM. And you know what, we can use that knowledge to secretly communicate with another process!
But, how? Let's say we have two programs which share 1 byte (8 bits) of memory, so it will look like 00000000 when filled with zeros. It is important that the memory is shared, otherwise both processes wouldn't be able to read from it at the same time. Now one process (let's call it the "sender") secretly wants to tell another process (let's call this one the "receiver") a secret number from 1 to 8. Let's say our secret number is 4. The receiver now flushes our shared memory location, so it is removed from all cache levels. The only place left where these values are stored is the main memory (RAM).
Our sender on the other hand reads the bit located at location 4 so that the CPU loads the value from the RAM (since it is not cached anymore) and hands it over to the application. The important part is, that the bit at location 4 is now automatically cached again.
This is great news for our receiver application. It will load all the 8 values while recording how much time the process of loading the value takes for each one. The time taken to load all the values except the fourth one will be quite long, since they need to be loaded from the main memory. The loading time for the fourth value however is pretty short, so we know that this is the value our sender accessed.
Why is this useful? It creates a so called "covert channel", a communication channel between two or more applications, undetected by the system. These kinds of attacks are called side-channel attacks because they abuse behaviours of programs/algorithms that depend on the physical implementation. That means cache-accesses, noise, electromagnetic fields and much more.
References
- Yarom Y. and Falkner K. FLUSH+RELOAD: a high resolution, low noise, L3 cache side-channel attack. (San Diego, CA, August 20 - 22, 2014)
- Lipp, M., Schwarz, M., Gruss, D., Prescher, T., Haas, W., Mangard, S., Kocher, P., Genkin, D., Yarom, Y., Hamburg, M. Meltdown. (2018)
[DE] Grundlegendes
Einführung
In dieser Serie möchte ich die beiden Schwachstellen beleuchten, von denen mittlerweile wahrscheinlich jeder schonmal gehört hat. Die meisten wissen, dass man mit diesen in der Lage ist, Passwörter oder ähnliches zu stehlen. Ich werde versuchen, das Ganze so simpel wie möglich zu halten, das heißt selbst jemand der nicht genau weiß, wie Prozessoren funktionieren sollte in der Lage sein zu folgen. Falls etwas unklar ist können Fragen gerne in den Kommentaren gestellt werden! Bevor wir im nächsten Post konkret über Meltdown sprechen, müssen wir hier erst einmal einige Begriffe einführen und erklären.
Memory Isolation
Memory isolation ist ein Sicherheitsfeature, welches von den meisten modernen CPUs genutzt wird. Es sorgt dafür, dass Prozesse nicht in der Lage sind, auf den Speicher anderer Prozesse zuzugreifen. Das ist wichtig, denn wenn irgendein Programm den Speicher von jedem anderen Programm lesen könnte, dann wäre es zum Beispiel in der Lage alle gespeicherten Passwörter auszulesen.
Um sicherzugehen, dass ein Prozess nur auf Speicher zugreifen kann, auf den er zugreifen darf arbeitet er mit virtuellem Speicher. Jeder virtuellen Speicheraddresse ist eine physikalische, also einen tatsächliche, Speicheraddresse zugewiesen.
Allerdings ist der gesamte physikalische Speicher in einem bestimmten Teil des kernel space, also dem Speicher in dem der gesamte Kernel liegt, verlinkt (der Kernel ist der zentrale Bestandteil des Betriebssystems, das heißt er muss auf alles zugreifen können). Das Bild zeigt, wie alle Dinge auf die die Programme zugreifen (user space) auch im kernel space vorhanden sind. Das heißt, wenn alles im kernel space gelesen werden kann, dann kann auch alles im user space gelesen werden. Dies wird später von Meltdown ausgenutzt.
Außerdem nutzt die Flush+Reload Attacke, welche später beschrieben wird ein Feature namens memory sharing, in dem (read-only) Speicher zwischen zwei Prozessen geteilt wird, wenn er den selben Inhalt hat. So existieren zum Beispiel shared librarys nicht zweimal im Speicher.
Out-of-order execution
Die out-of-order execution ist eins der wichtigsten Dinge, auf denen diese Attacke basiert. Aber schauen wir uns erst einmal in-order-execution an. Ein Programm ist in verschiedene Anweisunen unterteilt, wie "bewege den Inhalt von Register A nach Register B". Ein Register ist ein extrem schneller Speicher, welcher direkt mit der CPU verbunden ist. Diesen nutzt die CPU um temporär Daten zu speichern, mit denen sie gerade arbeitet. Nehmen wir mal an, wir haben die folgende Anweisung:
1. LOAD A, SomeLocation
2. ADD A, B
3. MOVE B, 5
4. ADD B, 10
Wir setzen in Zeile 1 den Inhalt von Register A auf den Wert von SomeLocation (irgendein Bereich im Speicher), dann addieren wir in Zeile 2 einen (in diesem Beispiel unbekannten) Wert aus Register B zum Wert von Register A und speichern ihn in Register A. Dann setzen wir den Wert von Register B auf 5, und schließlich addieren wir 10 zum Wert von Register B und speichern ihn in Register B.
Ein Prozessor, welcher in-order-execution nutzt würde genau das tun, allerdings kommt hier ein mögliches Performaneproblem auf. Nachdem die LOAD-Operation aufgerufen wurde, sucht der Prozessor nach dem Wert von SomeLocation in seinen Caches. Der Prozessor-Cache ist langsamer als die Register und meist in drei Level unterteilt (L1 cache, L2 cache, L3 cache). L1 cache ist der schnellste und kleinste, L3 cache der größte und langsamste. Langsam bedeutet hierbei langsam im Vergleich zu Registern, aber unglaublich schnell im Vergleich zu RAM. Das heißt wenn der Prozessor den Wert von SomeLocation nicth in seinen Caches finden kann, dann muss er ihn vom RAM laden. Wenn man ein Prozessor ist, dann ist RAM verdammt langsam, das heißt dies wird eine ganze Weile dauern. Eine große Anzahl an Anweisungen hätte ausgeführt werden können, während der Prozessor darauf wartet, dass dieser Wert geladen wird.
Wie kann das verhindert werden? Die Antwort ist out-of-order execution. Da Zeile 1,2 und Zeile 3,4 unabhängig voneinander sind ist der Prozessor clever und führt sie parallel aus. Intern wird B dann in Zeile 3 und 4 umbenannt, damit in der zweiten Zeile der korrekte Wert zu A hinzugefügt wird. Das heißt, dass der Prozessor dauernd auf der Suche nach Operation ist, die er ausführen kann während er eigentlich warten würde.
Flush+Reload Attacke
Wir haben bereits festegestellt, dass der Prozessor eine ziemlich lange Zeitspanne benötigt, um Dinge aus dem RAM zu laden. Diese kann man nutzen, um heimlich mit einem anderen Prozess zu kommunizieren!
Aber wie? Nehmen wir mal an wir haben zwei Programme, welche 1 byte (8 bit) an Speicher teilen, das heißt wenn dieser mit Nullen gefüllt wäre sähe er aus wie 00000000. Es ist allerdings unwichtig, was genau in diesem Speicher drinsteht. Es ist nur wichtig, dass dieser Speicherbereich geteilt ist, sonst könnten nicht beide Prozesse gleichzeitig davon lesen. Ein Prozess (wir nennen ihn mal den "Sender") möchte nun einem anderen Prozess (nennen wir ihn den "Empfänger") heimlich eine Zahl zwischen 1 und 8 zukommen lassen. Nehmen wir mal an, dass die geheime Zahl 4 ist. Der Sender löscht nun den Speicher an der geteilten Speicheraddresse, so dass er von allen Cache-Levels entfernt wird. Der einzige Platz, an dem diese Werte jetzt noch gespeichert sind ist der Hauptspeicher (RAM).
Die Sender-Anwendung ruft nun den Bit ab, der an Position 4 gespeichert ist. Das führt dazu, dass die die CPU den Wert aus dem RAM lädt (da er nicht mehr im Cache vorhanden ist) und an die Anwendung übergibt. Der wichtige Teil ist, dass dieser Bit an Position 4 nun wieder im Cache vorhanden ist.
Das sind ziemlich gute Nachrichten für unsere Empfängeranwendung. Diese wird nun alle 8 Werte laden, während sie aufnimmt, wie lange der Ladevorgang für jeden Wert dauert. Die Zeit, die gebraucht wird um alle Werte außer dem vierten zu laden ist ziemlich lang, da diese erst vom RAM geladen werden müssen. Der vierte Wert ist schon im Cache vorhanden, deshalb ist die Ladezeit für diesen ziemlich kurz. Daher wissen wir, dass dies der Wert ist, auf welchen unser Sender zugegriffen hat, und somit auch unsere geheime Zahl.
Warum ist das nützlich? Dadurch wird ein sogannter "covert channel", ein Kommunikationskanal zwischen zwei oder mehr Anwendungen erstellt, welcher vom System nicht beobachtet oder kontrolliert werden kann. Diese Typen von Attacken heißen "side channel"-Attacken, da sie das Nebenverhalten der Implementation eines Programms/Algorithmus missbrauchen. Also Cache-Zugriffe, Geräusche, Elektromagnetische Felder und viele mehr.
Referenzen
- Yarom Y. and Falkner K. FLUSH+RELOAD: a high resolution, low noise, L3 cache side-channel attack. (San Diego, CA, August 20 - 22, 2014)
- Lipp, M., Schwarz, M., Gruss, D., Prescher, T., Haas, W., Mangard, S., Kocher, P., Genkin, D., Yarom, Y., Hamburg, M. Meltdown. (2018)
Thank you! That was very informative. My brain is about to explode but I feel like I’ve learned something very important :)
Yeah, heh, it can be a bit tricky to understand. But I think it's also pretty interesting, I personally didn't know about Flush+Reload before and I think it's pretty smart.
Cool explanation about Spectre and Meltdown in multiple languages! Extremely timely info!
Thank you!
Great post, this reminds me of studying microprocessor systems in college, good refresher. Waiting on part 2.
Thanks!
Mind Blown!
This is a seriously valuable piece of insight belying great technical understanding. If you have an affinity for hardware even more so. Followed!
Thank you! Working on part 2 and 3 right now. :)
Thank you, very informative. I'm waiting for part 2 :).
Thanks. :D Part 2 should come at the end of or during this week.